SQL 構文リファレンス
以下のトピックでは、Zen でサポートされる SQL 構文について説明します。
• リテラル値
• 文法要素の定義
• グローバル変数
• ほかの特性
リテラル値
Zen は、標準のリテラル書式をサポートしています。このトピックでは、最も一般的な例をいくつか示します。
• 文字列値
• 数値
• 日付値
• 時刻値
• タイムスタンプ値
文字列値
文字列定数は、指定する文字列を一重引用符で囲むことによって、SQL ステートメント内に表記できます。文字列自体が一重引用符またはアポストロフィを含んでいる場合は、その文字の前にもう 1 つ一重引用符を付ける必要があります。
文字列リテラルは VARCHAR 型を持ちます。文字は、データベース コード ページを使用してエンコードされます。リテラルの先頭に文字 "N" が付いている場合、そのリテラルは NVARCHAR 型を持ち、文字は UCS-2 を使用してエンコードされます。SQL クエリ文字列に埋め込まれたリテラルは、SQL エンジンで最終的に変換する前に、SQL アクセス方法で追加のエンコード変換の手続きを踏むことがあります。特に、SQL テキストがすべての Unicode 文字をサポートしていないエンコードに変換されている場合は、エンジンが文字列リテラルを NVARCHAR へ変換する前に、SQL テキスト内の文字が失われることがあります。
例
最初の例では、文字列内に含まれるアポストロフィまたは一重引用符は、もう 1 つの一重引用符によってエスケープする必要があります。
SELECT * FROM t1 WHERE c1 = 'Roberta''s Restaurant'
SELECT STREET FROM address WHERE city LIKE 'san%'
数値
日付値
日付定数は、SQL ステートメント内に文字列として表記するか、ベンダー文字列に埋め込むことができます。最初のケースは CHAR 型の文字列として、ベンダー文字列表記は DATE 型の値として扱われます。この違いは変換時に重要になります。
Zen では、この関数で概説しているように、拡張 SQL 文法を一部サポートしています。
Zen でサポートしている日付リテラル書式は 'YYYY-MM-DD' です。
日付は 0 年から 9999 年の範囲で指定できます。
例
次の 2 つのステートメントによって、開始日が 1995 年 6 月 5 日より後のすべての授業が返されます。
SELECT * FROM Class WHERE Start_Date > '1995-06-05'
SELECT * FROM Class WHERE Start_Date > {d '1995-06-05'}
時刻値
Zen でサポートしている時刻リテラル書式は 'HH:MM:SS' です。
時刻定数は、SQL ステートメント内に文字列として表記するか、ベンダー文字列に埋め込むことができます。文字列表記は CHAR 型の文字列として、ベンダー文字列表記は TIME 型の値として扱われます。
Zen では、この関数で概説しているように、拡張 SQL 文法を一部サポートしています。
例
次の 2 つのステートメントによって、Class テーブルから、授業の開始時刻が 14:00:00 のレコードが取り出されます。
SELECT * FROM Class WHERE Start_time = '14:00:00'
SELECT * FROM Class WHERE Start_time = {t '14:00:00'}
タイムスタンプ値
タイムスタンプ定数は、SQL ステートメント内に文字列として表記するか、ベンダー文字列に埋め込むことができます。Zen では、文字列表記は CHAR 型の文字列として、ベンダー文字列表記は SQL_TIMESTAMP 型の値として扱われます。
Zen でサポートしているタイムスタンプ リテラル書式は 'YYYY-MM-DD HH:MM:SS.MMM' です。
例
次の 2 つのステートメントによって、Billing テーブルから、ログの開始日時が 1996-03-28 の 17:40:49 のレコードが取り出されます。
SELECT * FROM Billing WHERE log = '1996-03-28 17:40:49'
SELECT * FROM Billing WHERE log = {ts '1996-03-28 17:40:49'}
Zen の SQL 文法
以下のトピックでは、Zen でサポートされる SQL 文法について説明します。ステートメントおよびキーワードがアルファベット順に記載されています。
メモ: ほとんどの SQL 例は、Zen Control Center に備わっている SQL Editor を使ってテストすることができます。例外については、文法要素の解説に示されています。詳細については、『Zen User's Guide』のSQL Editorを参照してください。
メモ: よく使われる SQL エディターのほとんどは、複数のステートメントを実行するためにステートメント区切り文字を使用しません。しかし、ZenCC の SQL Editor は区切り文字を必要とします。ほかの環境で例を実行する場合は、シャープ記号またはセミコロンの区切り文字を取り除く必要があります。
ADD
備考
ADD 句は ALTER TABLE ステートメント内で使用し、追加する列の定義、列の制約、またはテーブルの制約を 1 つまたは複数指定します。
関連項目
ALL
備考
サブクエリの前に ALL キーワードを指定すると、Zen はサブクエリを実行し、その結果を使用して外部クエリの条件を評価します。サブクエリが返すすべての行が、特定の行に対する外部クエリの条件を満たす場合、Zen はステートメントの最終的な結果テーブルにその行を含みます。
一般に、ALL の代わりに EXISTS キーワードまたは NOT EXISTS キーワードを使用できます。
例
次の SELECT ステートメントは、Person テーブルの ID 列と、サブクエリの結果テーブルの ID 列を比較します。
SELECT p.ID, p.Last_Name
FROM Person p
WHERE p.ID <> ALL
(SELECT f.ID FROM Faculty f WHERE f.Dept_Name = 'Chemistry')
Person テーブルの ID 値と一致する値がサブクエリの結果テーブルの ID 値にない場合、Zen はステートメントの最終的な結果テーブルに Person テーブルの行を含みます。
関連項目
ALTER(名前変更)
ALTER(名前変更)ステートメントにより、インデックス、ユーザー定義関数、ストアド プロシージャ、テーブル、トリガー、またはビューの名前を変更できます。
構文
ALTER オブジェクトの種類 RENAME 修飾されたオブジェクト名 TO 新しいオブジェクト名
オブジェクトの種類 ::= INDEX
| FUNCTION
| PROCEDURE
| TABLE
| TRIGGER
| VIEW
修飾されたオブジェクト名 ::= データベース名.テーブル名.オブジェクト名
| データベース名.オブジェクト名
| テーブル名.オブジェクト名
| オブジェクト名
データベース名, テーブル名, オブジェクト名, 新しいオブジェクト名 ::= ユーザー定義名
備考
以下のオブジェクトは、PSQL v9 より前のバージョンの Zen で作成されている場合には、名前を変更できません。
• ストアド プロシージャ
• トリガー
• ビュー
以前のリリースでは、これらのオブジェクトの名前によるシステム テーブルのインデックスは変更不可として作成されました。これらのオブジェクトのインデックスが変更可能になったのは PSQL v9 からです。
どのオブジェクトの種類もデータベース名を使って修飾できます。ただし、INDEX または TRIGGER オブジェクトを修飾する場合は、テーブル名も含める必要があります。テーブル名は、INDEX および TRIGGER オブジェクトを修飾する場合にのみ使用できます。
ALTER ステートメントで、データベース内のオブジェクトの名前を変更することができます。変更するオブジェクトが、現在セッションが接続されていないデータベース内にある場合は、データベース名を使ってオブジェクトの種類を修飾する必要があります。名前変更されたオブジェクトは、同一データベース内にデータベース名として現れます。
修飾子のデータベース名を省略すると、現在セッションが接続されているデータベースを基にオブジェクトが識別され、名前が変更されます。
新しいオブジェクト名の修飾子にデータベース名を使用してはいけません。注意してください。新しい名前のコンテキストは、元の名前のコンテキストと常に一致させます。
メモ: データベース エンジンは、名前変更されたオブジェクトの依存関係をチェックしません。以前の名前で依存関係が設定されているすべてのオブジェクトを必要に応じて修正してください。たとえば、あるトリガーが t1 という名前のテーブルを参照しているとします。テーブル t1 の名前を t5 に変更すると、トリガーには無効な SQL が含まれていることになり、トリガーは失敗します。
オブジェクトの名前は、psp_rename システム ストアド プロシージャを使用して変更することもできます。
例
次のステートメントは、現在セッションが接続されているデータベースにあるインデックス suplid の名前を vendor_id へ変更します。インデックスが適用されているテーブルは region5 です。
ALTER INDEX RENAME region5.suplid TO vendor_id
次のステートメントは、データベース foodforlife にあるユーザー定義関数 calbrned の名前を caloriesburned へ変更します。
ALTER FUNCTION RENAME foodforlife.calbrned TO caloriesburned
次のステートメントは、データベース international にあるストアド プロシージャ checkstatus の名前を isEligible へ変更します。
ALTER PROCEDURE RENAME international.checkstatus TO isEligible
次のステートメントは、現在セッションが接続されているデータベースにあるテーブル payouts の名前を accts_payable へ変更します。
ALTER TABLE RENAME payouts TO accts_payable
次のステートメントは、データベース electronics のテーブル domestic にあるトリガー testtrig3 の名前を new_customer へ変更します。
ALTER TRIGGER RENAME electronics.domestic.testtrig3 TO new_customer
次のステートメントは、現在セッションが接続されているデータベースにあるビュー suplrcds の名前を vendor_codes へ変更します。
ALTER VIEW RENAME suplrcds TO vendor_codes
関連項目
ALTER GROUP
ALTER GROUP ステートメントは、ユーザーをグループに追加またはグループから削除します。
構文
ALTER GROUP グループ名
< ADD USER ユーザー名 [ , ユーザー名 ]...
| DROP USER ユーザー名 [ , ユーザー名 ]... >
備考
Master ユーザーのみがこのステートメントを実行できます。
このステートメントは、使用可能な 2 つのキーワードのいずれかと共に使用する必要があります。
ユーザー アカウントをグループに追加するには、そのグループが既にデータベース内に作成済みである必要があります。ユーザーを作成して同時にグループに追加する方法は、GRANT を参照してください。
グループからユーザー アカウントを削除しても、そのグループはデータベースから削除されません。
ユーザー アカウントは、同時に複数のグループに所属することはできません。現在あるグループのメンバーであるユーザー アカウントを別のグループに追加することはできません。そのようなユーザー アカウントの場合、まず現在のグループから削除し、次に別のグループに追加します。
空白や非英数文字を含むユーザー名は二重引用符で囲む必要があります。
ユーザーとグループの詳細については、『Advanced Operations Guide』の Master ユーザー、ユーザーとグループ、および『Zen User's Guide』の権限の割り当て作業を参照してください。
例
以下の例は、ユーザー アカウントをグループに追加する方法を示します。
ALTER GROUP developers ADD USER pgranger
既存のユーザー アカウント pgranger が、既存のグループ developers に追加されます。
————————
ALTER GROUP developers ADD USER "polly granger"
ユーザー アカウント polly granger(非英数文字を含む)が、グループ developers に追加されます。
————————
ALTER GROUP developers ADD USER "polly granger", bflat
ユーザー アカウント polly granger(非英数文字を含む)および bflat は、グループ developers に追加されます。
————————
以下の例は、グループからユーザー アカウントを削除する方法を示します。
ALTER GROUP developers DROP USER pgranger
ユーザー アカウント pgranger が、グループ developers から削除されます。
————————
ALTER GROUP developers DROP USER "polly granger"
ユーザー アカウント polly granger(非英数文字を含まない名前)が、グループ developers から削除されます。
————————
ALTER GROUP developers DROP USER "polly granger", bflat
ユーザー アカウント polly granger(非英数文字を含む)および bflat は、グループ developers から削除されます。
関連項目
ALTER TABLE
ALTER TABLE ステートメントにより、テーブル定義を変更します。ALTER TABLE を使用して列を変更した場合、既存の列定義に追加されるのではなく、新しい定義に置き換えられることに留意してください。
構文
ALTER TABLE テーブル名 [ IN DICTIONARY ]
[ USING 'パス名'] [ WITH REPLACE ] 変更オプション
テーブル名 ::= ユーザー定義名
パス名 ::= ファイル名のみ、または相対パスとファイル名
変更オプション ::= 変更オプション-リスト1 | 変更オプション-リスト2
変更オプション-リスト1 ::= 変更オプション | (変更オプション [ , 変更オプション ]... )
| ADD テーブル制約定義
| ALTER [ COLUMN ] 列定義
| DROP [ COLUMN ] 列名
| DROP CONSTRAINT 制約名
| MODIFY [ COLUMN ] 列定義
変更オプション-リスト2 ::= PSQL_MOVE [ COLUMN ] 列名 TO [ [ PSQL_PHYSICAL ] PSQL_POSITION ] 新しい列位置 | RENAME COLUMN 列名 TO 新しい列名
列名 ::= ユーザー定義名
新しい列位置 ::= 新しい位置を表す序数値(正の整数値)。値は、0 より大きく、テーブル内の列の総数以下でなければなりません。
新しい列名 ::= ユーザー定義名
桁数 ::= 整数
小数位 ::= 整数
デフォルト値の式 ::= デフォルト値の式 + デフォルト値の式
| デフォルト値の式 - デフォルト値の式
| デフォルト値の式 * デフォルト値の式
| デフォルト値の式 / デフォルト値の式
| デフォルト値の式 & デフォルト値の式
| デフォルト値の式 | デフォルト値の式
| デフォルト値の式 ^ デフォルト値の式
| ( デフォルト値の式 )
| -デフォルト値の式
| +デフォルト値の式
| ~デフォルト値の式
| ?
| リテラル
| スカラー関数
| { fn スカラー関数 }
| USER
| NULL
デフォルトのリテラル ::= '文字列' | N'文字列'
| 数字
| { d '日付リテラル' }
| { t '時刻リテラル' }
| { ts 'タイムスタンプ リテラル' }
デフォルトのスカラー関数 ::= USER()
| NULL()
| NOW()
列制約定義 ::= [ CONSTRAINT 制約名 ] 列制約
制約名 ::= ユーザー定義名
列制約 ::= NOT NULL
| NOT MODIFIABLE
| UNIQUE
| REFERENCES テーブル名 [ ( 列名 ) ] [ 参照アクション ]
参照アクション ::= 参照更新アクション [ 参照削除アクション ]
| 参照削除アクション [ 参照更新アクション ]
照合順序名 ::= '文字列'
テーブル制約定義 ::= [ CONSTRAINT 制約名 ] テーブル制約
REFERENCES テーブル名
[ ( 列名 [ , 列名 ]... ) ]
[ 参照アクション ]
備考
主キーおよび外部キーと参照整合性に関する情報については、CREATE TABLE を参照してください。
CHAR、VARCHAR、または LONGVARCHAR と、NCHAR、NVARCHAR、または NLONGVARCHAR とにおける変換では、CHAR 値はデータベース コード ページを使用してエンコードされていることを前提とします。LONGVARCHAR 型の列を NLONGVARCHAR 型に変更することも、NLONGVARCHAR 型を LONGVARCHAR 型に変更することもできません。
ALTER TABLE では、テーブルが排他ロックされている必要があります。別のステートメントにより同じテーブルが開いていると、ALTER TABLE は失敗してステータス コード 88 を返します。データ操作ステートメントを実行する前に、すべてのデータ定義ステートメントを実行しておいてください。これを示す例は、PSQL_MOVE を参照してください。
SYSDATA_KEY_2 キーワードを指定した ALTER TABLE ステートメントでは、ファイルが 13.0 より前の形式である場合には自動的に 13.0 に変更されます。その後、システム データ v2 が追加され、仮想列 sys$create および sys$update をクエリで使用できるようになります。詳細については、システム データ v2 のアクセスを参照してください。
SYSDATA_KEY_2 キーワードと一緒に IN DICTIONARY を使用した場合、ALTER TABLE ステートメントは SYSDATA_KEY_2 を無視するため、テーブルの sys$create および sys$update 仮想列は使用できません。
IN DICTIONARY
このキーワードを使用する目的は、基となる物理データは変更しないままで DDF に変更を加えたいことを、データベース エンジンに通知することです。IN DICTIONARY は上級ユーザー向けの強力な機能です。これは、絶対に必要な場合にだけ、システム管理者のみが使用してください。通常、Zen は DDF とデータ ファイルの完全な同期を保ちますが、この機能により、ユーザーは柔軟にテーブルの辞書定義を既存のデータ ファイルに合致させることが可能になります。このキーワードは、既存のデータ ファイルと合致する定義を辞書内に作成したい場合、あるいは USING 句を使ってテーブルのデータ ファイル パス名を変更したい場合に有用です。
IN DICTIONARY をバウンド データベースで使うことはできません。
IN DICTIONARY は ALTER TABLE に加え、CREATE TABLE および DROP TABLE で使用できます。IN DICTIONARY は、どの CREATE/ALTER オプションが指定されていようと、辞書エントリにのみ影響します。Zen では複数のオプション(ADD、DROP、ADD CONSTRAINT などのあらゆる組み合わせ)が許可されることから、IN DICTIONARY は、DDF だけがスキーマの変更によって影響を受けることを保証するために、すべての状況下で優先されます。
デタッチされたテーブルまたは存在しないテーブルを照会すると、"テーブルが見つかりません" というエラーになります。テーブルの存在を確認したにもかかわらず "テーブルが見つかりません" エラーを受け取った場合、このエラーはデータ ファイルを開けなかったことが原因で発生しています。これはデタッチされたテーブルを示します。(DDF のみが存在する(データ ファイルは存在しない)テーブルは、「デタッチされた」エントリと呼ばれます。これらのテーブルには、クエリを介して、また、クエリ以外で基となる物理ファイルを開こうとする操作を介してアクセスできません。
テーブルが実際に存在するかどうかは、カタログ関数(システム カタログ関数を参照)を使用するか、X$File の Xf$Name 列に直接クエリを実行することにより確認できます。
SELECT * FROM X$File WHERE Xf$Name = 'テーブル名'
SELECT ステートメントは Xf$Loc 値を返します。これは、テーブルの物理ファイルの名前です。この名前とデータベースに定義されているデータ パスを組み合わせれば、ファイルの絶対パスを取得できます。
デタッチされたテーブルの場合は混乱を招く可能性があるので、IN DICTIONARY 機能は非常に注意して使用しなければなりません。テーブル定義を物理ファイルと合致させるために使用するものであり、テーブル定義のデタッチに使用してはならないということがきわめて重要です。次の例で、test123.btr ファイルは存在しないと仮定して考えてみましょう(USING は次のサブトピックで説明されています)。
CREATE TABLE t1 USING 't1.btr' (c1 INT)
ALTER TABLE t1 IN DICTIONARY USING 'test123.btr'
または、両方のステートメントを組み合わせると次のようになります。
CREATE TABLE t1 IN DICTIONARY USING 'test123.btr' (c1 INT)
その後 SELECT from t1 を実行すると、テーブルが見つからなかったというエラーが返されます。テーブルを作成しただけであって、どのようにしてもそれを見つけることができないので、混乱が生じることがあります。また、IN DICTIONARY を指定しないでテーブルを DROP しようとすると、同様のエラーが返されます。これらのエラーは、テーブルに関連付けられたデータ ファイルが存在しないことが原因で発生します。
既存の Btrieve データ ファイルに対してリレーショナル インデックス定義を作成する(たとえば、ALTER TABLE ステートメントを発行して IDENTITY 型の列定義を追加する)たびに、Zen はそのファイルに定義されている Btrieve インデックスを自動的にチェックし、既存の Btrieve インデックスがリレーショナル インデックス定義に必要なパラメーターのセットを提供しているかどうかを判定します。既存の Btrieve インデックスと作成する新しい定義が一致する場合は、リレーショナル インデックス定義と既存の Btrieve インデックスの間に関連付けが作成されます。一致するインデックスがない場合は、Zen は新しいインデックス定義を作成し、IN DICTIONARY が指定されていなければ、データ ファイルに新しいインデックスを作成します。
USING
USING キーワードを使用すると、特定のデータ ファイルを CREATE TABLE または ALTER TABLE アクションと関連付けることができます。
Zen は接続に名前付きデータベースを必要とするので、指定するパス名は常に単純なファイル名であるか、または相対パスとファイル名でなければなりません。パスは常に、接続する名前付きデータベースに指定された最初のデータ パスとの相対になります。
渡されたパス名およびファイル名は、ステートメントの準備ができたときに部分的に検証されます。
パス名を指定するときは、次の規則に従う必要があります。
• テキストは、文法定義で示されているように、一重引用符で囲まなければなりません。
• テキストの長さは、X$File の Xf$Loc に収まるよう、メタデータ バージョン 1 の場合は 1 から 64 文字まで、メタデータ バージョン 2 の場合は 1 から 250 文字まででなければなりません。エントリは入力したまま正確に格納されます(ただし、後続の空白は切り捨てられ、無視されます)。
• パスは、単純な相対パスでなければなりません。サーバーまたはボリュームを参照するパスは許可されません。
• 相対パスには、1 つのピリオド("." は現在のディレクトリ)、2 つのピリオド(".." は親ディレクトリ)、円記号("\")、またはこれら 3 つのあらゆる組み合わせを含めることができます。パスは、SQL テーブル名を表すファイル名を含んでいる必要があります(パス名は円記号 "\" またはディレクトリ名で終わってはいけません)。CREATE TABEL または ALTER TABLE を使用してファイルを作成する場合、ファイル名は、相対パス付きで指定されたファイル名も含めてすべて、名前付きデータベースの設定で定義されている最初のデータ パスとの相対にします。(IN DICTIONARY を使用する場合、ファイル名には最初のデータの場所への相対パスを付けません。)
• ルート ベースの相対パスを使用できます。たとえば、最初のデータ パスを D:\mydata\demodata とした場合、Zen は次のステートメント内のパス名を D:\temp\test123.btr と解釈します。
CREATE TABLE t1 USING '\temp\test123.btr' (c1 int)
• 相対パス内の円記号('\')文字は、好みに応じて、Linux スタイル('/')と通常使われる円記号('\')のどちらを指定してもかまいません。必要であれば、2 種類の記号を混在させて使用することもできます。ディレクトリ構造スキーマは知っているかもしれませんが、接続されているサーバーの種類を知っている(あるいは管理している)とは限らないので、これは便利な機能です。パスは入力したとおりに X$File に格納されます。Zen エンジンは、パスを利用してファイルを開く際、円記号文字を適切なプラットフォームのタイプに変換します。また、データ ファイルはサポートされるすべてのプラットフォーム間でバイナリ互換性を共有するため、ディレクトリ構造がプラットフォーム間で同一である(および、パスに基づくファイル名が相対パスで指定されている)限りは、データベース ファイルおよび DDF をこれらに変更を加えることなく、あるプラットフォームから別のプラットフォームへ移動することができます。これは、複数のプラットフォームにまたがって、標準化されたデータベース スキーマをより簡単に配置するのに役立ちます。
• 相対パスを指定する場合、まず USING 句のディレクトリ構造は存在している必要があります。Zen は、USING 句で指定されたパス条件を満たすディレクトリを作成しません。
USING 句を使用して、既存のテーブルと関連付ける既存データ ファイルの物理的場所と名前を指定します。USING 句ではまた、既存の辞書定義を使用して、特定の場所に新しいデータ ファイルを作成することができます(USING 句に指定した文字列は、X$File 辞書ファイルの Xf$Loc 列に格納されます)。新しいファイルを作成するとき、ファイル情報のいくつかを元のデータ ファイルから取得する必要があるので、元のデータ ファイルは使用可能でなければなりません。
Demodata サンプル データベースでは、Person テーブルは PERSON.MKD ファイルと関連付けられています。PERSON2.MKD という名前の新しいファイルを作成すると、次の例のステートメントは、Person テーブルが新しいファイルと関連付けられるように、Person テーブルの辞書定義を変更します。
ALTER TABLE Person IN DICTIONARY USING 'person2.mkd'
USING 句には単純なファイル名か相対パスのいずれかを使用しなければなりません。相対パスを指定した場合、Zen はそのパスを、データベース名と関連付けられている最初のデータ ファイル パスとの相対と解釈します。
USING 句は、ALTER TABLE のほかの標準オプションに加えて指定することができます。これは、USING パスを指定するステートメントと同じステートメント内で列を操作できるということです。
テーブル データを格納するために現在使用しているデータ ファイル名と異なるデータ ファイル名を指定し、IN DICTIONARY を指定しないと、Zen は新しいファイルを作成し、既存ファイルのデータをすべて新規ファイルにコピーします。たとえば、Person テーブルのデータを保持している現在のデータ ファイルは person.mkd であると仮定します。上記のステートメントで示されるように、person2.mkd ファイルを使用するよう Person テーブルを変更します。person.mkd の内容が person2.mkd にコピーされます。そうすると、person2.mkd が Person テーブルと関連付けられたデータ ファイルとなり、データベース操作は person2.mkd に作用します。person.mkd は削除されませんが、データベースにはもう関連付けられなくなります。
データをコピーするのは、Zen では、USING と同時にそれ以外のすべての ALTER TABLE オプションを指定できるためです。作成された新しいデータ ファイルには、既存テーブルのデータが完全に読み込まれる必要があります。ファイル構造は単純にコピーされるのではなく、内容全体が移行されます。これは、Btrieve の BUTIL -CREATE と BUTIL -COPY を実行するのに似ています。このことは、SQL テーブルを再構築したり、以前は多数のレコードを格納していたが現在は少数のレコードしか格納していないファイルを圧縮したりするのに役立ちます。
メモ: ALTER TABLE USING は、既存のデータ ファイルの内容を新しく指定されたデータ ファイルにコピーし、古いデータ ファイルは元のまま、ただしリンクは解除して残しておきます。
WITH REPLACE
WITH REPLACE が USING と共に指定されたときはいつでも、Zen は既存のファイル名を指定されたファイル名で自動的に上書きします。オペレーティング システムがファイルの上書きを許している限り、ファイルは常に上書きされます。
WITH REPLACE はデータ ファイルにのみ作用し、DDF には作用しません。
WITH REPLACE を使用する際には次の規則が適用されます。
• WITH REPLACE は USING と併せてのみ使用できます。
• IN DICTIONARY と一緒に使用すると、WITH REPLACE は無視されます。IN DICTIONARY は DDF にのみ作用することを指定するものだからです。
メモ: ALTER TABLE で WITH REPLACE を使用しても、データは消失したり破棄されたりしません。新しく作成されたデータ ファイルは、既存ファイルを上書きしたファイルであっても、以前のファイルのデータをすべて含んでいます。ALTER TABLE コマンドを使用することで、データを失うことはありません。
Zen に既存ファイル(ファイルは、USING 句で指定された場所になければなりません)を置き換えるよう指示するには、USING 句で WITH REPLACE を使用します。WITH REPLACE を使用すると、Zen は新しいファイルを作成し、既存ファイルのデータをすべて新規ファイルにコピーします。WITH REPLACE を使用していないとき、指定された場所にファイルが存在すると、Zen はステータス コードを返し、新しいファイルを作成しません。ステータス コードはエラー -4940 です。
MODIFY COLUMN と ALTER COLUMN
列のデータ型やヌル値を許可するかどうかを変更する機能は、次の制約を受けます。
• ターゲット列では、PRIMARY/FOREIGN KEY 制約を定義することはできません。
• 旧データ型を新しいデータ型に変換することによって(演算またはサイズの)オーバーフローが発生する場合、ALTER TABLE 操作は中止されます。
• ヌル値を許可する列がヌル値を含む場合、その列をヌル値を許可しない列に変更することはできません。
主キー列または外部キー列のデータ型を変更する必要がある場合は、制約を削除し、列のデータ型を変更してから再び制約を追加することにより実現できます。関連するすべてのキー列の同期がとれているようにしなければならない、ということに留意してください。たとえば、テーブル T1 に主キーがあり、このキーがテーブル T2 および T3 の外部キーによって参照される場合は、まず外部キーを削除しなければなりません。外部キーを削除した後で、主キーを削除することができます。次に、3 つの列をすべて同じデータ型に変更する必要があります。最後に、主キーを再び追加してから、外部キーを追加します。
ANSI 標準には ALTER キーワードが含まれています。Zen では、ALTER TABLE ステートメントで MODIFY キーワードも使用できます。COLUMN キーワードは省略可能です。たとえば、次のようになります。
ALTER TABLE t1 MODIFY c1 INTEGER
ALTER TABLE t1 ALTER c1 INTEGER
ALTER TABLE t1 MODIFY COLUMN c1 INTEGER
ALTER TABLE t1 ALTER COLUMN c1 INTEGER
Zen では、実際のデータが、列の長さを小さくした新しい列でオーバーフローしないのであれば、列の長さを小さくすることができます。この動作は、Microsoft SQL Server の動作に似ています。
1 つの ALTER TABLE ステートメントで、複数の列を追加、削除、または変更することができます。これは操作を簡略化しますが、この動作は ANSI 互換とみなされません。次に、複数列の ALTER ステートメントの例を示します。
ALTER TABLE t1 (ALTER c2 INT, ADD D1 CHAR(20), DROP C4, ALTER C5 LONGVARCHAR, ADD D2 LONGVARCHAR NOT NULL)
旧データ型(Pervasive.SQL v7 以前)を、現在の Zen リリースでサポートされているネイティブなデータ型に変換できます。逆に、新データ型を旧データ型へ変換したい場合は、Zen サポートにお問い合わせください。
NOTE/LVAR 列を持つ古いテーブルに LONGVARCHAR/LONGVARBINARY 列を追加するには、まず、NOTE/LVAR 列を LONGVARCHAR または LONGVARBINARY 列に変換しなければなりません。NOTE/LVAR 列を LONGVARCHAR/LONGVARBINARY に変換したら、テーブルにそれ以外の LONGVARCHAR/LONGVARBINARY 列を追加できます。古いエンジンでは、テーブル当たり 1 つの可変長列しか扱うことができないため、前述の新しいテーブルを使って作業することはできないので注意してください。
PSQL_MOVE
PSQL_MOVE 構文を使用すると、テーブルの列を希望する位置に保持することができます。既存の列や、追加された新しい列の位置を変更したい場合があります。列を論理的および物理的に移動させることができます。
移動の種類 | 結果 |
|---|---|
論理的 | 結果セットにリストされる列の位置は変わりますが、テーブル内の列の物理的順序は変わりません。たとえば、"SELECT * FROM テーブル名" のようなクエリで生成される結果セットにおける列の配置方法を変更できます。論理的移動は、"SELECT * FROM テーブル名" のような、列を列挙するクエリにのみ影響を及ぼします。 |
物理 | 列は、ファイル内の現在位置から新しい位置へ物理的に移動されます。物理的移動は、テーブルのデータ ファイルに影響を及ぼします。列を物理的に移動する場合は、PSQL_PHYSICAL キーワードを指定する必要があります。PSQL_PHYSICAL キーワードを省略すると、デフォルトで論理的移動が生じます。 ALTER TABLE ステートメントで IN DICTIONARY が使用されている場合は、DDF 内の列のオフセットのみが変更されるので注意してください。データ ファイルに対し、MOVE ... PSQL_PHYSICAL より IN DICTIONARY が優先されるため、データ ファイル内の列は物理的に移動されません。 |
メモ: 一度列を論理的に移動したら、その並び順が結果セットにおける列のデフォルトの列挙順になります。たとえば、列を論理的に移動させた後で物理的に移動させた場合、"SELECT * FROM テーブル名" のようなクエリでは、論理順が使用されます。論理的な列の変更は X$Attrib に格納されます。
PSQL_MOVE キーワードには、ゼロより大きく、列の総数よりも小さい値で列の位置を指定する必要があります。たとえば、テーブル t1 には col1 と col2 の 2 つの列だけがあるとします。次のステートメントはどちらもエラーを返します。
ALTER TABLE t1 PSQL_MOVE col1 to 0
ALTER TABLE t1 PSQL_MOVE col1 to 3
最初のステートメントは列を位置 0 へ移動しようとしています。2 番目のステートメントは列を位置 3 へ移動しようとしていますが、これは列の総数である 2 よりも大きい数値です。
ALTER TABLE では、テーブルが排他ロックされている必要があります。別のステートメントにより同じテーブルが開いていると、ALTER TABLE は失敗してステータス コード 88 を返します。データ操作ステートメントを実行する前に、すべてのデータ定義ステートメントを実行しておいてください。
たとえば、次のストアド プロシージャでは、INSERT ステートメントがテーブル t1 を開いていることにより、ALTER TABLE ステートメントが排他ロックを取得できないため、実行が失敗し、ステータス コード 88 が返されます。
CREATE PROCEDURE proc1() AS
BEGIN
CREATE TABLE t1(c1 INT,c2 INT,c3 INT);
INSERT INTO t1 VALUES (123,345,678);
ALTER TABLE t1 PSQL_MOVE c3 to 1;
END;
これを解決する方法は、最初にテーブル作成とデータ挿入に関連するステートメントを実行してから、プロシージャを呼び出すことです。
CREATE TABLE t1(c1 INT,c2 INT,c3 INT);
INSERT INTO t1 VALUES (123,345,678);
CALL proc1;
CREATE PROCEDURE proc1() AS
BEGIN
ALTER TABLE t1 PSQL_MOVE c3 to 1;
END;
RENAME COLUMN
RENAME COLUMN を使用すると、列の名前を別の名前に変更できます。ただし、同じテーブル内の既存の列名に変更することはできません。
列名を変更することにより、以前の名前を参照しているオブジェクトが無効になる場合があります。たとえば、あるトリガーがテーブル t1 の列 c1 を参照しているとします。列名を c1 から c5 に変更すると、トリガーは正常に実行できなくなります。
列の名前を変更する場合、psp_rename システム ストアド プロシージャを使用することもできます。
メモ: データベース エンジンは、名前変更された列の依存関係をチェックしません。列の名前を変更したら、必ず、以前(変更元)の名前で依存関係が設定されているすべてのオブジェクトを適切に修正してください。
ON DELETE CASCADE
CREATE TABLE の削除規則を参照してください。
例
このセクションでは、ALTER TABLE のいくつかの例を示します。
次のステートメントによって、Emergency_Phone 列が Person テーブルに追加されます。
ALTER TABLE person ADD Emergency_Phone NUMERIC(10,0)
次のステートメントによって、col1 と col2 の 2 つの整数列が Class テーブルに追加されます。
ALTER TABLE class(ADD col1 INT, ADD col2 INT)
————————
テーブル定義から列を削除するには、DROP 句内に列の名前を指定します。次のステートメントによって、Emergency_Phone 列が Person テーブルから削除されます。
ALTER TABLE person DROP Emergency_Phone
次のステートメントによって、Class テーブルから col1 と col2 が削除されます。
ALTER TABLE class(DROP col1, DROP col2)
次のステートメントによって、Faculty テーブル内の制約 c1 が削除されます。
ALTER TABLE Faculty(DROP CONSTRAINT c1)
————————
この例では、Class テーブルに整数列 col3 が追加され、列 col2 が削除されます。
ALTER TABLE class(ADD col3 INT, DROP col2 )
————————
次の例では、Faculty テーブル内の ID フィールドに c1 という名前の主キーが作成されます。ヌル値を許可する列には主キーを作成できないことに注意してください。作成しようとすると、エラーが返されます。
ALTER TABLE Faculty(ADD CONSTRAINT c1 PRIMARY KEY(ID))
次の例では、デフォルトのキー名である PK_ID を使用して、Faculty テーブルに主キーが作成されます。
ALTER TABLE Faculty(ADD PRIMARY KEY(ID))
————————
次の例では、制約 UNIQUE が列 col1 と col2 に追加されます。すべての列の col1 と col2 の値の組み合わせが、テーブル内で一意になります。どちらの列も個々に一意である必要はありません。
ALTER TABLE Class(ADD UNIQUE(col1,col2))
————————
次の例では、Faculty テーブル内の主キーが削除されます。テーブルに複数の主キーがあってはならないので、既に主キーが定義されているテーブルに主キーを追加することはできません。テーブルの主キーを変更するには、既存のキーを削除してから新しい主キーを追加します。
ALTER TABLE Faculty(ADD PRIMARY KEY)
親テーブルから主キーを削除するには、その前に、従属テーブルから対応する外部キーをすべて削除する必要があります。
————————
次の例は、Class テーブルに新規の外部キーを追加します。Faculty_ID 列はヌル値を含まない列として定義されます。ヌル値を許可する列には外部キーを作成できません。
ALTER TABLE Class ADD CONSTRAINT Teacher FOREIGN KEY (Faculty_ID) REFERENCES Faculty (ID) ON DELETE RESTRICT
この例では、削除制限規則によって、まず教職員の全講座を変更または削除してからでないと、その教職員をデータベースから削除できないようになっています。また、REFERENCES 句にリストされている列(ID)は任意であることに注目してください。ステートメントをより明確にするために、好みによって REFERENCES 句に列のリストを含めることができます。ただし、REFERENCES 句で参照できる列は参照テーブルの主キーのみです。
次のステートメントでは、上記の例で追加した外部キーを削除する方法を示します。Zen は従属テーブルから外部キーを削除し、従属テーブルと親テーブル間の参照制約を取り除きます。
ALTER TABLE Class DROP CONSTRAINT Teacher
————————
次の例は、CONSTRAINT 句を使用しないで Class テーブルに外部キーを追加します。この場合、外部キーの制約は内部的に生成され、Faculty の主キー(ID)を参照するように定義されます。REFERENCES 句にリストされている列は任意です。ステートメントをより明確にするために、好みによって REFERENCES 句に列のリストを含めることができます。ただし、REFERENCES 句で使用できる列は参照テーブルの主キーのみです。
ALTER TABLE Class ADD FOREIGN KEY (Faculty_ID) REFERENCES Faculty (ID) ON DELETE RESTRICT
これにより、外部キー FK_Faculty_ID が作成されます。外部キーを削除するには、CONSTRAINT キーワードを指定します。
ALTER TABLE Class DROP CONSTRAINT FK_Faculty_ID
————————
次の例では、テーブル内の制約と列を追加および削除する方法を示します。このステートメントにより、Faculty テーブル内の列 salary が削除され、整数型の列 col1 が追加され、制約 c1 が削除されます。
ALTER TABLE Faculty(DROP salary, ADD col1 INT, DROP CONSTRAINT c1)
————————
次の例はどちらも、複数の列のデータ型を変更する方法を示しています。
ALTER TABLE t1 (ALTER c2 INT, ADD D1 CHAR(20), DROP C4, ALTER C5 LONGVARCHAR, ADD D2 LONGVARCHAR NOT NULL)
ALTER TABLE t2 (ALTER c1 CHAR(50), DROP CONSTRAINT MY_KEY, DROP PRIMARY KEY, ADD MYCOLUMN INT)
————————
次の例では、列オプションの ALTER と MODIFY を使って、列のデフォルト値およびオルタネート コレーティング シーケンスを設定したり削除する方法が示されています。
CREATE TABLE t1 (c1 INT DEFAULT 10, c2 CHAR(10))
ALTER TABLE t1 ALTER c1 INT DEFAULT 20
-列 c1 のデフォルト値を 20 に再設定する
ALTER TABLE t1 ALTER c1 INT
-列 c1 のデフォルト値を削除する
ALTER TABLE t1 ALTER c2 CHAR(10)
COLLATE 'file_path\upper.alt'
COLLATE 'file_path\upper.alt'
-列 c2 のオルタネート コレーティング シーケンスを設定する
ALTER TABLE t1 ALTER c2 CHAR(10)
-列 c2 のオルタネート コレーティング シーケンスを削除する
upper.alt は、ソートする際に大文字と小文字を同等に扱います。たとえば、データベースに abc、ABC、DEF、Def という値がこの順序で挿入されている場合、upper.alt を使ってソートすると、abc、ABC、DEF、Def のように返されます(値 abc と ABC、DEF と Def は同じものと判断され、これらは挿入された順序で返されます)。標準の ASCII ソートでは、大文字は小文字の前に配列されており、ソート結果は ABC、DEF、Def、abc のようになります。
————————
次のステートメントは、列 Registrar_ID が結果セットにリストされるときの位置を、現在位置から 2 番目へ論理的に移動させます。
ALTER TABLE Billing PSQL_MOVE Registrar_ID TO 2
次のステートメントは、列 Amount_Owed と Amount_Paid が結果セットにリストされるときの位置を、それぞれ現在位置から 2 番目と 3 番目へ移動させます。
ALTER TABLE Billing ( PSQL_MOVE Amount_Owed TO 2, PSQL_MOVE Amount_Paid TO 3 )
————————
次のステートメントは、列 Registrar_ID のデータ ファイル内の位置を、現在位置から 2 列目へ物理的に移動させます。これにより、変更を反映させるためにデータ ファイルのリビルドが生じます。
ALTER TABLE Billing PSQL_MOVE Registrar_ID TO PSQL_PHYSICAL 2
次のステートメントは、列 Amount_Owed と Amount_Paid のデータ ファイル内の位置を、それぞれ現在位置から 2 列目と 3 列目へ移動させます。
ALTER TABLE Billing ( PSQL_MOVE Amount_Owed TO PSQL_PHYSICAL 2, PSQL_MOVE Amount_Paid TO PSQL_PHYSICAL 3 )
————————
テーブル t1 には列 c1 と col2 があるとします。次のステートメントによって、列 c1 の名前が c2 に変更されます。
ALTER TABLE t1 RENAME COLUMN c1 TO c2
————————
テーブル t1 には列 c1 と col2 があるとします。次のステートメントは、列の名前(col2)を既存の列の名前(c1)に変更しようとするため、エラー(列名が重複しています)が返されます。
ALTER TABLE t1 (RENAME COLUMN c1 TO c2, RENAME COLUMN col2 TO c1)
代わりに、2 つの ALTER ステートメントを発行する必要があります。1 つ目は c1 を c2 に名前変更します。2つ目は col2 を c1 に名前変更します。
ALTER TABLE t1 (RENAME COLUMN c1 TO c2)
ALTER TABLE t1 (RENAME COLUMN col2 TO c1)
関連項目
ALTER USER
ALTER USER ステートメントは、ユーザー アカウントの名前またはパスワードを変更します。
構文
ALTER USER ユーザー名 < RENAME TO 新しいユーザー名 | WITH PASSWORD ユーザー パスワード >
備考
Master ユーザーのみがユーザーの名前を変更できます。ほかのユーザーが自身のパスワードを変更するには、WITH PASSWORD 句を記述するか、SET PASSWORD を使用します。SET PASSWORD を参照してください。
このステートメントを実行するには、セキュリティ設定が有効になっている必要があります。
このステートメントは、RENAME TO オプションまたは WITH PASSWORD キーワードと共に使用する必要があります。
新しいユーザー名はデータベース内で固有の名前である必要があります。
ユーザー名とユーザー パスワードは、空白やその他の非英数文字が含まれている場合には、二重引用符で囲む必要があります。作成されるユーザーの詳細については、ユーザーおよびグループへの権限の付与を参照してください。
メモ: パスワードの制限については、『Advanced Operations Guide』の識別子の制限およびデータベース セキュリティトピックを参照してください。ユーザーとグループの詳細については、『Advanced Operations Guide』の Master ユーザー、ユーザーとグループ、および『Zen User's Guide』の権限の割り当て作業を参照してください。
例
次の例では、ユーザー アカウントの名前の変更方法を示します。
ALTER USER pgranger RENAME TO grangerp
アカウントの名前 pgranger が grangerp に変更されます。
ALTER USER pgranger RENAME TO "polly granger"
アカウントの名前 pgranger は、英数字以外の文字を含む polly granger に変更されます。
————————
次の例では、ユーザー アカウントのパスワードの変更方法を示します。
ALTER USER pgranger WITH PASSWORD Prvsve1
ユーザー アカウント pgranger のパスワードは Prvsve1(大文字と小文字を区別)に変更されます。
ALTER USER pgranger WITH PASSWORD "Nonalfa$"
ユーザー アカウント pgranger のパスワードは、非英数文字を含む Nonalfa$(大文字と小文字を区別)に変更されます。
関連項目
ANY
備考
ANY キーワードは ALL キーワードと似た働きを持ちますが、サブクエリの結果テーブル内のどの行に対しても条件を満たしていれば、Zen はその比較した行を結果テーブルに含みます。
例
次のステートメントは、Person テーブルの ID 列と、サブクエリの結果テーブルの ID 列を比較します。Person テーブルの ID 値と一致する値がサブクエリの結果テーブルの ID 値にある場合、Zen では、Person テーブルの行が SELECT ステートメントの結果テーブルに含まれます。
SELECT p.ID, p.Last_Name
FROM Person p
WHERE p.ID = ANY
(SELECT f.ID FROM Faculty f WHERE f.Dept_Name = 'Chemistry')
関連項目
AS
備考
AS 句を使用して、選択項目またはテーブルに名前を割り当てます。この名前は、ステートメントのほかの場所で、選択項目を参照するときに使用できます。名前はよくエイリアスと呼ばれます。
AS 句を非集計列に使用すると、WHERE、ORDER BY、GROUP BY、HAVING の各句で名前を参照できます。AS 句を集計列に使用すると、ORDER BY 句のみで名前を参照できます。
定義する名前は、SELECT リスト内で重複しないようにする必要があります。
列のエイリアスは列名として返されます。グループ集計を含む、列エイリアスのない計算列には、EXPR-1、EXPR-2 などのシステムによって生成された名前が割り当てられます。
例
次のステートメントの AS 句は、選択項目 SUM (Amount_Paid) に名前 Total を割り当て、結果を学生ごとの合計でソートするように Zen に指示します。
SELECT Student_ID, SUM (Amount_Paid) AS Total
FROM Billing
GROUP BY Student_ID
ORDER BY Total
AS キーワードは、次の例のようにテーブル エイリアスに使用する場合は省略可能です。FROM 句内で AS 句をテーブル名に使用すると、WHERE、ORDER BY、GROUP BY、HAVING の各句で名前を参照できます。
SELECT DISTINCT c.Name, p.First_Name, c.Faculty_Id
FROM Person AS p, class AS c
WHERE p.Id = c.Faculty_Id
ORDER BY c.Faculty_Id
このクエリは次のように、FROM 句で AS 句を使用しないよう書き直すことができます。
SELECT DISTINCT c.Name, p.First_Name, c.Faculty_Id
FROM Person p, class c
WHERE p.Id = c.Faculty_Id
ORDER BY c.Faculty_Id
テーブル エイリアスを確立したら、WHERE 句内にテーブル名とエイリアスが混在してはいけません。次は動作しません。
SELECT DISTINCT c.Name, p.First_Name, c.Faculty_Id
FROM Person p, class c
WHERE Person.Id = c.Faculty_Id
ORDER BY c.Faculty_Id
関連項目
BEGIN [ATOMIC]
備考
BEGIN および END キーワードは、ストアド プロシージャ、ユーザー定義関数、またはトリガー宣言の本体を定義するために使用されます。キーワードにより、プロシージャ、関数、トリガー内に複合ステートメントが作成されます。
ATOMIC キーワードを追加すると、ステートメントのブロックが 1 つのトランザクションであるかのように、トランザクション動作を制御することができます。ATOMIC は、ブロック内のすべてのステートメントは成功するかロール バックするか、いずれかが必要であることを示します。
例
次の例では、BEGIN ... END ブロックが ATOMIC として設定されています。両方の INSERT がエラーなしで実行された場合にのみ、レコードが挿入されます。どちらかのステートメントがエラーを返す(この場合は 2 番目の INSERT がステータス 5 を返す)場合、レコードは挿入されません。
CREATE PROCEDURE Add_Tuition();
BEGIN ATOMIC
INSERT INTO Tuition(ID, Degree, Residency, Cost_Per_Credit, Comments) VALUES (9, 'Test', 0, 100.0, 'Training');
INSERT INTO Tuition(ID, Degree, Residency, Cost_Per_Credit, Comments) VALUES (8, 'Test', 0, 100.0, 'Training');
END
関連項目
CALL
備考
ストアド プロシージャを呼び出す場合は、CALL ステートメントを使用します。ストアド プロシージャは、ユーザー定義のものでもシステム ストアド プロシージャでもかまいません。
例
次の例では、パラメーターのないユーザー定義のプロシージャを呼び出します。
CALL NoParms() または CALL NoParms
次の例では、パラメーターのあるユーザー定義のプロシージャを呼び出します。
CALL Parms(vParm1, vParm2)
CALL CheckMax(N.Class_ID)
————————
次のステートメントは、システム ストアド プロシージャを呼び出すことにより、Dept テーブル内のすべての列に関する列情報をリストします。
CALL psp_columns('Demodata','Dept')
関連項目
CASCADE
備考
外部キーの作成時に CASCADE を指定した場合、Zen では DELETE CASCADE 規則が使用されます。ユーザーが親テーブルの行を削除すると、Zen によって従属テーブルの対応する行が削除されます。
DELETE CASCADE は注意して使用してください。Zen では、自己参照するテーブルに対し、循環するカスケード削除を使用できます。『Advanced Operations Guide』の削除カスケードに記載されている例を参照してください。
関連項目
CASE(式)
CASE 式は値を返します。CASE 式には 2 つの形式があります。
• 単一 When/Then。この形式は、1 つの値式を一連の値式と比較して結果を判定します。値式は、それらが列挙されている順に評価されます。値式が TRUE と評価された場合、CASE は THEN 句の値式を返します。
• 検索 When/Then。この形式は、一連のブール式を評価して結果を判定します。ブール式は、それらが列挙されている順に評価されます。ブール式が TRUE と評価された場合、CASE は THEN 句の式を返します。
どちらの形式もオプションの ELSE 引数をサポートしています。ELSE 句を使用しない場合は、ELSE NULL であることを意味します。
構文
単一 When/Then
CASE case値式
WHEN when式 THEN then式 [...]
[ ELSE else式 ]
END
検索 When/Then
CASE
WHEN 検索式 THEN then式 [...]
[ ELSE else式 ]
END
引数
case値式 ::= 単一 When/Then 形式の CASE で評価される式。
when式 ::= case 値式と比較される式。case 値式と各 when 式のデータ型は同じであるか、または暗黙に型変換されなければなりません。
then式 ::= case 値式 = when 式が TRUE と評価された場合に返される式。
else式 ::= TRUE と評価される比較演算がない場合に返される式。この引数を省略した場合、TRUE と評価される比較演算がなければ、CASE は NULL を返します。
検索式 ::= 検索形式の CASE で評価されるブール式。検索式には、有効なブール式であればどのような式でも指定できます。
備考
CASE 式は SELECT ステートメント内で使用する必要があります。SELECT ステートメントはストアド プロシージャやビュー内に記述できます。
例
次のステートメントは、単一 When/Then 形式を使って、Course テーブルにリストされている美術講座の必須条件をレポートします。
SELECT name 'Course ID', description 'Course Title',
CASE name
WHEN 'Art 101' THEN 'None'
WHEN 'Art 102' THEN 'Art 101 or instructor approval'
WHEN 'Art 203' THEN 'Art 102'
WHEN 'Art 204' THEN 'Art 203'
WHEN 'Art 305' THEN 'Art 101'
WHEN 'Art 406' THEN 'None'
WHEN 'Art 407' THEN 'Art 305'
END
AS 'Prerequisites' FROM Course WHERE Dept_Name = 'Art' ORDER BY name
このクエリによって次の一覧が返されます。
Course ID | Course Title | Prerequisites |
Art 101 | Drawing I | None |
Art 102 | Drawing II | Art 101 or instructor approval |
Art 203 | Drawing III | Art 102 |
Art 204 | Drawing IV | Art 203 |
Art 305 | Sculpture | Art 101 |
Art 406 | Modern Art | None |
Art 407 | Baroque Art | Art 305 |
————————
前のステートメントに ELSE 句を含めるように変更できます。
SELECT name 'Course ID', description 'Course Title',
CASE name
WHEN 'Art 101' THEN 'None'
WHEN 'Art 102' THEN 'Art 101 or instructor approval'
WHEN 'Art 203' THEN 'Art 102'
WHEN 'Art 204' THEN 'Art 203'
WHEN 'Art 305' THEN 'Art 101'
ELSE 'Curriculum plan for Art History majors'
END
AS 'Prerequisites' FROM Course WHERE Dept_Name = 'Art' ORDER BY name
このクエリによって今度は次の一覧が返されます。
Course ID | Course Title | Prerequisites |
Art 101 | Drawing I | None |
Art 102 | Drawing II | Art 101 or instructor approval |
Art 203 | Drawing III | Art 102 |
Art 204 | Drawing IV | Art 203 |
Art 305 | Sculpture | Art 101 |
Art 406 | Modern Art | Curriculum plan for Art History majors |
Art 407 | Baroque Art | Curriculum plan for Art History majors |
————————
次のステートメントでは検索 When/Then 形式を使って、個人別に資格のある奨学金プログラムをレポートします。
SELECT last_name, first_name,
CASE
WHEN scholarship = 1 THEN 'Scholastic'
WHEN citizenship <> 'United States' THEN 'Foreign Study'
WHEN (date_of_birth >= '1960-01-01' AND date_of_birth <= '1970-01-01') THEN 'AJ-44 Funds'
ELSE 'NONE'
END
AS 'Funding Program' FROM Person ORDER BY last_name
以下に、このクエリによって返される一覧の一部を示します。
Last_Name | First_Name | Funding Program |
Abad | Alicia | NONE |
Abaecherli | David | Foreign Study |
Abebe | Marta | Foreign Study |
Abel | James | AJ-44 Funds |
Abgoon | Bahram | Foreign Study |
Abken | Richard | NONE |
Abu | Austin | Foreign Study |
Abuali | Ibrahim | AJ-44 Funds |
Acabbo | Joseph | NONE |
Acar | Dennis | Foreign Study |
————————
次の例は、ストアド プロシージャ内で CASE 式を使用する方法を示します。
CREATE PROCEDURE pcasetest() RETURNS (d1 CHAR(10), d2 CHAR(10));
BEGIN
SELECT c1, CASE WHEN c1 = 1 THEN c4
WHEN c1 = 2 THEN c5
ELSE
CASE WHEN c2 = 100.22 THEN c4
WHEN c2 = 101.22 THEN c5 END END
FROM tcasetest;
END
CALL pcasetest
————————
次の例は、ビュー内で CASE 式を使用する方法を示します。
CREATE VIEW vcasetest (vc1, vc2) AS
SELECT c1, CASE WHEN c1 = 1 THEN c4
WHEN c1 = 2 THEN c5
ELSE
CASE WHEN c2 = 100.22 THEN c4
WHEN c2 = 101.22 THEN c5 END END
FROM TCASEWHEN
SELECT * FROM vcasetest
関連項目
CASE(文字列)
備考
CASE キーワードは、文字列型の列を対象とする制限句を評価するとき、Zen に大文字小文字を無視させます。CASE は、CREATE TABLE または ALTER TABLE ステートメントや、SELECT ステートメントの ORDER BY 句で列属性として指定できます。
たとえば、Name という名前の列があり、CASE 属性付きで定義されているとします。Name = 'Smith' と Name = 'SMITH' を使って 2 行挿入した場合、制限に Name = 'smith' と指定したクエリでは、両方の列が正しく返されます。
メモ: CASE(文字列)は、マルチバイトの文字列および NCHAR 文字列をサポートしません。このキーワードは、文字列データがシングルバイトの ASCII であることを前提としています。これはつまり、CASE 属性は NVARCHAR および NCHAR データ型の列ではサポートされないということです。文字列関数では、マルチバイト文字列および NCHAR 文字列がサポートされます。文字列関数を参照してください。
例
次の例は、CASE キーワードを使って Student テーブルに列を追加する方法を示します。
ALTER TABLE Student ADD Name char(64) CASE
次の例は、SELECT ステートメントの ORDER BY 句で CASE を使用する方法を示します。
SELECT Id, Last_Name+', '+First_Name AS Whole_Name, Phone FROM Person ORDER BY Whole_Name CASE
関連項目
CLOSE
構文
CLOSE カーソル名
カーソル名 ::= ユーザー定義名
備考
CLOSE ステートメントにより、開いている SQL カーソルを閉じます。
カーソル名が示すカーソルは開いている必要があります。
このステートメントは、ストアド プロシージャ、ユーザー定義関数、およびトリガーの内部でのみ使用できます。カーソルおよび変数は、ストアド プロシージャ、ユーザー定義関数、およびトリガーの内部でのみ使用できます。
例
次の例では、カーソル BTUCursor が閉じます。
CLOSE BTUCursor;
————————
CREATE PROCEDURE MyProc(OUT :CourseName CHAR(7)) AS
BEGIN
DECLARE cursor1 CURSOR
FOR SELECT Degree, Residency, Cost_Per_Credit
FROM Tuition ORDER BY ID;
OPEN cursor1;
FETCH NEXT FROM cursor1 INTO :CourseName;
CLOSE cursor1;
END
関連項目
COALESCE
COALESCE スカラー関数は 2 つ以上の引数を取り、その式リストを左から調べて最初の非ヌル引数を返します。
構文
COALESCE ( 式, 式 [, ... ] )
式 ::= 任意の有効な式
戻り値の型
COALESCE 関数は、式リスト内のいずれかの式の値を返します。戻り値のデータ型の詳細な一覧については、COALESCE でサポートされるデータ型の組み合わせと結果のデータ型を参照してください。
制限
この関数は少なくとも 2 つの引数を取ります。
COALESCE(10, 20)
無効:
COALESCE()
メモ: 無効な例では、次の解析時エラーが発生します:
"COALESCE には少なくとも 2 つの引数がなければなりません。"
"COALESCE には少なくとも 2 つの引数がなければなりません。"
式リストには、少なくとも 1 つはヌルでない引数が含まれている必要があります。
COALESCE (NULL, NULL, 20)
無効:
COALESCE (NULL, NULL, NULL)
メモ: 無効な例では、次の解析時エラーが発生します:
"COALESCE のすべての引数を NULL 関数にすることはできません。"
"COALESCE のすべての引数を NULL 関数にすることはできません。"
この関数は、式リストに指定するデータ型の組み合わせによってはサポートしていないものがあります。たとえば、BINARY や VARCHAR など、暗黙的に相互に変換できない引数を COALESCE に指定することはできません。
COALESCE でサポートされるデータ型の組み合わせと結果のデータ型
次の図は、サポートされているさまざまなデータ型の組み合わせの詳細を示すと同時に、それらを COALESCE 関数で用いた場合に結果として生じるデータ型の確認に役立ちます。 
図表の要素 | 説明 |
|---|---|
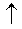 | これらの型は COALESCE 関数で直接使用できます。結果はオペランド 2 の型になります。 |
 | これらの型は COALESCE 関数で直接使用できます。結果はオペランド 1 の型になります。 |
空のセル | これらの型には互換性がありません。COALESCE で直接使用することはできません。明示的な CONVERT が必要です。 |
D | 結果は SQL_DOUBLE 型になります。 |
B | 結果は SIM_BCD 型になります。 |
I | 結果は SQL_INTEGER 型になります。 |
S | 結果は SQL_SMALLINT 型になります。 |
COALESCE 関数でサポートされていない型の組み合わせ(図で空のセルになっています)を使用すると、解析時エラーが発生します。
行のエラーです。
割り当てエラーです。
式の評価エラーです。
割り当てエラーです。
式の評価エラーです。
例
次の例で、10+2 は SMALLINT として扱われ、ResultType (SMALLINT, SMALLINT) は SMALLINT になります。したがって、結果の型は SMALLINT になります。
SELECT COALESCE(NULL,10 + 2,15,NULL)
最初のパラメーターは NULL です。2 番目の式は 12 と評価されます。この値は NULL でなく、結果の型の SMALLINT へ変換できます。そのため、この例の戻り値は 12 になります。
————————
次の例で、10 は SMALLINT として扱われ、ResultType (SMALLINT, VARCHAR) は SMALLINT になります。したがって、結果の型は SMALLINT になります。
SELECT COALESCE(10, 'abc' + 'def')
最初のパラメーターは 10 で、この値は結果の型の SMALLINT へ変換できます。そのため、この例の戻り値は 10 になります。
COMMIT
COMMIT ステートメントにより、論理トランザクションの終了を示し、テンポラリ データをパーマネント データに変換します。
構文
COMMIT [ ]
例
次の例では、ストアド プロシージャの中で、Billing テーブル内の Amount_Owed 列を更新するトランザクションが開始されます。この作業がコミットされ、別のトランザクションによって Amount_Paid 列が更新されてゼロに設定されます。最後の COMMIT WORK ステートメントにより、2 番目のトランザクションが終了します。
START TRANSACTION;
UPDATE Billing B
SET Amount_Owed = Amount_Owed - Amount_Paid
WHERE Student_ID IN
(SELECT DISTINCT E.Student_ID
FROM Enrolls E, Billing B
WHERE E.Student_ID = B.Student_ID);
COMMIT WORK;
START TRANSACTION;
UPDATE Billing B
SET Amount_Paid = 0
WHERE Student_ID IN
(SELECT DISTINCT E.Student_ID
FROM Enrolls E, Billing B
WHERE E.Student_ID = B.Student_ID);
COMMIT WORK;
————————
CREATE PROCEDURE UpdateBilling( ) AS
BEGIN
START TRANSACTION;
UPDATE Billing SET Amount_Owed = Amount_Owed + Amount_Owed;
UPDATE Billing set Amount_Owed = Amount_Owed + 100 WHERE Student_ID = 10;
COMMIT;
END;
関連項目
CREATE DATABASE
CREATE DATABASE ステートメントにより、新しいデータベースを作成します。データベースにログインしているユーザーは誰でも、このステートメントを発行できます。ユーザーはまた、指定の場所でファイルを作成するために、オペレーティング システムからの権限を持っている必要があります。
構文
CREATE DATABASE [ IF NOT EXISTS ] データベース名 DICTIONARY_PATH '辞書パス名' [ DATA_PATH 'データ パス名' ] [ ; 'データ パス名' ]...] [ NO_REFERENTIAL_INTEGRITY ] [ BOUND ] [ REUSE_DDF ] [ DBSEC_AUTHENTICATION ] [ DBSEC_AUTHORIZATION ] [ V1_METADATA | V2_METADATA ] [ ENCODING < 'コード ページ名' | 'CPコード ページ番号' | DEFAULT > ]
データベース名 ::= データベースのユーザー定義名
辞書パス名 ::= データ辞書ファイル(DDF)の場所のユーザー定義名
データ パス名 ::= データ ファイルの場所のユーザー定義名
コード ページ名 ::= 有効なコード ページの名前
CPコード ページ番号 ::= "CP" で始まる有効なコード ページの番号
備考
ODBC を使用している場合は、CREATE DATABASE はデータベースのみを作成し、関連するデータ ソース名(DSN)は作成しないということを覚えておいてください。DSN が必要な場合は、個別に作成する必要があります。『Zen User's Guide』の ODBC データベース アクセスの設定を参照してください。
CREATE DATABASE ステートメントは、サーバー上で最初のデータベースを作成する場合には使用できません。ユーザーは、CREATE DATABASE ステートメントを発行する前にデータベースにログオンしていなければならないからです。そのため、事前に少なくとも 1 つはデータベースが存在している必要があります。
CREATE DATABASE ステートメントは、ストアド プロシージャおよびユーザー定義関数内では使用できません。
データベース名と IF NOT EXISTS 句
データベース名には、新しいデータベースの名前を指定します。データベース名はサーバー内で一意であり、識別子の規則に従っている必要があります。『Advanced Operations Guide』の識別子の制限を参照してください。
データベースが存在した場合、IF NOT EXISTS 句を省略していると、エラーが発生します(ステータス コード 2303)。IF NOT EXISTS 句を記述している場合は、エラーは返されません。
辞書パス
辞書パス名は、辞書ファイル(DDF)が存在する物理的な保管場所を指定します。この場所には、CREATE TABLE ステートメントを使用した場合、あるいは Zen Control Center(ZenCC)を使ってテーブルを作成した場合に、データ ファイルも保存されます。『Zen User's Guide』の辞書のロケーションを参照してください。
データ パス
データ パス名には、データベースのデータ ファイルが存在する可能性のある場所を指定します(下記の「メモ」を参照してください)。複数のパス名をセミコロンで区切って指定することができます。
データ パス名は、呼び出し元アプリケーションの分析視点からではなく、データベース エンジンの視点から有効であれば、どのようなパスでもかまいません。指定した場所は既に存在している必要があります。CREATE DATABASE ステートメントでディレクトリは作成されません。
データ ファイルに対し辞書ファイルと同じ場所を使用する場合は、データ パス名を省略します。データ パス名に空文字列を渡しても、同じ場所を指定することができます。たとえば、DATA_PATH '' という指定は、データ パスが空文字列であることを示します。
メモ: CREATE TABLE ステートメントまたは ZenCC を使用してテーブルを作成した場合、データ ファイルは指定した最初の辞書パス名に保存されます。辞書パス名を指定していない場合、データ ファイルは辞書パス名の場所に作成されます。
データ パス名は、Distributed Tuning Interface(DTI)を介してテーブルを作成している場合に有用です。DTI 関数の PvAddTable では、データ ファイルを配置したい場所を指定できます。『Distributed Tuning Interface Guide』の PvAddTable() を参照してください。
データ パス名は、Distributed Tuning Interface(DTI)を介してテーブルを作成している場合に有用です。DTI 関数の PvAddTable では、データ ファイルを配置したい場所を指定できます。『Distributed Tuning Interface Guide』の PvAddTable() を参照してください。
参照整合性
デフォルトで、データベース エンジンは参照整合性を強要します。NO_REFERENTIAL_INTEGRITY 句を指定すると、データベース内に定義されているトリガーおよび参照整合性は強要されなくなります。
参照整合性の設定および Btrieve およびリレーショナル制約間の相互作用を参照してください。
BOUND
BOUND を指定すると、DDF がデータベースにバインドされます。バウンド データベースは、データベース名を単一の DDF のセットと関連付けます。この DDF は 1 つのデータ ファイルのセットしか参照しません。DDF は、既存の DDF か、CREATE DATABASE ステートメントの実行によって作成される DDF のいずれかがバインドされます。
DDF がバインドされると、複数のデータベースでその DDF を使用することも、複数の DDF のセットでデータ ファイルを参照することもできなくなります。
BOUND を指定しなければ、DDF はデータベースにバインドされません。
『Advanced Operations Guide』のバウンド データベースと整合性の設定を参照してください。
辞書ファイル
REUSE_DDF キーワードは、既存の DDF をデータベースと関連付けます。既存の DDF は辞書パス名の場所になければなりません。
REUSE_DDF を省略すると、辞書パス名の場所に DDF が既に存在していない限り、新しい DDF が作成されます。DDF が辞書パス名の場所に存在すれば、新しい DDF が作成される代わりに、既存の DDF がデータベースと関連付けられます。
セキュリティ
データベース エンジンは、MicroKernel エンジンの 3 つのセキュリティ モデルをサポートしています。
• クラシック。コンピューターへのログインに成功したユーザーは、データ ファイルに対してユーザーに割り当てられているファイル システム権限のレベルに従って、データベース コンテンツへのアクセス権を持ちます。ファイル システム権限はオペレーティング システムによって割り当てられます。
• データベース。データベースのユーザー アカウントはオペレーティング システムのユーザー アカウントとは関係ありません。データに対するユーザー アクセス権は、データベースに設定されているユーザーのアクセス許可によって決定されます。
• 混合。このポリシーは、ほか 2 つのポリシーの側面を持っています。ユーザーはオペレーティング システムのユーザー名とパスワードを使ってログインしますが、データに対するユーザー アクセス権はデータベースに設定されているユーザーのアクセス許可によって決定されます。
セキュリティの完全な説明については、『Advanced Operations Guide』の Zen セキュリティを参照してください。
DBSEC_AUTHENTICATION および DBSEC_AUTHORIZATION キーワードにより、データベースのセキュリティ ポリシーを設定します。
ステートメントにキーワードを含んでいるかいないか | セキュリティ モデル | |||
|---|---|---|---|---|
DBSEC_AUTHENTICATION | DBSEC_AUTHORIZATION | クラシック | データベース | 混合 |
省略 | 省略 | X | ||
含む | 含む | X | ||
省略 | 含む | X | ||
メタデータのバージョン
リレーショナル エンジンでは、メタデータでバージョン 1(V1)とバージョン 2(V2)という 2 つのバージョンをサポートします。メタデータのバージョンは、そのデータベース内のすべてのデータ辞書ファイル(DDF)に適用されます。デフォルトは "メタデータ バージョン 1" です。
ほかにも特性はありますが、メタデータ バージョン 2 では、多くの識別子名に最大 128 バイトの名前を付けることができ、ビューおよびストアド プロシージャに対する権限が認められています。詳しい説明については、Zen メタデータを参照してください。
メタデータ バージョン 1 を指定する場合、V1_METADATA キーワードは含めても省略してもかまいません。メタデータ バージョン 2 を指定する場合は、V2_METADATA キーワードを含める必要があります。
エンコード
エンコードは文字セットを表す標準規格です。文字データは、コンピューターがデジタル処理できる標準形式に変換する、つまりエンコードする必要があります。エンコードは、Zen サーバー エンジンと Zen クライアント アプリケーションとの間で規定する必要があります。互換性のあるエンコードを使用すれば、サーバーとクライアントでデータが正しく変換されます。
エンコードのサポートは、データベース コード ページとクライアント エンコードに分割されました。この 2 種類のエンコードは、別個のものですが相互に関係しています。詳細については、『Advanced Operations Guide』のデータベース コード ページとクライアント エンコードを参照してください。
データベース コード ページおよびクライアント エンコードは、リレーショナル エンジンのみに適用されます。MicroKernel エンジンには影響がありません。
コード ページは、名前または文字 CP の後にコード ページ番号を続けて指定します。いずれも、一重引用符で囲む必要があります。たとえば、有効な名前は UTF-8 であり、有効な番号は CP1251 です。
Windows および Linux オペレーティング システムは共に、OS エンコードと呼ばれるデフォルトのエンコードがあります。デフォルトの OS エンコードはオペレーティング システム間で異なります。キーワード DEFAULT を使用すると、サーバーの OS エンコードが指定されます。
ENCODING キーワードが指定されていない場合、データベースはサーバーの OS エンコードをデフォルトとします。
無効なコード ページ番号やコード ページ名を指定すると、"コード ページの値が無効です" というエラーが返されます。
複数のデータベースを使用する SQL ステートメントでは、すべてのデータベースで同じコード ページを使用していることを確認する必要があります。そうしないと、文字データが正しく返されません。
メモ: データベース エンジンは、アプリケーションがデータベースに追加するデータおよびメタデータのエンコードを検証しません。エンジンは、すべてのデータが、『Advanced Operations Guide』のデータベース コード ページとクライアント エンコードで説明されているようにサーバーまたはクライアントのエンコードを使用して入力されるものと想定しています。
複数のデータベースを使用する SQL ステートメント(複数データベースの結合など)では、すべてのデータベースでデータベース コード ページが同じであることを確認してください。そうしないと、文字データが正しく返されません。
複数のデータベースを使用する SQL ステートメント(複数データベースの結合など)では、すべてのデータベースでデータベース コード ページが同じであることを確認してください。そうしないと、文字データが正しく返されません。
有効なコード ページ名とコード ページ番号
サポートされるコード ページ名とコード ページ番号は ZenCC で一覧表示することができます。ZenCC を起動して[データベースの新規作成]ダイアログを開きます(『Zen User's Guide』の新規データベースを作成するにはを参照してください)。[データベース コード ページ]オプションで、[コード ページの変更]をクリックします。開いたダイアログで[データベース コード ページ]をクリックすると、使用できるコード ページの一覧が表示されます。
Linux では、dbmaint ユーティリティの man ページを参照すると、使用できるコード ページ名とコード ページ番号の一覧が表示されます。この例については、『Zen User's Guide』の dbmaint を参照してください。
例
このセクションでは、CREATE DATABASE の例を示します。
次の例は、inventorydb という名前のデータベースを作成し、DDF の場所をドライブ D: の mydbfiles\ddf_location フォルダーと指定しています。D:\mydbfiles\ddf_location には DDF が存在しないため、新しい DDF が作成されます。データ ファイルも DDF と同じ場所に保存されます。データベースはメタデータ バージョン 1 を使用します。
CREATE DATABASE inventorydb DICTIONARY_PATH 'D:\mydbfiles\ddf_location'
————————
次の例は、HRUSBenefits という名前のデータベースがまだ存在していなければ作成し、DDF の場所をドライブ C: の HRDatabases\US フォルダーと指定しています。また、データ ファイルが存在する可能性のある場所として、C: ドライブの HRDatabases\US\DataFiles ディレクトリと、E: ドライブの Backups\HRUSData ディレクトリを指定しています(データ パスの「メモ」を参照してください)。DDF が DICTIONARY_PATH に存在する場合は、既存の DDF が使用されます。データベースはメタデータ バージョン 1 を使用します。
CREATE DATABASE IF NOT EXISTS HRUSBenefits DICTIONARY_PATH 'C:\HRDatabases\US' DATA_PATH 'C:\HRDatabases\US\DataFiles ; E:\Backups\HRUSData' REUSE_DDF
————————
次の例は、EastEurope という名前のデータベースを作成します。DDF の場所をドライブ C: の Europe\DbaseFiles フォルダーとし、新しい DDF を作成して、それをデータベースにバインドします。また、セキュリティ ポリシーを「混合」に設定し、メタデータ バージョン 2 を使用します。
CREATE DATABASE EastEurope DICTIONARY_PATH 'C:\Europe\DbaseFiles' BOUND DBSEC_AUTHORIZATION V2_METADATA
————————
次の例は、Region5Acct という名前のデータベースを作成します。DDF の場所をドライブ D: の Canada\Region5\Accounting フォルダーとし、データベース コード ページをサーバーで使用されているデフォルトのコード ページに設定します。
CREATE DATABASE Region5Acct DICTIONARY_PATH 'D:\Canada\Region5\Accounting' ENCODING DEFAULT
————————
次の例は、Region2Inventory という名前のデータベースを作成し、DDF の場所をドライブ G: の Japan\Region2 フォルダーと指定し、データベース コード ページを 932 に設定します。
CREATE DATABASE Region2Inventory DICTIONARY_PATH 'G:\Japan\Region2' ENCODING 'CP932'
————————
次の例は、VendorCodes という名前のデータベースを作成します。DDF の場所をドライブ C: の Capitol_Equipment\Milling フォルダーとし、新しい DDF を作成して、それらをデータベースにバインドします。また、セキュリティ ポリシーを「混合」に設定してメタデータ バージョン 2 を使用し、データベース コード ページを 1252 に設定します。
CREATE DATABASE VendorCodes DICTIONARY_PATH 'C:\Capitol_Equipment\Milling' BOUND DBSEC_AUTHORIZATION V2_METADATA ENCODING 'CP1252'
関連項目
CREATE FUNCTION
CREATE FUNCTION ステートメントにより、データベースにスカラー ユーザー定義関数(UDF)を作成します。その後、クエリからユーザー定義関数を呼び出すことができます。
構文
CREATE FUNCTION 関数名 ( [ [ IN ]
{ :パラメーター名 スカラー パラメーターのデータ型 [ DEFAULT 値 | = 値 ] } [...] ] )
RETURNS スカラー戻り値のデータ型
[AS]
BEGIN
関数本体
RETURN スカラー式
END;
関数名 ::= スカラー ユーザー定義関数(UDF)の名前。UDF 名は識別子の規則に従い、データベース内で一意である必要があります。
パラメーター名 ::= スカラー UDF のパラメーター。最大 300 個のパラメーターを使用できます。default が指定されていない場合は、関数を呼び出すときに値を指定する必要があります。
スカラー パラメーターのデータ型 ::= 指定したパラメーターのデータ型。
スカラー戻り値のデータ型 ::= スカラー UDF の戻り値のデータ型。スカラー型のみサポートされます。
値 ::= パラメーター名に割り当てるデフォルト値。DEFAULT キーワードまたは等記号のいずれかを使って指定します。
関数本体 ::= スカラー関数を構成するステートメント。
スカラー式 ::= スカラー UDF の戻り値。
備考
各 UDF 名(データベース名.関数名)は、データベース内で一意である必要があります。UDF 名は、同じデータベース内の以下の名前と同じにできません。
• 組み込み関数名
• ほかの UDF 名
• ストアド プロシージャ名
制約
ユーザー定義関数内で CREATE DATABASE または DROP DATABASE ステートメントを使用することはできません。CREATE、ALTER、UPDATE、DELETE および INSERT のテーブル操作はユーザー定義関数内では許可されません。
スカラー入力パラメーターのみサポートされます。OUTPUT および INOUT パラメーターは使用できません。デフォルトで、すべてのパラメーターが入力になります。IN キーワードを指定する必要はありません。
制限
ユーザー定義関数を作成する際は以下の制限に注意してください。
属性 | 制限 |
|---|---|
パラメーター数 | 300 |
UDF 本体のサイズ | 64 KB |
UDF 名の最大長 | 『Advanced Operations Guide』の識別子の制限を参照してください。 |
UDF 変数名の最大長 | 半角 128 文字 |
サポートされるスカラー入力パラメーターおよび戻り値のデータ型
Zen でサポートされている、スカラー入力パラメーターと戻り値のデータ型を以下の表に示します。TEXT、NTEXT、IMAGE、CURSOR を除くすべてのデータ型を指定できます。
AUTOTIMESTAMP | BIGIDENTITY | BIGINT |
BINARY | BIT | BLOB |
CHAR | CHARACTER | CLOB |
CURRENCY | DATE | DATETIME |
DEC | DECIMAL | DOUBLE |
FLOAT | IDENTITY | INT |
INTEGER | LONG | LONGVARBINARY |
LONGVARCHAR | NCHAR | NLONGVARCHAR |
NUMERIC | NVARCHAR | REAL |
SMALLIDENTITY | SMALLINT | TIME |
TIMESTAMP | TIMESTAMP2 | TINYINT |
UBIGINT | UINT | UINTEGER |
UNIQUEIDENTIFIER | USMALLINT | UTINYINT |
VARBINARY | VARCHAR |
例
このトピックでは、CREATE FUNCTION のいくつかの例を示します。
次の例では、Box テーブルに保存されている四角形のボックスの細目を基に、その四角形の面積を計算する関数を作成します。
CREATE FUNCTION CalculateBoxArea(:boxName CHAR(20))
RETURNS REAL
AS
BEGIN
DECLARE :len REAL;
DECLARE :breadth REAL;
SELECT len, breadth INTO :len, :breadth FROM box
WHERE name = :boxName;
WHERE name = :boxName;
RETURN(:len * :breadth);
END;
————————
次の例では、2 つの整数を比較し、小さい方の値を返す関数を作成します。
CREATE FUNCTION GetSmallest(:A INTEGER, :B INTEGER)
RETURNS INTEGER
AS
BEGIN
DECLARE :smallest INTEGER
IF (:A < :B ) THEN
SET :smallest = :A;
ELSE
SET :smallest = :B;
END IF;
RETURN :smallest;
END;
————————
次の例では、SI = PTR/100 という式を使って単利を計算する関数を作成します。式中の P は元金、T は年数、R は利子率です。
CREATE FUNCTION CalculateInterest(IN :principle FLOAT, IN :period REAL, IN :rate DOUBLE)
RETURNS DOUBLE
AS
BEGIN
DECLARE :interest DOUBLE;
SET :interest = ((:principle * :period * :rate) / 100);
RETURN (:interest);
END;
スカラー ユーザー定義関数の呼び出し
スカラー式がサポートされる場所ならどこでも、関数名の後にカンマ区切りの引数のリストを指定することによって、ユーザー定義関数を呼び出すことができます。引数のリストはかっこで囲みます。
UDF は、データベース修飾子のプレフィックスを付けても付けなくても呼び出せます。データベース修飾子を前に付けない場合は、UDF は現在のデータベース コンテキストから実行されます。データベース修飾子を前に付けた場合は、指定したデータベースのコンテキストから実行されます。下記の例では、データベース修飾子のプレフィックスを使用しているものと使用していないものがあります。
制限
関数を呼び出すとき、引数にパラメーター名を指定することはできません。
関数を呼び出すとき、すべてのパラメーターの引数値は、CREATE FUNCTION ステートメントで定義されたパラメーターの引数値と同じ順序でなければなりません。
ユーザー定義関数の例
プロシージャ内での UDF
CREATE PROCEDURE procTestUdfInvoke() AS
BEGIN
DECLARE :a INTEGER;
SET :a = 99 + (222 + Demodata.GetSmallest(10, 9)) + 10;
PRINT :a;
END;
CALL procTestUdfInvoke()
————————
次の例は、データベース修飾子が省略されている点を除けば、前の例と似ています。
CREATE PROCEDURE procTestUdfInvoke2() AS
BEGIN
DECLARE :a INTEGER;
SET :a = 99 + (222 + GetSmallest(10, 9)) +10;
PRINT :a;
END;
CALL procTestUdfInvoke2
————————
SELECT リスト内での UDF
SELECT GetSmallest(100,99)
————————
WHERE 句での UDF
SELECT name FROM class WHERE id <= GetSmallest(10,20)
————————
UDF 内での UDF
CREATE FUNCTION funcTestUdfInvoke() RETURNS INTEGER AS
BEGIN
DECLARE :a INTEGER;
SET :a = 99 + (222 - Demodata.GetSmallest(10, 9));
RETURN :a;
END;
————————
INSERT ステートメント内での UDF
CREATE TABLE t1(col1 INTEGER, col2 INTEGER, col3 FLOAT)
INSERT INTO t1 VALUES (GetSmallest(10,20), 20 , 2.0)
INSERT INTO t1 (SELECT * FROM t1 WHERE col1 = getSmallest(10,20))
————————
UPDATE ステートメント内での UDF
UPDATE t1 SET col2 = Demodata.GetSmallest(2,10) WHERE col1 = 2
UPDATE t1 SET col1 = 3 WHERE col2 = Demodata.GetSmallest(10, 5)
————————
GROUP BY ステートメント内での UDF
SELECT col2 FROM t1 GROUP BY getSmallest(10,2), col2
————————
ORDER BY ステートメント内での UDF
SELECT col2 FROM t1 ORDER BY Demodata.getSmallest(10,2), col2
————————
再帰 UDF
CREATE FUNCTION factorial(IN :n INTEGER) RETURNS double AS BEGIN
DECLARE :fact DOUBLE;
IF (:n <= 0) THEN
SET :fact = 1;
ELSE
SET :fact = (:n * Demodata.factorial(:n - 1));
END IF;
RETURN :fact;
END;
SELECT Demodata.factorial(20) を使用すると、20 の階乗値を取得できます。
————————
デフォルト値を持つ UDF
CREATE FUNCTION testUdfDefault1(:z INTEGER DEFAULT 10) RETURNS INTEGER AS
BEGIN
RETURN :z-1;
END;
SELECT Demodata.testUdfDefault1()。この関数は、パラメーターが提供されなかった場合には、指定したデフォルト値(10)を使用します。
CREATE FUNCTION testUdfDefault2(:a VARCHAR(20) = 'Accounting Report' ) RETURNS VARCHAR(20) as
BEGIN
RETURN :a;
END;
SELECT Demodata.testUdfDefault2()。この関数は、パラメーターが提供されなかった場合には、指定したデフォルト値(Accounting Report)を使用します。
————————
動的パラメーターを持つ UDF
SELECT name FROM class WHERE id <= GetSmallest(?,?)
————————
式としての UDF
SELECT 10 + Demodata.Getsmallest(10,20) + 15
————————
パラメーターとしての UDF
SELECT demodata.calculateinterest (10+demodata.getsmallest(3000, 2000), demodata.factorial(2), demodata.testUdfDefault(3))
関連項目
CREATE GROUP
CREATE GROUP ステートメントにより、1 つまたは複数のセキュリティ グループを作成します。
構文
CREATE GROUP グループ名 [ , グループ名 ]...
グループ名 ::= ユーザー定義名
備考
Master ユーザーのみがこのステートメントを実行できます。
このステートメントを実行するには、セキュリティ設定が有効になっている必要があります。
例
次の例では、zengroup という名前のグループが作成されます。
CREATE GROUP zengroup
次の例では、リストを使用して一度に複数のグループを作成します。
CREATE GROUP zen_dev, zen_marketing
関連項目
CREATE INDEX
CREATE INDEX ステートメントを使用して、指定されたテーブルに名前付きインデックスを作成します。
構文
CREATE [ UNIQUE | PARTIAL ] [ NOT MODIFIABLE ] INDEX インデックス名 [ USING インデックス番号 ] [ IN DICTIONARY ] ON テーブル名 [ インデックス定義 ]
インデックス名 ::= ユーザー定義名
インデックス番号 ::= ユーザー定義値 (0 から 118 までの整数)
テーブル名 ::= ユーザー定義名
インデックス定義 ::= ( インデックス セグメント定義 [ , インデックス セグメント定義 ]... )
インデックス セグメント定義 ::= 列名 [ ASC | DESC ]
備考
VARCHAR 型の列が CHAR 型の列と異なるのは、長さバイト(Btrieve lstring)またはゼロ終端バイト(Btrieve zstring)のいずれかが予約されており、そのため有効な記憶域が 1 バイト増える点です。言い換えると、CHAR (100) の列を作成すると、レコード内で 100 バイトを占めます。VARCHAR (100) は 101 バイトを占めます。NVARCHAR 型の列が NCHAR 型の列と異なるのは、ゼロ終端文字が予約されており、そのため有効な記憶域が 2 バイト増える点です。言い換えると、NCHAR(50) の列を作成すると、レコード内で 100 バイトを占めます。NVARCHAR(50) の列は 102 バイトを占めます。
Zen でインデックスを作成する場合、その処理は、ステートメントに IN DICTIONARY か USING、またはその両方が含まれているかどうかによって変わります。結果をまとめた表を次に示します。
操作 | 処理と結果 | 追加情報 |
|---|---|---|
CREATE INDEX | 成功した場合、インデックスはデータ ファイルと X$Index の両方に追加されます。 • データ ファイルにインデックスが定義されていない場合、作成されるインデックスはインデックス 0 になります。 • データ ファイルに 1 つ以上のインデックスが定義されている場合、作成されるインデックスは、未使用のインデックス番号のうち最小の番号になります。 どちらの場合も、同じ番号を持つ新しいインデックスが X$Index に同様に挿入されます。 | |
CREATE INDEX IN DICTIONARY | 成功した場合、インデックスは X$Index にのみ追加されます。データ ファイルには何も挿入されません。 データ ファイルを調べて、どのインデックス番号が使用可能であるかを判定します。 • データ ファイルにインデックスが定義されていない場合、X$Index に挿入されるインデックスの番号は 0 になります。 • データ ファイルに 1 つ以上のインデックスが定義されている場合、データベース エンジンは、追加するインデックスと列およびインデックスの属性が一致するインデックスが X$Index にまだ定義されていないかどうかを確認します。 一致が見つかった場合は、そのインデックス番号を使用して、インデックスが X$Index に追加されます。 一致が見つからない場合は、<データ ファイルのうち最大のインデックス番号>+ 1 がインデックス番号に使用されます。 X$Index にあり、データ ファイルに一致するキーがないインデックスはファントム インデックスと呼ばれ、データベース エンジンでは使用されません。 | IN DICTIONARYを参照してください。 |
CREATE INDEX USING インデックス番号 | 成功した場合、指定したインデックス番号を持つインデックスはデータ ファイルと X$Index の両方に追加されます。 インデックス番号がデータ ファイルまたは X$Index のいずれかで既に使用されている場合は、エラーが返されます。 | USING を参照してください。 |
CREATE INDEX USING インデックス番号 IN DICTIONARY | 成功した場合、指定したインデックス番号を持つインデックスは X$Index にのみ追加されます。データ ファイルには何も挿入されません。 指定したインデックス番号は、データ ファイルには存在するが X$Index には存在せず、列およびインデックスの属性が追加するインデックスと一致する場合、指定したインデックス番号のインデックスが X$Index に追加されます。それ以外はエラーが返されます。 | IN DICTIONARYを参照してください。 |
インデックス セグメント
インデックス セグメントは、インデックス定義に指定されている 1 つの列に対応します。複数セグメントのインデックスは、複数列の組み合わせとして作成されたものです。
次の表で示すように、ファイルに定義するすべてのインデックスで使用できるセグメントの総数は、そのファイルのページ サイズによって異なります。
ページ サイズ(バイト数) | キー セグメントの最大数(ファイル バージョン別) | |||
|---|---|---|---|---|
8.x 以前 | 9.0 | 9.5 | 13.0、16.0 | |
512 | 8 | 8 | 切り上げ2 | 切り上げ2 |
1024 | 23 | 23 | 97 | 切り上げ2 |
1536 | 24 | 24 | 切り上げ2 | 切り上げ2 |
2048 | 54 | 54 | 97 | 切り上げ2 |
2560 | 54 | 54 | 切り上げ2 | 切り上げ2 |
3072 | 54 | 54 | 切り上げ2 | 切り上げ2 |
3584 | 54 | 54 | 切り上げ2 | 切り上げ2 |
4096 | 119 | 119 | 2043 | 1833 |
8192 | N/A1 | 119 | 4203 | 3783 |
16384 | N/A1 | N/A1 | 4203 | 3783 |
1 "N/A" は「適用外」を意味します。 2 「切り上げ」は、ページ サイズを、ファイル バージョンでサポートされる次のサイズへ切り上げることを意味します。たとえば、512 は 1024 に切り上げられ、2560 は 4096 に切り上げるということです。 3 9.5 以降の形式のファイルでは 119 以上のセグメントを指定できますが、インデックスの数は 119 に制限されます。 | ||||
ヌル値を許可する列には考慮も必要です。たとえば、ページ サイズが 4096 バイトのデータ ファイルでは、1 ファイル当たりのインデックス セグメント数は 119 に制限されます。真のヌルがサポートされるインデックス付きのヌル値を許可する列には 2 つのセグメントから成るインデックスが必要なため、1 つのテーブルではインデックス付きのヌル値を許可する列(Btrieve ファイルでは、インデックス付きでヌル値を許可する真のヌル フィールド)は 59 個までしか持てません。ページ サイズが小さくなると、この制限も小さくなります。
ファイル バージョン 7.x 以降では、TRUENULLCREATE がオンに設定されている場合、真のヌルがサポートされます。それより前のファイル形式バージョンを使用しているファイル、または TRUENULLCREATE がオフに設定されているファイルには、真のヌル サポートがないため、この制限はありません。
UNIQUE
UNIQUE インデックス キーは、特定の行に対してインデックスで定義された列の組み合わせがファイル内で重複しないことを保証します。これは、複数セグメントのインデックスの場合には、個々の列が重複しないことを保証しませんし、また要求もしません。
メモ: 次のデータ型以外のすべてのデータ型にインデックスを設定できます。
BIT
BLOB
CLOB
LONGVARBINARY
LONGVARCHAR
NLONGVARCHAR
BIT
BLOB
CLOB
LONGVARBINARY
LONGVARCHAR
NLONGVARCHAR
『Status Codes and Messages』のステータス コード 6008:セグメントが多すぎます。も参照してください。
PARTIAL
ファイル形式バージョンの最大インデックス幅を超える列または列のグループにインデックスを作成するには、CREATE INDEX ステートメントで PARTIAL キーワードを使用します。
部分インデックスは、大きな列のプレフィックスを使用して作成されるか、あるいは小さな列を複数組み合わせて作成されるため、大きな列のプレフィックスを用いた検索の方がより速く実行できます。したがって、WHERE 句で 'WHERE column_name LIKE 'prefix%' のような制限を使用しているクエリは、インデックスを何も使用しない場合とは対照的に、部分インデックスを使用することによって実行が速くなります。
CREATE INDEX ステートメントに PARTIAL キーワードを含めた場合、インデックス列の幅とオーバーヘッドが最大インデックス幅と同等かそれを超えない場合、PARTIAL キーワードは無視され、代わりに標準のインデックスが作成されます。
13.0 以前のファイルの最大インデックス幅は 255 バイトです。16.0 ファイルの場合は 1024 バイトです。
メモ: 幅は列の実際のサイズを指し、オーバーヘッドはヌル インジケーターや文字列の長さなどを指します。
PARTIAL の制限事項
PARTIAL を使用する際には次の制限が適用されます。
• 部分インデックスは、データ型が CHAR または VARCHAR の列にしか追加できません。
• 部分インデックス列は、必ずインデックス定義内の最後のセグメントであるか、あるいはインデックス定義内の唯一のセグメントである必要があります。
部分インデックス列がインデックス内の唯一のセグメントである場合、列のサイズは最大 8,000 バイトにすることができますが、ユーザー データのインデックス セグメントのサイズは、使用しているファイル形式の最大インデックス幅と同じになります。
• エンジンは、厳密な等式を含んでいるクエリや、部分列にかかわる ORDER BY、GROUP BY、JOIN などの照合操作を実行している場合には、部分インデックスを使用しません。
• 部分インデックスは、WHERE 句の次のような形式の制限と照合する場合にのみ使用されます。
WHERE col = 'literal'
WHERE col LIKE 'literal%'
WHERE col = ?
WHERE col LIKE ?
ここで、literal、つまり実引数値にはどのような長さの値も指定できます。部分インデックス列でインデックス処理されたバイト数より短くても長くてもかまいません。LIKE 句の形式が 'prefix%' でない場合、部分インデックスは使用されません。
WHERE 句が前述の制限事項に適合する場合は、実行プランを立てる際に部分インデックスが使用されます。
メモ: ALTER TABLE を使用して部分インデックス列の長さを変更したとき、変更後の長さがインデックスの最大幅に収まるようになった場合、あるいは変更後の長さがインデックスの最大幅を超える場合、ユーザーはインデックスを削除し、必要に応じて再作成する必要があります。
例
次の CREATE PARTIAL INDEX の例は 9.5 ファイル形式に基づいています。
次の例では、データ型とサイズの指定された PartID、PartName、SerialNo、および Description 列を含む、Part_tbl という名前のテーブルが作成されます。
CREATE TABLE part_tbl (partid INT, partname CHAR(50), serialno VARCHAR(200), description CHAR(300));
次に、Description 列を使って、idx_01 という名前の部分インデックスを作成します。
CREATE PARTIAL INDEX idx_01 on part_tbl (description);
インデックスで使用される Description 列は 300 バイトありますが、PARTIAL キーワードを使用することにより、先頭の 255 バイト(オーバーヘッドを含む)だけをプレフィックスとしてインデックスで使用できるようになります。
————————
次の例では、前の例と同じテーブルに idx_02 という部分インデックスを作成します。代わりに、この例では PartId、SerialNo、および Description 列をまとめてインデックスに使用します。
CREATE PARTIAL INDEX idx_02 on part_tbl (partid, serialno, description);
次の表は、どのようにして大きい列がインデックスに割り当てられるかを理解できるよう、インデックス列の詳細を示しています。
列名 | データ型 | サイズ | オーバーヘッド | インデックス内のサイズ |
|---|---|---|---|---|
PartID | Integer | 4 | 4 | |
SerialNo | Varchar | 200 | 1 | 201 |
Description | Char | 300 | 50 | |
インデックスの合計サイズ | 255 | |||
NOT MODIFIABLE
この属性は、インデックスが変更されないようにします。複数セグメントのインデックスでは、この属性はすべてのセグメントに適用されることに留意してください。このセグメントのいずれかを変更しようとすると、ステータス コード 10:キー フィールドは変更できません。が返されます。
次の例では、Person テーブルに変更できないセグメント インデックスが作成されます。
CREATE NOT MODIFIABLE INDEX X_Person on Person(ID, Last_Name)
USING
インデックスを作成するときにインデックス番号を制御するには、このキーワードを使用します。インデックス番号を制御することは、リレーショナル エンジンを使ってデータにアクセスする場合だけでなく、MicroKernel エンジンを使って直接データ ファイルからアクセスする場合にも重要です。
インデックスを作成すると、データ ファイルと X$Index の両方に指定したインデックス番号が挿入されます。
指定したインデックス番号がどちらかのファイルで既に使用されている場合は、エラー コードが返されます。X$Index の場合はステータス コード 5:レコードのキー フィールドに重複するキー値があります。、データ ファイルの場合はステータス コード 6:キー番号パラメーターが無効です。が返されます。
CREATE INDEX "citizen-x" USING 3 On Person (citizenship)
IN DICTIONARY
このキーワードは、基となる物理データは変更しないままで DDF に変更を加えたいことを、データベース エンジンに通知します。この機能を使用すると、対応するデータ ファイルと同期していないテーブルの辞書定義を訂正したり、辞書に定義を作成して既存のデータ ファイルと合致させたりすることができます。これが必要となるのは、ほとんどの場合、Btrieve(トランザクショナル)アプリケーション(DDF を使用しない)によってデータ ファイルが作成され、使用されるときです。その場限りのクエリやレポートでは、リレーショナル エンジンを使用してデータにアクセスする必要があります。
通常、データベース エンジンは DDF とデータ ファイルの完全な同期を保ちます。IN DICTIONARY ステートメントを指定しないでインデックスを作成すると、データベース エンジンは X$Index とデータ ファイルに同じインデックス番号を割り当てます。IN DICTIONARY は、インデックスを X$Index にのみ追加できるようにします。
注意! IN DICTIONARY は強力で高度な機能です。これは、システム管理者によってのみ、もしくは絶対的に必要な場合にのみ使用してください。DDF の変更を基となるデータ ファイルへの変更と並行して行わないと、正しくない結果セット、パフォーマンスの問題、予期しない結果などの重大な問題が生じることがあります。
ファントム インデックス、つまり、DDF にのみ存在しデータ ファイルには存在しないインデックスを作成した場合、IN DICTIONARY を使用しないでそのインデックスを削除しようとすると、ステータス コード 6:キー番号パラメーターが無効です。が返されることがあります。このエラーは、データベース エンジンがデータ ファイルからインデックスを削除しようとしても、そのようなインデックスはデータ ファイルに存在しないために削除できないことから発生します。
インデックスの作成時に、SQL ステートメントで IN DICTIONARY と USING の両方を使用した場合、USING で指定された番号を使用する新しいインデックスは、指定されたインデックス番号のセグメントが SQL 列と合致する場合には、DDF にのみ挿入されます。USING キーワードで指定された番号が SQL 列と合致しないか、またはデータ ファイルに存在しない場合、SQL エンジンは「Btrieve キー定義がインデックス定義と一致しません」というエラー メッセージを返します。これにより、ファントム インデックスが作成されないようになります。
メモ: IN DICTIONARY キーワードをバウンド データベースで使うことはできません。
例
このセクションでは、IN DICTIONARY のいくつかの例を示します。
次の例では、データ ファイルと関連付けられない「デタッチされた」テーブルが作成され、その後でテーブル定義へのインデックスの追加と削除が行われます。このインデックスは、関連付けられる基となる Btrieve インデックスが存在しないため、デタッチされたインデックスとなります。
CREATE TABLE t1 IN DICTIONARY (c1 int, c2 int)
CREATE INDEX idx_1 IN DICTIONARY on t1(c1)
DROP INDEX t1.idx_1 IN DICTIONARY
————————
次の例では、既存のテーブル T1 を使用します。データ ファイルには key1 が定義されていますが、現在のところ X$Index には定義されていません。
CREATE INDEX idx_1 USING 1 IN DICTIONARY on T1 (C2)
関連項目
CREATE PROCEDURE
CREATE PROCEDURE ステートメントにより、新規のストアド プロシージャを作成します。ストアド プロシージャは、あらかじめ定義されデータベース辞書に保存されている SQL ステートメントです。
構文
CREATE PROCEDURE プロシージャ名
( [ パラメーター [, パラメーター ]... ] )
( [ パラメーター [, パラメーター ]... ] )
[ WITH DEFAULT HANDLER | WITH EXECUTE AS 'MASTER' | WITH DEFAULT HANDLER , EXECUTE AS 'MASTER' | WITH EXECUTE AS 'MASTER' , DEFAULT HANDLER ]
as またはセミコロン
プロシージャ ステートメント
プロシージャ名 ::= ユーザー定義名
パラメーター タイプ名 ::= パラメーター名
| パラメーター タイプ パラメーター名
| パラメーター名 パラメーター タイプ
パラメーター タイプ ::= IN | OUT | INOUT | IN_OUT
パラメーター名 ::= :ユーザー定義名
プロシージャ式 ::= 通常の式と同様。ただし、IF 式と ODBC 形式のスカラー関数は使用できない
プロシージャ ステートメント ::= [ ラベル名 : ] BEGIN [ATOMIC] [ プロシージャ ステートメント [ ; プロシージャ ステートメント ]... ] END [ ラベル名 ]
| CLOSE カーソル名
| DELETE WHERE CURRENT OF カーソル名
| 削除ステートメント
| IF プロシージャ検索条件 THEN プロシージャ ステートメント [ ; プロシージャ ステートメント ]... [ ELSE プロシージャ ステートメント [ ; プロシージャ ステートメント ]... ] END IF
| 挿入ステートメント
| LEAVE ラベル名
| OPEN カーソル名
| RETURN [ プロシージャ式 ]
| トランザクション ステートメント
| into 付き選択ステートメント
| 選択ステートメント
| SET 変数名 = プロシージャ式
| 更新ステートメント
| UPDATE SET 列名 = プロシージャ式 [ , 列名 = プロシージャ式 ]... WHERE CURRENT OF カーソル名
| テーブル変更ステートメント
| インデックス作成ステートメント
| テーブル作成ステートメント
| ビュー作成ステートメント
| インデックス削除ステートメント
| テーブル削除ステートメント
| ビュー削除ステートメント
| 権限付与ステートメント
| 権限取消ステートメント
| 設定ステートメント
トランザクション ステートメント ::= コミット ステートメント
| ロールバック ステートメント
| リリース ステートメント
コミット ステートメント ::= COMMIT を参照
ロールバック ステートメント ::= ROLLBACK を参照
リリース ステートメント ::= RELEASE SAVEPOINT を参照
テーブル作成ステートメント ::= CREATE TABLE を参照
テーブル変更ステートメント ::= ALTER TABLE を参照
テーブル削除ステートメント ::= DROP TABLE を参照
インデックス作成ステートメント ::= CREATE INDEX を参照
インデックス削除ステートメント ::= DROP INDEX を参照
ビュー作成ステートメント ::= CREATE VIEW を参照
ビュー削除ステートメント ::= DROP VIEW を参照
権限付与ステートメント ::= GRANT を参照
権限取消ステートメント ::= REVOKE を参照
設定ステートメント ::= SET DECIMALSEPARATORCOMMA を参照
ラベル名 ::= ユーザー定義名
カーソル名 ::= ユーザー定義名
変数名 ::= ユーザー定義名
プロシージャ探索条件 ::= 検索条件と同様。ただし、サブクエリを含む式は使用できない
フェッチ方向 ::= NEXT
sqlstate値 ::= '文字列'
備考
なお、プロシージャでは変数名とパラメーター名はコロン(:)で始まる必要があります。これは、変数やパラメーターを定義するときと使用するときの両方に当てはまります。
ストアド プロシージャが結果セットまたはスカラー値を返す場合は、RETURNS 句が必要です。
RETURNS 句が存在する場合は、エラーが発生したときにプロシージャが引き続き実行されます。デフォルトの動作(この句が存在しない場合)では、SQLSTATE がステートメントによって発生したエラー状態になり、プロシージャが中止されます。
IF ステートメントの最初(または最後)に StmtLabel を使用することは、ANSI SQL 3 の拡張機能です。
PRINT ステートメントは Windows ベースのプラットフォームにのみ適用されます。ほかのオペレーティング システムのプラットフォームでは無視されます。
SQL Editor において、変数パラメーターを使ってストアド プロシージャをテストする唯一の方法は、そのストアド プロシージャを別のストアド プロシージャから呼び出すことです。この手法は、pdate の例で示されています(CREATE PROCEDURE pdate();)。
変数は、ストアド プロシージャ内でのみ SELECT 項目として使用することができます。この手法は、varsub1 の例で示されています(CREATE PROCEDURE varsub1();)。
ストアド プロシージャ内で CREATE DATABASE または DROP DATABASE ステートメントを使用することはできません。
信頼されるストアド プロシージャと信頼されないストアド プロシージャ
信頼されるストアド プロシージャには WITH EXECUTE AS 'MASTER' 句を含めます。信頼されるオブジェクトと信頼されないオブジェクトを参照してください。
メモリ キャッシング
デフォルトで、データベース エンジンはメモリ キャッシュを作成し、SQL セッションの継続期間中、複数のストアド プロシージャを格納します。ストアド プロシージャが実行されると、そのコンパイルされたものがメモリ キャッシュに保持されます。一般的に、キャッシングによって、キャッシュされたプロシージャの次回からの呼び出しのパフォーマンスが向上します。ストアド プロシージャが初めて実行されるときにはキャッシュによってパフォーマンスは向上しません。これは、プロシージャがまだメモリに読み込まれていないためです。
2 つの SET ステートメントがメモリ キャッシュに適用されます。
• SET CACHED_PROCEDURES - キャッシュするプロシージャ数。デフォルト値は 50 です。
• SET PROCEDURES_CACHE - キャッシュに使用するメモリ量。デフォルト値は 5 MB です。
キャッシュの設定やアプリケーションが実行する SQL によっては、過度のメモリ スワッピングやスラッシングが発生するので注意してください。スラッシングはパフォーマンスの低下を招きます。
キャッシングの除外
ストアド プロシージャは以下の条件に当てはまる場合、キャッシュ設定にかかわらず、キャッシュされません。
• ローカルまたはグローバルのテンポラリ テーブルを参照している場合。ローカル テンポラリ テーブルはポンド記号(#)で始まる名前を持ちます。グローバル テンポラリ テーブルは 2 つのポンド記号(##)で始まる名前を持ちます。CREATE (テンポラリ) TABLE を参照してください。
• データ定義言語(DDL)ステートメントが含まれている場合。データ定義ステートメントを参照してください。
• 文字列または文字列を返す式を実行するための EXEC[UTE] ステートメントが含まれている場合。たとえば、次のような例です。EXEC ('SELECT Student_ID FROM ' + :myinputvar)
データ型の制限
次のデータ型は、パラメーターとして渡したり、ストアド プロシージャまたはトリガー内で変数として宣言したりすることはできません。
BFLOAT4 | BFLOAT8 |
MONEY | NUMERICSA |
NUMERICSLB | NUMERICSLS |
NUMERICSTB | NUMERICSTS |
直接対応する ODBC データ型がない Zen データ型を、プロシージャで使用されるように正しくマップする方法については、例を参照してください。
制限
ストアド プロシージャを作成する際、次の制限に注意を払う必要があります。
属性 | 制限 |
|---|---|
トリガーまたはストアド プロシージャで使用可能な列数 | 300 |
ストアド プロシージャのパラメーター リスト内の引数の数 | 300 |
ストアド プロシージャのサイズ | 64 KB |
例
次の例では、ストアド プロシージャ Enrollstudent が作成され、Student ID と Class ID が指定されてレコードが Enrolls テーブルに挿入されます。
CREATE PROCEDURE Enrollstudent(IN :Stud_id INTEGER, IN :Class_Id INTEGER, IN :GPA REAL);
BEGIN
INSERT INTO Enrolls VALUES(:Stud_id, :Class_id, :GPA);
END;
次のステートメントを使用して、ストアド プロシージャを呼び出します。
CALL Enrollstudent(1023456781, 146, 3.2)
次のステートメントを使用して、新しく挿入したレコードを取得します。
SELECT * FROM Enrolls WHERE Student_id = 1023456781
CALL ステートメントは引数を渡してプロシージャを呼び出し、SELECT ステートメントは追加された行を表示します。
————————
この例は、パラメーターにデフォルト値を割り当てる方法を示します。
CREATE PROCEDURE ReportTitle1 (:rpttitle1 VARCHAR(20) = 'Finance Department') RETURNS (Title VARCHAR(20));
BEGIN
SELECT :rpttitle1;
END;
CALL ReportTitle1;
CREATE PROCEDURE ReportTitle2 (:rpttitle2 VARCHAR(20) DEFAULT 'Finance Department', :rptdate DATE DEFAULT CURDATE()) RETURNS (Title VARCHAR(20), Date DATE);
BEGIN
SELECT :rpttitle2, :rptdate;
END;
CALL ReportTitle2( , );
これらのプロシージャは、CALL でパラメーターが提供されなかった場合には、指定したデフォルト値(Finance Department)を使用します。パラメーターを省略することはできますが、プレースホルダーを指定する必要があります。
————————
次のプロシージャでは、呼び出し側から渡された classId パラメーターを使用して Class テーブルを読み取り、講座の登録者数がまだ制限数に達していないことを確認します。
CREATE PROCEDURE Checkmax(in :classid integer);
BEGIN
DECLARE :numenrolled integer;
DECLARE :maxenrolled integer;
SELECT COUNT(*) INTO :numenrolled FROM Enrolls WHERE class_ID = :classid;
SELECT Max_size INTO :maxenrolled FROM Class WHERE id = :classid;
IF (:numenrolled >= :maxenrolled) THEN
PRINT '登録は失敗しました。登録された生徒数が、この講座の制限数に達しました。';
ELSE
PRINT '登録可能です。登録された生徒数は、この講座の制限数にまだ達していません。';
END IF;
END;
CALL Checkmax(101)
COUNT(式) によって、述部にある式の非ヌル値がすべてカウントされるということを覚えておいてください。COUNT(*) ではヌル値を含むすべての値がカウントされます。
————————
ストアド プロシージャを作成するときに OUT パラメーターを使用する例を以下に示します。このプロシージャを呼び出すと、WHERE 句を満たす生徒数が変数 :outval に返されます。
CREATE PROCEDURE ProcOUT (out :outval INTEGER)
AS BEGIN
SELECT COUNT(*) INTO :outval FROM Enrolls WHERE Class_Id = 101;
END;
————————
ストアド プロシージャを作成するときに INOUT パラメーターを使用する例を以下に示します。このプロシージャの呼び出しでは、INPUT パラメーター :IOVAL が要求され、出力の値が変数 :IOVAL に返されます。プロシージャでは、入力と IF 条件に基づいてこの変数の値が設定されます。
CREATE PROCEDURE ProcIODATE (INOUT :IOVAL DATE)
AS BEGIN
IF :IOVAL = '1982-03-03' THEN
SET :IOVAL ='1982-05-05';
ELSE
SET :IOVAL = '1982-03-03';
END IF;
END;
上記のプロシージャは、call prociodate('1982-03-03') のように、リテラル値を使って呼び出すことはできません。これには OUTPUT パラメーターが必要になります。最初に ODBC 呼び出しを使ってパラメーターをバインドする必要があります。そうでなければ、次に示すように、このプロシージャを呼び出す別のプロシージャを作成することで、プロシージャのテストを行えます。
CREATE PROCEDURE pdate();
BEGIN
DECLARE :a DATE;
CALL prociodate(:a);
PRINT :a;
END
CALL pdate
————————
次の例は、プロシージャで RETURNS 句を使用する方法を示します。この例では、Class テーブルの中で、Start Date が、CALL ステートメントで渡される日付と等しいデータがすべて返されます。
CREATE PROCEDURE DateReturnProc(IN :PDATE DATE)
RETURNS(
DateProc_ID INTEGER,
DateProc_Name CHAR(7),
DateProc_Section CHAR(3),
DateProc_Max_Size USMALLINT,
DateProc_Start_Date DATE,
DateProc_Start_Time TIME,
DateProc_Finish_Time TIME,
DateProc_Building_Name CHAR(25),
DateProc_Room_Number UINTEGER,
DateProc_Faculty_ID UBIGINT
);
BEGIN
SELECT ID, Name, Section, Max_Size, Start_Date, Start_Time, Finish_Time, Building_Name, Room_Number, Faculty_ID FROM Class WHERE Start_Date = :PDATE;
END;
CALL DateReturnProc('1995-06-05')
RETURNS 句内のユーザー定義名は、この例で示されているように、選択リストに現れる列名と同じ名前にする必要がないことに注目してください。
————————
次の例は、位置付け DELETE に適用される WHERE CURRENT OF 句の使い方を示します。
CREATE PROCEDURE MyProc(IN :CourseName CHAR(7)) AS
BEGIN
DECLARE c1 CURSOR FOR SELECT name FROM course WHERE name = :CourseName FOR UPDATE;
OPEN c1;
FETCH NEXT FROM c1 INTO :CourseName;
DELETE WHERE CURRENT OF c1;
CLOSE c1;
END;
CALL MyProc('HIS 305')
(DELETE の WHERE 句の中で SELECT を使用した場合、それは位置付け DELETE ではなく検索済み DELETE になるので注意してください。)
————————
次の例は、変数(:i)を SELECT 項目として使用する方法を示します。例では、table1 はまだ存在しないものとします。person テーブルの、ID が 950000000 より大きいすべてのレコードが選択され、table1 の col2 に挿入されます。col1 には、WHILE ループで定義されるとおり、値 0、1、2、3 または 4 が格納されます。
CREATE TABLE table1 (col1 CHAR(10), col2 BIGINT);
CREATE PROCEDURE varsub1();
BEGIN
DECLARE :i INT;
SET :i = 0;
WHILE :i < 5 DO
INSERT INTO table1 (col1, col2) SELECT :i , A.ID FROM PERSON A WHERE A.ID > 950000000;
SET :i = :i + 1;
END WHILE;
END
CALL varsub1
SELECT * FROM table1
-- 110 行を返します
————————
一連のステートメントがすべて成功するか失敗するように、ATOMIC を使用してステートメントを 1 つにまとめる例を以下に示します。ATOMIC はストアド プロシージャ、ユーザー定義関数、またはトリガーの本体でのみ使用できます。
最初のプロシージャでは ATOMIC を指定せず、2 番目のプロシージャで指定します。
CREATE TABLE t1 (c1 INTEGER)
CREATE UNIQUE INDEX t1i1 ON t1 (c1)
CREATE PROCEDURE p1();
BEGIN
INSERT INTO t1 VALUES (1);
INSERT INTO t1 VALUES (1);
END;
CREATE PROCEDURE p2();
BEGIN ATOMIC
INSERT INTO t1 VALUES (2);
INSERT INTO t1 VALUES (2);
END;
CALL p1()
CALL p2()
SELECT * FROM t1
どちらのプロシージャも、重複のないインデックスに重複する値を挿入しようとするためにエラーが返されます。
プロシージャ p1 内の最初の INSERT ステートメントは成功しますが、2 番目のステートメントは失敗するので、t1 には 1 レコードのみが格納されるという結果になります。同様に、プロシージャ p2 内の最初の INSERT ステートメントは成功しますが、2 番目のステートメントは失敗します。ただし、プロシージャ p2 では ATOMIC が使用されるため、エラーが発生すると、プロシージャ p2 における実行内容はすべてロール バックされます。
————————
次の例では、ストアド プロシージャを使用して 2 つのテーブルを作成し、デフォルト値を設定した 1 行をそれぞれのテーブルに挿入します。次に、セキュリティを有効にしてユーザー user1 に権限を与えます。
CREATE PROCEDURE p1();
BEGIN
CREATE TABLE t1 (c1 INT DEFAULT 10, c2 INT DEFAULT 100);
CREATE TABLE t2 (c1 INT DEFAULT 1 , c2 INT DEFAULT 2);
INSERT INTO t1 DEFAULT VALUES;
INSERT INTO t2 DEFAULT VALUES;
SET SECURITY = larry;
GRANT LOGIN TO user1 u1pword;
GRANT ALL ON * TO user1;
END;
CALL p1
SELECT * FROM t1
-- 10、100 を返します
SELECT * FROM t2
-- 1、2 を返します
メモ: ストアド プロシージャで GRANT LOGIN ステートメントを使用する場合は、ユーザー名とパスワードをコロンではなく空白文字で区切る必要があります。コロン文字は、ストアド プロシージャ内でローカル変数を識別するために予約されています。
————————
次の例では、ストアド プロシージャを使用してユーザー user1 の権限を取り消し、前の例で作成した 2 つのテーブルを削除してデータベース セキュリティを無効にします。
CREATE PROCEDURE p3();
BEGIN
REVOKE ALL ON t1 FROM user1;
REVOKE ALL ON t2 FROM user1;
DROP TABLE t1;
DROP TABLE t2;
SET SECURITY = NULL;
END;
CALL p3
SELECT * FROM t1 -- テーブルが見つからないというエラーを返します
SELECT * FROM t2 -- テーブルが見つからないというエラーを返します
————————
次の例は、カーソル内をループする方法を示します。
CREATE TABLE atable (c1 INT, c2 INT)
INSERT INTO atable VALUES (1,1)
INSERT INTO atable VALUES (1,2)
INSERT INTO atable VALUES (2,2)
INSERT INTO atable VALUES (2,3)
INSERT INTO atable VALUES (3,3)
INSERT INTO atable VALUES (3,4)
CREATE PROCEDURE pp();
BEGIN
DECLARE :i INTEGER;
DECLARE c1Bulk CURSOR FOR SELECT c1 FROM atable ORDER BY c1 FOR UPDATE;
OPEN c1Bulk;
BulkLinesLoop:
LOOP
FETCH NEXT FROM c1Bulk INTO :i;
IF SQLSTATE = '02000' THEN
LEAVE BulkLinesLoop;
END IF;
UPDATE SET c1 = 10 WHERE CURRENT OF c1Bulk;
END LOOP;
CLOSE c1Bulk;
END
CALL pp
-- 正常終了
SELECT * FROM atable
-- 6 行を返します
————————
次の例では、InParam という名前の信頼されるストアド プロシージャを作成します。その後、Master ユーザーが User1 に対し、InParam の EXECUTE および ALTER 権限を与えます。この例は、テーブル t99 が存在し、テーブルに INTEGER 型の 2 つの列があることを前提としています。
CREATE PROCEDURE InParam(IN :inparam1 INTEGER, IN :inparam2 INTEGER) WITH DEFAULT HANDLER, EXECUTE AS 'Master' AS
BEGIN
INSERT INTO t99 VALUES(:inparam1 , :inparam2);
END;
GRANT ALL ON PROCEDURE InParam TO User1
Master および User1 は、このプロシージャを呼び出せるようになりました(たとえば、CALL InParam(2,4))。
————————
次の例は、直接対応する ODBC データ型がない Zen データ型を、プロシージャで使用されるように正しくマップする方法を示します。データ型 NUMERICSA および NUMERICSTS は、直接対応がないデータ型なので、代わりに NUMERIC にマップされます。
CREATE TABLE test1 (id identity, amount1 numeric(5,2), amount2 numericsa(5,2), amount3 numericsts(5,2))
CREATE PROCEDURE ptest2 (IN :numval1 numeric(5,2), IN :numval2 numeric(5,2), IN :numval3 numeric(5,2))
AS
BEGIN
Insert into test1 values(0, :numval1, :numval2, :numval3);
END;
CALL ptest2(100.10, 200.20, 300.30)
SELECT * FROM test1
プロシージャは、amount 値がすべて NUMERIC としてプロシージャに渡されるにもかかわらず、これらを CREATE TABLE ステートメントで定義された Zen データ型に従って正しく書式指定します。データ型のマップについては、Zen で使用できるデータ型を参照してください。
ストアド プロシージャの使用
一例として、CALL foo(a, b, c) は、パラメーター a、b、および c を持つストアド プロシージャ foo を実行します。パラメーターはいずれも動的パラメーター('?')にできます。これは、OUTPUT パラメーターおよび INOUT パラメーターの値を取り出す場合は必須です。たとえば、{CALL foo(?, ?, 'TX')} のように指定します。ソース コードでは、中かっこは省略可能です。
以下は、現バージョンの Zen におけるストアド プロシージャのしくみです。
• トリガー(CREATE TRIGGER、DROP TRIGGER)が、ストアド プロシージャの形式としてサポートされます。このサポートには、テーブル、プロシージャ、およびデータベースに対するトリガーの依存性の監視が含まれます。CREATE PROCEDURE および CREATE TRIGGER は、ストアド プロシージャまたはトリガーの本体では使用できません。
• CONTAINS、NOT CONTAINS、BEGINS WITH はサポートされていません。
• LOOP:事後条件ループはサポートされていません(REPEAT...UNTIL)。
• ELSEIF:条件形式には IF ... THEN ... ELSE が使用されます。ELSEIF はサポートされていません。
全般的なストアド プロシージャ エンジンの制約
ストアド プロシージャを使用する前に、次に挙げる制約を確認してください。
• 修飾子は、CREATE PROCEDURE でも CREATE TRIGGER でもサポートされていません。
• ストアド プロシージャ変数名の最大長は半角 128 文字です。
• CREATE PROCEDURE または CREATE TRIGGER のとき、構文の検証は部分的にのみ行われます。列名は実行時まで確認されません。
• 現在は、式が使用されているすべての場所でサブクエリを使用できるわけではありません。たとえば、set :arg = SELECT MIN(sal) FROM emp を使用する UPDATE ステートメントはサポートされません。ただし、このサブクエリを SELECT min(sal) INTO :arg FROM emp のように書き直すことができます。
• デフォルトのエラー ハンドラーのみがサポートされています。
SQL 変数とパラメーターの制約
• 変数名はコロン(:)またはアットマーク(@)で始まる必要があります。これによって、ストアド プロシージャのパーサが変数と列名を区別できるようになります。
• 変数名は、大文字と小文字が区別されません。
• セッション変数はサポートされていません。変数はプロシージャに対してローカルです。
カーソルの制約
• 位置付け UPDATE はテーブル名を受け入れません。
• グローバル カーソルはサポートされていません。
Long データを使用する際の制約
• Long データを引数として埋め込みプロシージャ(別のプロシージャを呼び出すプロシージャ)に渡すと、データは切り捨てられて 65500 バイトになります。
• プロシージャとの間でやり取りされる Long データの引数は、合計 2 MB に制限されています
Long データは、内部的にはデータ長の制限なしにカーソル間でコピーできます。Long データ列をステートメントからフェッチして別のステートメントに挿入する場合、制約はありません。ただし、1 つの Long データ変数に対して複数の宛先が要求される場合は、最初の宛先テーブルのみが複数の PutData 呼び出しを受け取ります。残りの列は切り捨てられ、最初の 65500 バイトになります。これは ODBC GetData のメカニズムの制約です。
関連項目
CREATE TABLE
CREATE TABLE ステートメントにより、データベース内に新しいテーブルを作成します。
CREATE TABLE には、最小またはコア SQL 準拠よりも高度な機能が含まれています。CREATE TABLE では参照整合性機能がサポートされます。Zen は、ColIDList サポートを除いて、SQL 92 にほぼ準拠しています。
CREATE TABLE ステートメントを使用してテンポラリ テーブルを作成することもできます。CREATE (テンポラリ) TABLE を参照してください。
注意! 同じディレクトリに、ファイル名が同一で拡張子のみが異なるようなファイルを置かないでください。たとえば、同じディレクトリ内に Invoice.btr と Invoice.mkd というテーブル(データ ファイル)を作成しないでください。このような制限が設けられているのは、データベース エンジンがさまざまな機能でファイル名のみを使用し、ファイルの拡張子を無視するためです。ファイルの識別にはファイル名のみが使用されるため、ファイルの拡張子だけが異なるファイルは、データベース エンジンでは同一のものであると認識されます。
構文
( テーブル要素 [ , テーブル要素 ]... )
テーブル名 ::= ユーザー定義名
個数 ::= ユーザー定義値(リンク重複インデックス キーを追加するために予約しておくポインタの数を設定します)
テーブル要素 ::= 列定義 | テーブル制約定義
列名 ::= ユーザー定義名
桁数 ::= 整数
小数位 ::= 整数
デフォルト値の式 ::= デフォルト値の式 + デフォルト値の式
| デフォルト値の式 - デフォルト値の式
| デフォルト値の式 * デフォルト値の式
| デフォルト値の式 / デフォルト値の式
| デフォルト値の式 & デフォルト値の式
| デフォルト値の式 | デフォルト値の式
| デフォルト値の式 ^ デフォルト値の式
| ( デフォルト値の式 )
| -デフォルト値の式
| +デフォルト値の式
| ~デフォルト値の式
| ?
| リテラル
| スカラー関数
| { fn スカラー関数 }
| USER
| NULL
リテラル ::= '文字列' | N'文字列'
| 数字
| { d '日付リテラル' }
| { t '時刻リテラル' }
| { ts 'タイムスタンプ リテラル' }
列制約定義 ::= [ CONSTRAINT 制約名 ] 列制約
制約名 ::= ユーザー定義名
列制約 ::= NOT NULL
| NOT MODIFIABLE
| UNIQUE
| REFERENCES テーブル名 [ ( 列名 ) ] [ 参照アクション ]
テーブル制約定義 ::= [ CONSTRAINT 制約名 ] テーブル制約
REFERENCES テーブル名 [ ( 列名 [ , 列名 ]... ) ] [ 参照アクション ]
参照アクション ::= 参照更新アクション [ 参照削除アクション ]
| 参照削除アクション [ 参照更新アクション ]
照合順序名 ::= '文字列'
備考
CREATE TABLE ステートメントで作成されるインデックスは、IDENTITY、SMALLIDENTITY、BIGIDENTITY、主キー、および外部キーのみです。その他のインデックスは CREATE INDEX ステートメントで作成する必要があります。
外部キー制約名は、辞書内で固有の名前でなければなりません。その他の制約名はすべて、常駐するテーブル内で固有の名前であり、列とは異なる名前でなければなりません。
主キー名が省略された場合は、キー内の最初の列名に接頭辞 "PK_" を付けた名前が制約名として使用されます。
参照列が一覧にない場合は、デフォルトでは参照されるテーブルの主キーが参照の対象になります。主キーが使用できない場合は、"キーがありません" というエラーが返されます。ターゲット列を列挙すると、このような状況を回避できます。
外部キー名が省略された場合は、キー内の最初の列名に接頭辞 "FK_" を付けた名前が制約名として使用されます。
UNIQUE 制約が省略された場合は、キー内の最初の列名に接頭辞 "UK_" を付けた名前が制約名として使用されます。
NOT MODIFIABLE 制約が省略された場合は、キー内の最初の列名に接頭辞 "NM_" を付けた名前が制約名として使用されます。(NOT MODIFIABLE が使用されている場合は、列に一意でない変更不可能なインデックスが作成されます。このインデックスは、NM_列名となります。)
NOT NULL 制約が省略された場合は、キー内の最初の列名に接頭辞 "NN_" を付けた名前が制約名として使用されます。
外部キーが同じテーブルの主キーを参照する場合があります。このキーは自己参照キーと呼ばれます。
CREATE TABLE が成功して USING 句が指定されていない場合、作成されたテーブルのデータ ファイル名は xxx.mkd になります。xxx は指定したテーブル名です。物理ファイルの xxx.mkd が既に存在する場合は xxxnnn.mkd という名前の新しいファイルが作成されます。nnn は一意の番号です。テーブルが既に存在する場合、そのテーブルは置換されず、エラー - 1303 "テーブルは既に存在します" が返されます。テーブルを置換する前に削除する必要があります。
SYSDATA_KEY_2 キーワードを指定した CREATE TABLE ステートメントでは、ファイルは自動的に 13.0 ファイル形式で作成されます。新しいファイルはシステム データ v2 を使用するため、仮想列 sys$create および sys$update をクエリで使用できるようになります。ファイル形式が 16.0 の場合、バージョンは変更されません。詳細については、システム データ v2 のアクセスを参照してください。
SYSDATA_KEY_2 キーワードと一緒に IN DICTIONARY を使用した場合、CREATE TABLE ステートメントは SYSDATA_KEY_2 を無視するため、新しいテーブルでは sys$create および sys$update 仮想列を使用できません。
レコード サイズの制限
データ レコードの固定長部分の合計サイズは、65535 バイトを超えてはいけません。データ レコードの固定長部分は次の要素で構成されます。
• 固定サイズのすべての列(LONGVARCHAR 型、LONGVARBINARY 型、および NLONGVARCHAR 型以外のすべての列)
• ヌル値を許可する各列について 1 バイト
• 各可変長列(LONGVARCHAR 型、LONGVARBINARY 型、または NLONGVARCHAR 型の列)について 8 バイト
この制限を超えるテーブルの作成を試みるか、結果としてテーブルが制限を超えるような変更を試みると、Zen はステータス コード -3016 "テーブルの最大固定長行サイズを超えています" を返します。
新しいテーブルを作成する前にレコードの固定長部分のバイト単位のサイズを調べるには、次の計算式を使用します。
(固定長列のバイト単位の記憶域サイズ合計)+(ヌル値を許可する列の数)+(8 * 可変長列の数) = バイト単位のレコード サイズ
既存データ ファイルのレコードの固定長部分のサイズを調べたい場合は、BUTIL -STAT コマンドを使用すれば、この情報を示すレポートを表示できます。
レコード サイズの制限の例
次のような列が定義されているテーブルがあるとします。
データ型 | このデータ型の列数 | ヌル値を許可 |
|---|---|---|
VARCHAR(216) | 1 | 可 |
VARCHAR(213) | 5 | すべての列 |
CHAR(42) | 1494 | すべての列 |
VARCHAR にはそれぞれ余分に 2 バイトが予約されます。先頭のヌル インジケーター用の 1 バイトと末尾の 1 バイトです。末尾のバイトは、VARCHAR が ZSTRING として実装されるためです。CHAR にはそれぞれ先頭のバイトがヌル インジケーター用に予約されます。
したがって、レコード サイズは 1 x 218 + 5 x 215 + 1494 x 43 = 65535 バイトになります。
この例では、別の列がどのような長さであっても、固定長制限を超えないで追加することはできません。
削除規則
外部キー制約を持つ ON DELETE キーを含めることで、外部キー値が参照する親テーブルの行を削除しようとする場合に Zen により適用される削除規則を定義することができます。選択可能な削除規則は次のとおりです。
• CASCADE を指定した場合、Zen はカスケード削除規則を使用します。ユーザーが親テーブルの行を削除すると、データベース エンジンによって従属テーブルの対応する行が削除されます。
• RESTRICT を指定した場合、Zen は削除制限規則を使用します。外部キー値が親テーブルの行を参照している場合、ユーザーはその行を削除できません。
削除規則を指定しない場合、Zen はデフォルトで制限規則を適用します。
DELETE CASCADE は注意して使用してください。Zen では、自己参照するテーブルに対し、循環するカスケード削除を使用できます。『Advanced Operations Guide』の削除カスケードに記載されている例を参照してください。
更新規則
Zen は更新制限規則を適用します。この規則は、親テーブルが外部キー値と合致する主キー値を持たない場合、その外部キー値を含む行が追加されないようにします。この規則が適用されるかどうかは、更新規則を明示的に指定できるオプションの ON UPDATE 句の使用によります。
IN DICTIONARY
ALTER TABLE の IN DICTIONARY の解説を参照してください。
USING
USING キーワードを使用すると、特定のデータ ファイルを CREATE TABLE または ALTER TABLE アクションと関連付けることができます。
Zen は接続に名前付きデータベースを必要とするので、指定するパス名は常に単純なファイル名であるか、または相対パスとファイル名でなければなりません。パスは常に、接続する名前付きデータベースに指定された最初のデータ パスとの相対になります。
渡されたパス名およびファイル名は、ステートメントの準備ができたときに部分的に検証されます。
パス名を指定するときは、次の規則に従う必要があります。
• テキストは、文法定義で示されているように、一重引用符で囲まなければなりません。
• テキストの長さは、使用しているメタデータのバージョンの制限を超えることはできません。エントリは入力したまま正確に Xf$Loc に格納されます(ただし、後続の空白は切り捨てられ、無視されます)。Xf$Loc(メタデータ バージョン 1 用)および Xf$Loc(メタデータ バージョン 2 用)を参照してください。
• パスは、単純な相対パスでなければなりません。サーバーまたはボリュームを参照するパスは許可されません。
• 相対パスには、1 つのピリオド(現在のディレクトリ)、2 つのピリオド(親ディレクトリ)、円記号、またはこれら 3 つのあらゆる組み合わせを含めることができます。ただし、パスは SQL テーブル名を表すファイル名を含んでいる必要があります。つまり、パス名は円記号やディレクトリ名で終わってはいけないということです。ファイル名は、相対パス付きで指定されたファイル名も含めてすべて、名前付きデータベースの設定で定義されている最初のデータ パスとの相対になります。
次の機能は、利便性と使いやすさを提供します。
• ルート ベースの相対パスを使用できます。たとえば、最初のデータ パスを D:\mydata\demodata とした場合、Zen は次のステートメント内のパス名を D:\temp\test123.btr と解釈します。
CREATE TABLE t1 USING '\temp\test123.btr' (c1 int)
• 相対パス内の円記号文字は、Unix スタイル(/)と Windows の円記号(\)のどちらでも使用できます。必要であれば、2 種類の記号を混在させて使用することもできます。ディレクトリ構造スキーマは知っているかもしれませんが、接続されているサーバーの種類を知っている(あるいは管理している)とは限らないので、これは便利な機能です。パスは入力したとおりに X$File に格納されます。Zen エンジンは、パスを利用してファイルを開く際、円記号文字を適切なプラットフォームのタイプに変換します。また、データ ファイルはサポートされるすべてのプラットフォーム間でバイナリ互換性を共有するため、ディレクトリ構造がプラットフォーム間で同一である(および、パスに基づくファイル名が相対パスで指定されている)限りは、データベース ファイルおよび DDF をこれらに変更を加えることなく、あるプラットフォームから別のプラットフォームへ移動することができます。これにより、標準化されたデータベース スキーマを使用したクロス プラットフォームの展開が可能になります。
• 相対パスを指定するとき、USING 句のディレクトリ構造は既存である必要はありません。Zen は必要に応じて、USING 句のパスのためにディレクトリを作成します。
USING 句を使用して、テーブルと関連付けるデータ ファイルの物理的な場所を指定します。これは、既存データ ファイルのテーブル定義を作成するとき、または新しいデータ ファイルの名前や物理的な場所を明示的に指定したい場合は必須です。
USING 句を使用しないと、Zen により、テーブル名を基に拡張子 .mkd の一意のファイル名が生成され、データベースのデータ ファイル パスに指定されている最初のディレクトリにファイルが作成されます。
USING 句が既存のデータ ファイルを示す場合は、Zen により DDF にテーブルが作成され、SQL_SUCCESS_WITH_INFO が返されます。返された情報メッセージは、辞書エントリが既存のデータ ファイルをポイントするようになったことを示します。CREATE TABLE で SQL_SUCCESS のみが返されるようにしたい場合は、CREATE ステートメントで IN DICTIONARY を指定します。WITH REPLACE を指定する(下記参照)と、同一名の既存データ ファイルはすべて破棄され、新規に作成したファイルで上書きされます。
メモ: 既存のデータ ファイルを指定した場合、Zen は成功を表すステータス コードを返します。
既存のデータ ファイルに対してリレーショナル インデックス定義を作成する(たとえば、IDENTITY 型の列定義を含む CREATE TABLE USING を使用する)たびに、Zen はそのファイルに定義されている Btrieve インデックスを自動的にチェックし、既存の Btrieve インデックスがリレーショナル インデックス定義のパラメーターのセットを提供しているかどうかを判定します。既存の Btrieve インデックスと新しい定義が一致する場合は、リレーショナル インデックス定義と既存の Btrieve インデックスの間に関連付けが作成されます。一致するインデックスがない場合は、Zen は新しいインデックス定義を作成し、IN DICTIONARY が使用されていなければ、ファイルに新しいインデックスを作成します。
WITH REPLACE
WITH REPLACE が USING キーワードと共に指定されたときはいつでも、Zen は既存のファイル名を指定されたファイル名で自動的に上書きします。オペレーティング システムがファイルの上書きを許している場合、ファイルは常に上書きされます。WITH REPLACE はデータ ファイルにのみ作用します。DDF には作用しません。
WITH REPLACE を使用する際には次の規則が適用されます。
• WITH REPLACE は USING と併せてのみ使用できます。
• IN DICTIONARY と一緒に使用すると、WITH REPLACE は無視されます。IN DICTIONARY は DDF にのみ作用することを指定するものだからです。
CREATE TABLE ステートメントで WITH REPLACE を使用した場合、USING 句で指定された場所にファイルが存在すると、Zen は新規データ ファイルを作成してその既存ファイルと置き換えます。Zen は、同じ名前を持つ元のファイルに格納されているデータをすべて破棄します。WITH REPLACE を使用していないとき、指定された場所にファイルが存在すると、Zen はステータス コードを返し、新しいファイルを作成しません。ただし、テーブル定義は DDF に追加されます。
WITH REPLACE はデータ ファイルにのみ作用します。辞書内のテーブル定義には作用しません。
DCOMPRESS
DCOMPRESS オプションは、ディスク上のファイル サイズを減らすために、テーブルのデータ ファイルがレコード圧縮を使用することを指定します。次の例では、レコード圧縮を行う、ページ サイズが 1024 バイトのテーブルが作成されます。
CREATE TABLE t1 DCOMPRESS PAGESIZE=1024 (c1 INT DEFAULT 10, c2 CHAR(10) DEFAULT 'abc')
詳細については、『Advanced Operations Guide』のレコードおよびページ圧縮を参照してください。
PCOMPRESS
PCOMPRESS オプションは、指定したテーブルのデータ ファイルがページ圧縮を使用することを指定します。次の例では、ページ圧縮を行う、ページ サイズが 1024 バイトのテーブルが作成されます。
CREATE TABLE t1 PCOMPRESS PAGESIZE=1024 (c1 INT DEFAULT 10, c2 CHAR(10) DEFAULT 'abc')
詳細については、『Advanced Operations Guide』のレコードおよびページ圧縮を参照してください。
PAGESIZE
PAGESIZE オプションは、指定したテーブルのデータ ファイルが使用するページのサイズ バイト数を指定します。サイズの値には、ファイル バージョンに応じて次のような値を指定できます。
• 512 – 4096:9.0 より前のファイル バージョンの場合(512 バイトの倍数で最大 4096 バイト)
• 512、1024、1536、2048、2560、3072、3584、4096、または 8192:ファイル バージョンが 9.0 の場合
• 1024、2048、4096、8192、または 16384:ファイル バージョンが 9.5 の場合
• 4096、8192 または 16384(ファイル バージョンが 13.0 および 16.0 の場合)
次の例では、ファイル圧縮を行う、ページ サイズが 8192 バイトのテーブルが作成されると共に、相対パスによって識別される特定のデータ ファイル、..\data1.mkd の作成が指定されます。
CREATE TABLE t1 DCOMPRESS PAGESIZE=8192 USING '..\data1.mkd' (c1 INT DEFAULT 10, c2 CHAR(10) DEFAULT 'abc')
LINKDUP
複数のレコードが、インデックス キーに同一の重複した値を持つことができます。重複キー値を持つレコードを記憶しておく 2 つの方法は、リンク重複(linkdup)および繰り返し重複と呼ばれますリンク重複と繰り返し重複の詳細については、『Advanced Operations Guide』の重複キーの操作方法を参照してください。
LINKDUP キーワードが指定されていない場合、CREATE INDEX ステートメントは繰り返し重複を使用します。
物理レコード内で、リンク重複インデックスごとに 8 バイトが余分に必要になります。LINKDUP キーワードを使用すると、これ以降に作成するリンク重複インデックス用にこれらの余分なバイトを予約することができます。
したがって、LINKDUP キーワードが指定されている場合は、以下が適用されます。
• CREATE INDEX ステートメントは、ポインター数に指定した値に達するまではリンク重複方法を使用します。
• ポインター数に指定した値に達したら、CREATE INDEX ステートメントは繰り返し重複方法を使用します。
• ポインター数に指定した値に達しているとき、リンク重複インデックスを削除すると、CREATE INDEX ステートメントは次のキーに対してリンク重複方法を使用します。
• CREATE INDEX ステートメントは、リンク重複キー用のポインターが予約されていない場合には繰り返し重複キーを作成できません。
例
以下の例では、CREATE TABLE のさまざまな使用法を示します。
次のような構文では、指定されたデータ型の Student_ID、Transaction_Number、Log、Amount_Owed、Amount_Paid、Registrar_ID、および Comments の列から成る、Billing という名前のテーブルが作成されます。
CREATE TABLE Billing
(Student_ID UBIGINT,
Transaction_Number USMALLINT,
Log TIMESTAMP,
Amount_Owed DECIMAL(6,2),
Amount_Paid DECIMAL(6,2),
Registrar_ID DECIMAL(10,0),
Comments LONGVARCHAR)
————————
この例では、ID、Dept_Name、Designation、Salary、Building_Name、Room_Number、および Rsch_Grant_Amount の列から成り、列 ID に基づく主キーを持つ Faculty という名前のテーブルがデータベースに作成されます。
CREATE TABLE Faculty
(ID UBIGINT,
Dept_Name CHAR(20) CASE,
Designation CHAR(10) CASE,
Salary CURRENCY,
Building_Name CHAR(25) CASE,
Room_Number UINTEGER,
Rsch_Grant_Amount DOUBLE,
PRIMARY KEY(ID))
次の例では、Name 列にインデックスを作成し、変更不可を指定します。Name 列のデータは変更できません。
CREATE TABLE organizations
(Name LONGVARCHAR NOT MODIFIABLE,
Advisor CHAR(30),
Number_of_people INTEGER,
Date_started DATE,
Time_started TIME,
Date_modified TIMESTAMP,
Total_funds DOUBLE,
Budget DECIMAL(2,2),
Avg_funds REAL,
President VARCHAR(20) CASE,
Number_of_executives SMALLINT,
Number_of_meetings TINYINT,
Office UTINYINT,
Active BIT,)
————————
次の例では、生徒の住所を保存するために StudentAddress というテーブルが必要であるとします。Student テーブルの id 列を主キーに変更してから、Student を主テーブルとして参照する StudentAddress テーブルを作成する必要があります(Student テーブルは Demodata サンプル データベースの一部です)。StudentAddress テーブルの作成方法を 4 種類示します。
まず、Student テーブルの id 列を主キーにします。
ALTER TABLE Student ADD PRIMARY KEY (id)
次のステートメントは、DELETE CASCADE 規則を使って、Student テーブルの id 列を参照する外部キーを持つ StudentAddress テーブルを作成します。これは、Student テーブル(この場合、Student は親テーブルになる)から行が削除されるときはいつも、StudentAddress テーブル内でその行と同じ id を持つすべての行も削除されることを示します。
CREATE TABLE StudentAddress (id UBIGINT REFERENCES Student (id) ON DELETE CASCADE, addr CHAR(128))
次のステートメントは、DELETE RESTRICT 規則を使って、Student テーブルの id 列を参照する外部キーを持つ StudentAddress テーブルを作成します。これは、Student テーブルから行が削除されたとき、その行と同じ id を持つ行が StudentAddress テーブルに存在する場合は常に、エラーが発生することを示します。親テーブルである Student テーブルの行を削除するには、事前に StudentAddress テーブルでその id を持つ行をすべて明示的に削除する必要があります。
CREATE TABLE StudentAddress (id UBIGINT REFERENCES Student (id) ON DELETE RESTRICT, addr CHAR(128))
次のステートメントは、UPDATE RESTRICT 規則を使って、Student テーブルの id 列を参照する外部キーを持つ StudentAddress テーブルを作成します。これは、Student テーブルに存在しない id を持つ行が StudentAddress テーブルに追加された場合は、エラーが発生することを示します。言い換えると、外部キーに親の行を参照させるには、その前に親の行がなければならないということです。これは Zen のデフォルトの動作です。
なお、Zen ではこれ以外の更新規則を一切サポートしていません。したがって、この規則は明示的に示しても示さなくてもかまいません。また、削除規則を明示的に指定していないので、DELETE RESTRICT が使用されます。
CREATE TABLE StudentAddress (id UBIGINT REFERENCES Student (id) ON UPDATE RESTRICT, addr CHAR(128))
————————
この例は、テーブルの作成時にオルタネート コレーティング シーケンス(ACS)を使用する方法を示しています。使用する ACS ファイルは、Zen で提供されるサンプル ファイルです。
CREATE TABLE t5 (c1 CHAR(20) COLLATE 'file_path\upper.alt')
upper.alt は、ソートする際に大文字と小文字を同等に扱います。たとえば、データベースに abc、ABC、DEF、Def という値がこの順序で挿入されている場合、upper.alt を使ってソートすると、abc、ABC、DEF、Def のように返されます
abc と ABC という値、DEF と Def という値は、まったく同一と見なされ、挿入された順序で返されます。標準の ASCII ソートでは、大文字は小文字の前に配列されており、ソート結果は ABC、DEF、Def、abc となります。また、SELECT c1 FROM t5 WHERE c1 = 'Abc' ステートメントは、abc および ABC を返します。
————————
次の例は、テーブル t1 を作成し、リンク重複キー用に予約するポインターの数を 4 に設定します。CREATE INDEX ステートメントによって、テーブルにインデックス キーを作成します。
DROP table t1
CREATE TABLE t1 LINKDUP=4 (c1 int, c2 int, c3 int)
CREATE INDEX link_1 on t1(c1,c2)
CREATE INDEX link_2 on t1(c1,c3)
CREATE UNIQUE INDEX link_3 on t1(c3)
CREATE INDEX link_4 on t1(c1)
CREATE INDEX link_5 on t1(c2)
CREATE INDEX link_6 on t1(c2,c3)
CREATE INDEX ステートメントの結果は次のようになります。
• リンク重複キー:link_1、link_2、link_4、link_5
• 繰り返し重複キー:link_6(リンク重複キーに使用されるポインターの数が指定値の 4 に達したためです)
DROP INDEX link_2
CREATE INDEX link_7 on t1(c3,c1)
これら 2 つのステートメントを実行すると、次のようになります。
• リンク重複キー:link_1、link_4、link_5、link_7(DROP INDEX ステートメントによって、リンク重複キーに使用されるポインターの数が 3 に減ったので、link_7 を 4 番目のリンク重複キーにすることができます)
• 繰り返し重複キー:link_6
————————
次のステートメントでは、テーブルを作成してヌル値を許可しないことを指定します(つまり、ヌル インジケーター バイトは追加されません)。
CREATE TABLE NoNulls
(ID UBIGINT NOT NULL,
Name CHAR(20) NOT NULL CASE,
Amount DOUBLE NOT NULL)
————————
すべての列を NOT NULL として作成する必要がある場合は、まず SET TRUENULLCREATE ステートメントを使用して真のヌルの作成を無効にしてからテーブルを作成することができます。これにより、各列で NOT NULL 属性を指定することを避けられます(SET TRUENULLCREATE を参照してください)。ただし、結果として生じるレガシー テーブルでは、どの列にも NOT NULL 属性が適用されないことに注意してください。列に NOT NULL が明示的に指定されていても、NULL は許可されます。次のステートメントでは、前の例と同じテーブルを作成します。
SET TRUENULLCREATE=OFF
CREATE TABLE NoNulls2
(ID BIGINT,
Name CHAR(20) CASE,
Amount DOUBLE)
SET TRUENULLCREATE=ON
————————
CREATE TABLE では、列に DEFAULT 値を指定することができます。これは、その列に明示的に値を指定しないで行を挿入した場合に使用されます。次のステートメントは、列のデータ型に対応するデフォルト値を持つテーブルを作成します。IDENTITY 列は暗黙的にデフォルト値ゼロを持ち、次に最も大きい値が自動生成されることに留意してください。
CREATE TABLE Defaults
(ID IDENTITY,
Name CHAR(20) DEFAULT 'none',
Amount DOUBLE DEFAULT 0.00,
EntryDay DATE DEFAULT CURDATE(),
EntryTime TIME DEFAULT CURTIME())
次のステートメントは、デフォルトを使用して 2 行を挿入します。
INSERT INTO Defaults (ID) VALUES (0)
INSERT INTO Defaults (ID, Name, Amount) VALUES (0, 'Joquin', '100')
SELECT ステートメントはデフォルト値を持つ結果を返します。
SELECT * FROM Defaults
ID Name Amount EntryDay EntryTime
=== ======== ======== ========= ===========
1 none 0.0 curdate curtime
2 Joquin 100.0 curdate curtime
————————
次の例では、データ ファイル olddata.dat に旧形式のデータ型の列を含む Legacydata というテーブルがあると仮定します。新しいデータベースでは旧形式のデータ型を持つテーブルを作成することはできません。ただし、IN DICTIONARY 句を使用して新しいデータベースに旧形式データの DDF 定義を作成することができます。
CREATE TABLE "Legacydata" IN DICTIONARY USING 'olddata.dat' (
"col1" LSTRING(10) NOT NULL,
"col2" VARCHAR(9) NOT NULL,
"col3" LOGICAL NOT NULL,
"col4" LOGICAL2 NOT NULL,
"col5" NOTE(100) NOT NULL);
————————
この例では、USING 句または REPLACE のいずれも指定せずにテーブルを作成した場合の、Btrieve データ ファイルのデフォルトの作成方法を示しています。ファイルのデフォルト名は、拡張子 .mkd のテーブル名です。そのファイル名が既に存在する場合は、テーブル名の後に数字、.mkd 拡張子が続く、別の名前が生成されます。
次のようにテーブル xyz を作成します。これにより、データ ファイル xyz.mkd が生成されます。
CREATE TABLE xyz (c1 int, c2 char(5))
次に、データ ファイルが削除されないよう、IN DICTIONARY を使用してテーブルを削除します。
DROP TABLE xyz in dictionary
最後に、再びテーブル xyz を作成します。
CREATE TABLE xyz (c1 int, c2 char(5))
テーブル xyz とデータ ファイル xyz000.mkd が作成されます。
関連項目
CREATE (テンポラリ) TABLE
CREATE TABLE ステートメントを使用して、テンポラリ テーブルを作成することもできます。しかし、テンポラリ テーブルのための CREATE TABLE 構文は永続テーブルのためのものより限定的です。この理由により、またその他の特性があることから、テンポラリ テーブルについては別途説明します。ほかの特性を参照してください。
構文
CREATE TABLE <# | ##>テーブル名 ( テーブル要素 [ , テーブル要素 ]... )
テーブル名 ::= ユーザー定義名
テーブル要素 ::= 列定義 | テーブル制約定義
列名 ::= ユーザー定義名
桁数 ::= 整数
小数位 ::= 整数
デフォルト値の式 ::= デフォルト値の式 + デフォルト値の式
| デフォルト値の式 - デフォルト値の式
| デフォルト値の式 * デフォルト値の式
| デフォルト値の式 / デフォルト値の式
| デフォルト値の式 & デフォルト値の式
| デフォルト値の式 | デフォルト値の式
| デフォルト値の式 ^ デフォルト値の式
| ( デフォルト値の式 )
| -デフォルト値の式
| +デフォルト値の式
| ~デフォルト値の式
| ?
| リテラル
| スカラー関数
| { fn スカラー関数 }
| USER
| NULL
リテラル ::= '文字列' | N'文字列'
| 数字
| { d '日付リテラル' }
| { t '時刻リテラル' }
| { ts 'タイムスタンプ リテラル' }
列制約定義 ::= [ CONSTRAINT 制約名 ] 列制約
制約名 ::= ユーザー定義名
列制約 ::= NOT NULL
| NOT MODIFIABLE
| UNIQUE
| REFERENCES テーブル名 [ ( 列名 ) ] [ 参照アクション ]
テーブル制約定義 ::= [ CONSTRAINT 制約名 ] テーブル制約
REFERENCES テーブル名 [ ( 列名 [ , 列名 ]... ) ] [ 参照アクション ]
参照アクション ::= 参照更新アクション [ 参照削除アクション ]
| 参照削除アクション [ 参照更新アクション ]
照合順序名 ::= '文字列'
備考
テンポラリ テーブルは中間結果や作業領域として使用されます。永続テーブルとは異なり、テンポラリ テーブルのデータは SQL セッション中のある時点または SQL セッションの最後に破棄されます。データはデータベースに保存されません。
テンポラリ テーブルは、中間テーブルに対して処理を継続することにより、中間結果を絞り込むのに便利です。複雑なデータ操作は、単純な手順に分割することでより簡単になります。それぞれの手順では、前の手順の結果のテーブルに対して操作を行います。テンポラリ テーブルはベース テーブルです。つまり、データはそれ自体に含まれています。これをビューと対比してみると、ビューは他テーブルのデータの間接的な表現です。
Zen は以下の 2 つのタイプのテンポラリ テーブルをサポートします。
• ローカル
• グローバル
どちらのタイプもストアド プロシージャ内で使用できます。
テンポラリ テーブルの作成される場所と使用される場所を対比してテンポラリ テーブルの特性をまとめ、次の表に示します。特性は、テーブルが作成または使用される場所がストアド プロシージャの内部か外部かによって異なります。表の終わりにある脚注に注意事項が示されています。
メタデータのバージョン 1 とバージョン 2 では、テンポラリ テーブル名の許容サイズを除き、テーブルの特性は同じです。
テーブルの特性 | ローカル テンポラリ テーブル | グローバル テンポラリ テーブル | ||
|---|---|---|---|---|
SP 外部1 | SP 内部 | SP 外部 | SP 内部 | |
テーブル名の最初の文字は # である必要がある(下の以前のリリースとの互換性を参照してください。) | はい | はい | いいえ | いいえ |
テーブル名の最初の文字は ## である必要がある(下の以前のリリースとの互換性を参照してください。) | いいえ | いいえ | はい | はい |
テーブルのコンテキストはテーブルを作成するデータベースと同じ | はい | はい | はい | はい |
2 つ以上のセッションが同一名称のテーブルを作成可能2 | はい | はい | いいえ | いいえ |
メタデータ バージョン 1 の場合、テーブル名の最大長(長さには "#"、"##"、アンダースコア、および ID も含む)については、『Advanced Operations Guide』の識別子の制限を参照してください | はい3 | はい4 | はい3 | はい4 |
メタデータ バージョン 2 の場合、テーブル名の最大長(長さには "#"、"##"、アンダースコア、および ID も含む)については、『Advanced Operations Guide』の識別子の制限を参照してください | はい3 | はい4 | はい3 | はい4 |
別のデータベース内のテーブルには、そのテーブル名で修飾することによりアクセス可能 | いいえ | いいえ | はい | はい |
SELECT、INSERT、UPDATE、および DELETE ステートメントがテーブルで許可されている | はい | はい | はい | はい |
ALTER TABLE および DROP TABLE ステートメントがテーブルで許可されている | はい | はい | はい | はい |
テーブルにビューを作成できる | いいえ | いいえ | いいえ | いいえ |
テーブルにユーザー定義関数を作成できる | いいえ | いいえ | いいえ | いいえ |
テーブルにトリガーを作成できる | いいえ | いいえ | いいえ | いいえ |
テーブルで権限の許可または取り消しができる | いいえ | いいえ | いいえ | いいえ |
FOREIGN KEY 制約が CREATE TABLE ステートメントで使用できる5 | いいえ | いいえ | いいえ | いいえ |
SELECT INTO ステートメントでテーブルにデータを入れられる | はい | はい | はい | はい |
SELECT INTO ステートメントでテーブルを作成できる6 | はい | はい | はい | はい |
ある SQL セッションで作成されたテーブルが、ほかの SQL セッションからアクセスできる | いいえ | いいえ | はい | はい |
プロシージャで作成されたテーブルは、そのプロシージャの外でアクセス可能 | N/A9 | いいえ | N/A9 | はい |
最上位のプロシージャで作成されたテーブルは、ネストされたプロシージャでアクセス可能 | N/A9 | いいえ | N/A9 | いいえ |
再帰的ストアド プロシージャ内の CREATE TABLE ステートメントは再帰呼び出しでテーブル名エラーを返す | N/A9 | はい7 | N/A9 | はい9 |
テーブルは明示的削除時に削除される | はい | はい | はい | はい |
テーブルはそのテーブルが作成されたセッションの最後に削除される | はい | はい8 | はい | はい |
テーブルはそのテーブルが作成されたプロシージャの最後に削除される | N/A9 | はい | N/A9 | いいえ |
テーブルは別のセッションのトランザクションの最後に削除される | N/A9 | N/A9 | はい | はい |
1 SP はストアド プロシージャを表します。 2 データベース エンジンは、ストアド プロシージャの名前とセッション固有の ID をユーザー定義名に自動的に付加することによって、テーブル名が確実に一意になるようにします。この機能はユーザーに透過的です。 3 テーブル名の長さの合計には、"#" または "##" に加え、アンダースコア+セッション ID も含められます。セッション ID はオペレーティング システムによって 8、9、または 10 バイトになります。『Advanced Operations Guide』の識別子の制限を参照してください。 4 テーブル名の長さの合計には、"#" または "##" に加え、アンダースコア+ストアド プロシージャの名前+アンダースコア+セッション ID も含められます。セッション ID はオペレーティング システムによって 8、9、または 10 バイトになります。『Advanced Operations Guide』の識別子の制限を参照してください。 5 制約は警告を返しますがテーブルは作成されます。 6 テーブルは、1 つの SELECT INTO ステートメントによって作成されデータが入れられます。 7 テーブル名は、ストアド プロシージャが最初に実行されるときから既に存在しています。 8 プロシージャの実行が終了する前にセッションの終了が発生した場合。 9 N/A は「適用外」を意味します。 | ||||
以前のリリースとの互換性
PSQL v9 Service Pack 2 より前の Zen のリリースは、永続テーブルに # または ## で始まる名前を付けることを許可していました。PSQL v9 Service Pack 2 以降のリリースでは、永続テーブルに # または ## で始まる名前を付けることはできません。# または ## で始まるテーブルはテンポラリ テーブルであり、TEMPDB データベース内に作成されます。
お使いのバージョンより前のバージョンの Zen で作成された # または ## で始まる永続テーブルにアクセスしようとすると、「テーブルが見つからない」というエラーが返されます。
『Zen User's Guide』のステートメント区切り文字も参照してください。
TEMPDB データベース
Zen のインストールは TEMPDB という名前のシステム データベースを作成します。TEMPDB はすべてのテンポラリ テーブルを保持します。TEMPDB データベースは削除しないでください。削除してしまうと、テンポラリ テーブルが作成できなくなります。
TEMPDB は Zen 製品のインストール ディレクトリに作成されます。『Getting Started with Zen』のファイルはどこにインストールされますか?を参照してください。
インストール後に、TEMPDB の辞書ファイルとデータ ファイルの場所を変更することもできます。『Zen User's Guide』のデータベースのプロパティを参照してください。
注意! TEMPDB は、データベース エンジンが排他的に使用するシステム データベースです。TEMPDB を永続テーブル、ビュー、ストアド プロシージャなどの格納場所として使用しないでください。
ローカル テンポラリ テーブルのテーブル名
データベース エンジンは、複数のセッションで作成されたテンポラリ テーブルを区別するため、ローカル テンポラリ テーブルの名前に自動的に情報を付け加えます。付加情報の長さは、オペレーティング システムによって異なります。
ローカル テンポラリ テーブルの名前は少なくとも 10 バイトになります。ただしこれは、ローカル テンポラリ テーブルを作成するストアド プロシージャの数が 1296 を超えなければという条件付きです。10 バイトには # 文字も含まれます。1296 の制限は同一セッション内のストアド プロシージャに適用されます。
名前の最大長は 20 バイトで、# 文字、テーブル名、および追加情報を含みます。
トランザクション
グローバル テンポラリ テーブルは、明示的に削除されるか、またはテーブルが作成されたセッションの終了時に自動的に削除されます。トランザクション内で、テーブルを作成したのではないセッションがそのテーブルを使用している場合、トランザクション完了時に削除されます。
SELECT INTO
単一の SELECT INTO ステートメントを使用して、テンポラリ テーブルを作成しデータを入れることができます。たとえば、SELECT * INTO #mytmptbl FROM Billing は、#mytmptbl という名前のローカル テンポラリ テーブルを作成します(#mytmptbl は存在していないものとします)。テンポラリ テーブルには Demodata サンプル データベースの Billing テーブルと同じデータが含まれます。
SELECT INTO ステートメントが同じテンポラリ テーブル名を使用して 2 度目に実行されると、テンポラリ テーブルが既に存在するのでエラーが返されます。
SELECT INTO ステートメントは 2 つ以上のテーブルからテンポラリ テーブルを作成することができます。ただし、テンポラリ テーブルを作成する元の各テーブルの列名は重複していない必要があります。重複しているとエラーが返されます。
このエラーは、列名をテーブル名で修飾し、各列にエイリアスを指定すれば回避することができます。たとえば、テーブル t1 と t2 には両方とも col1 と col2 の 2 つの列があるとします。次のステートメント SELECT t1.co1, t1.col2, t2.col1, t2.col2 INTO #mytmptbl FROM t1, t2 はエラーを返します。代わりに、次のようなステートメント SELECT t1.co1 c1, t1.col2 c2, t2.col1 c3, t2.col2 c4 INTO #mytmptbl FROM t1, t2 を使用します。
SELECT INTO の制限
• ストアド プロシージャ内部で作成されたローカル テンポラリ テーブルは、そのストアド プロシージャのスコープ内にあります。ストアド プロシージャの実行後、ローカル テンポラリ テーブルは破棄されます。
• UNION および UNION ALL キーワードは、SELECT INTO ステートメントと共に使用することはできません。
• SELECT INTO ステートメントの結果を取得できるのは、1 つのテンポラリ テーブルだけです。単独の SELECT INTO ステートメントによって、データを選択(SELECT)し、それを複数のテンポラリ テーブルに入れることはできません。
ストアド プロシージャのキャッシング
ローカルまたはグローバルのテンポラリ テーブルを参照するストアド プロシージャは、キャッシュ設定に関わらずキャッシュされません。SET CACHED_PROCEDURES および SET PROCEDURES_CACHE を参照してください。
テンポラリ テーブルの例
次の例では、#b_temp という名前のローカル テンポラリ テーブルを作成し、Demodata サンプル データベースの Billing テーブルのデータを入れます。
SELECT * INTO "#b_temp" FROM Billing
————————
次の例では、ID、Dept_Name、Building_Name、Room_Number の列から成り、列 ID に基づく主キーを持つ ##tenurefac という名前のグローバル テンポラリ テーブルを作成します。
CREATE TABLE ##tenurefac
(ID UBIGINT,
Dept_Name CHAR(20) CASE,
Building_Name CHAR(25) CASE,
Room_Number UINTEGER,
PRIMARY KEY(ID))
————————
次の例では、テンポラリ テーブル ##tenurefac を変更し、列 Research_Grant_Amt を追加します。
ALTER TABLE ##tenurefac ADD Research_Grant_Amt DOUBLE
————————
次の例では、テンポラリ テーブル ##tenurefac を削除します。
DROP TABLE ##tenurefac
————————
次の例では、ストアド プロシージャ内で 2 つのテンポラリ テーブルを作成し、そのテーブルにデータを入れ、変数に値を割り当てます。その値はテンポラリ テーブルから選択されます。
メモ: SELECT INTO は、変数に値を割り当てるために使用するのであれば、ストアド プロシージャ内で使用できます。
CREATE PROCEDURE "p11"()
AS BEGIN
DECLARE :val1_int INTEGER;
DECLARE :val2_char VARCHAR(20);
CREATE TABLE #t11 (col1 INT, col2 VARCHAR(20));
CREATE TABLE #t12 (col1 INT, col2 VARCHAR(20));
INSERT INTO #t11 VALUES (1,'t1 col2 text');
INSERT INTO #t12 VALUES (2,'t2 col2 text');
SELECT col1 INTO :val1_int FROM #t11 WHERE col1 = 1;
SELECT col2 INTO :val2_char FROM #t12 WHERE col1 = 2;
PRINT :val1_int;
PRINT :val2_char;
COMMIT;
END;
CALL P1()
————————
次の例では、グローバル テンポラリ テーブル ##enroll_student_global_temp_tbl を作成し、次にストアド プロシージャ Enrollstudent を作成します。呼び出されると、プロシージャは指定された Student ID、Class ID、および GPA(Grade Point Average)を基に、##enroll_student_global_temp_tbl にレコードを挿入します。SELECT でテンポラリ テーブル内のすべてのレコードを選択し、その結果を表示します。グローバル テンポラリ テーブルの名前の長さは、メタデータ バージョン 2 でのみ許容されます。
CREATE TABLE ##enroll_student_global_temp_tbl (student_id INTEGER, class_id INTEGER, GPA REAL);
CREATE PROCEDURE Enrollstudent(in :Stud_id integer, in :Class_Id integer, IN :GPA REAL);
BEGIN
INSERT INTO ##enroll_student_global_temp_tbl VALUES(:Stud_id, :Class_id, :GPA);
END;
CALL Enrollstudent(1023456781, 146, 3.2)
SELECT * FROM ##enroll_student_global_temp_tbl
————————
次の例では、ストアド プロシージャ内で 2 つのテンポラリ テーブルを作成し、そのテーブルにデータを入れ、変数に値を割り当てます。その値はテンポラリ テーブルから選択されます。
CREATE PROCEDURE "p11"()
AS BEGIN
DECLARE :val1_int INTEGER;
DECLARE :val2_char VARCHAR(20);
CREATE TABLE #t11 (col1 INT, col2 VARCHAR(20));
CREATE TABLE #t12 (col1 INT, col2 VARCHAR(20));
INSERT INTO #t11 VALUES (1,'t1 col2 text');
INSERT INTO #t12 VALUES (2,'t2 col2 text');
SELECT col1 INTO :val1_int FROM #t11 WHERE col1 = 1;
SELECT col2 INTO :val2_char FROM #t12 WHERE col1 = 2;
PRINT :val1_int;
PRINT :val2_char;
COMMIT;
END;
CALL P11()
関連項目
CREATE TRIGGER
CREATE TRIGGER ステートメントにより、データベース内に新しいトリガーを作成します。トリガーとは、INSERT、UPDATE、または DELETE によってテーブル データが変更されるときに自動的に実行されるストアド プロシージャの一種です。
通常のストアド プロシージャとは違って、トリガーは直接実行できず、パラメーターを持つこともできません。また、トリガーは結果セットを返さず、トリガーをビューに定義することもできません。
構文
CREATE TRIGGER トリガー名 before/after 挿入/更新/削除 ON テーブル名
[ ORDER 番号 ]
[ REFERENCING 参照エイリアス ] FOR EACH ROW
[ WHEN プロシージャ検索条件 ] プロシージャ ステートメント
トリガー名 ::= ユーザー定義名
before/after ::= BEFORE | AFTER
挿入/更新/削除 ::= INSERT | UPDATE | DELETE
相関名 ::= ユーザー定義名
備考
メモ: トリガー内では、変数名はコロン(:)で始まる必要があります。
OLD(OLD 相関名)と NEW(NEW 相関名)はトリガー内部で使用でき、通常のストアド プロシージャでは使用できません。
OLD(OLD 相関名)と NEW(NEW 相関名)はトリガー内部で使用でき、通常のストアド プロシージャでは使用できません。
DELETE または UPDATE トリガーでは、文字 "OLD" または OLD 相関名を列名の前に付加して、更新または削除操作の前にデータ行内の列を参照する必要があります。
INSERT または UPDATE トリガーでは、文字 "NEW" または NEW 相関名を列名の前に付加して、挿入または更新しようとする行内の列を参照する必要があります。
トリガー名は辞書内で固有の名前でなければなりません。
例
次の例では、Tuition テーブルに挿入された新規の値を TuitionIDTable に記録するトリガーが作成されます。
CREATE TABLE Tuitionidtable (PRIMARY KEY(id), id UBIGINT);
CREATE TRIGGER InsTrig
BEFORE INSERT ON Tuition
REFERENCING NEW AS Indata
FOR EACH ROW
INSERT INTO Tuitionidtable VALUES(Indata.ID);
Tuition の INSERT によりトリガーが呼び出されます。
————————
次の例では、トリガーを使って A と B の 2 つのテーブルの同期をとる方法を示します。両方のテーブルは同じ構造体を持ちます。
CREATE TABLE A (col1 INTEGER, col2 CHAR(10));
CREATE TABLE B (col1 INTEGER, col2 CHAR(10));
CREATE TRIGGER MyInsert
AFTER INSERT ON A FOR EACH ROW
INSERT INTO B VALUES (NEW.col1, NEW.col2);
CREATE TRIGGER MyDelete
AFTER DELETE ON A FOR EACH ROW
DELETE FROM B WHERE B.col1 = OLD.col1 AND B.col2 = OLD.col2;
CREATE TRIGGER MyUpdate
AFTER UPDATE ON A FOR EACH ROW
UPDATE B SET col1 = NEW.col1, col2 = NEW.col2 WHERE B.col1 = OLD.col1 AND B.col2 = OLD.col2;
この例の OLD と NEW は、テーブル A が位置付けでない SQL ステートメントで変更された場合のみテーブルの同期を保つので注意してください。SQLSetPos API または位置付けの UPDATE か DELETE を使用した場合は、テーブル A が重複するレコードを含まない場合のみテーブルの同期が保たれます。一方のレコードは変更するが、もう一方の重複するレコードは変更しないままにしておく SQL ステートメントは作成できません。
関連項目
CREATE USER
CREATE USER ステートメントにより、データベースに新しいユーザー アカウントが作成します。
この関数は、パスワード付き、パスワードなし、また、グループのメンバーとしてのユーザー アカウントをデータベースに作成するのに使用できます。
構文
CREATE USER ユーザー名 [ WITH PASSWORD ユーザー パスワード ][ IN GROUP 参照エイリアス ]
備考
このステートメントは、Zen Control Center(ZenCC)を使用して作成したユーザーと同じ権限を持つユーザーを作成します。たとえば、作成されたユーザーは、そのユーザーが Master としてログインしていない場合でも、デフォルトでデータベースを作成することを制限されません。
Master ユーザーのみがこのステートメントを実行できます。
このステートメントを実行するには、セキュリティ設定が有効になっている必要があります。
ユーザー名およびユーザー パスワードは Zen データベースのみを対象としたもので、オペレーティング システム レベルで設定されているユーザー名とパスワードには無関係です。Zen ユーザー名、グループ、およびパスワードは Zen Control Center(ZenCC)を使用して設定することもできます。
ユーザー名は辞書内で重複しない名前でなければなりません。
ユーザー名とパスワードに空白またはその他の非英数文字が含まれる場合は、ユーザー名とパスワードを二重引用符で囲む必要があります。
ユーザーをグループのメンバーとして作成する場合は、ユーザーを作成する前にグループを設定する必要があります。
ユーザーとグループの詳細については、『Advanced Operations Guide』の Master ユーザー、ユーザーとグループ、および『Zen User's Guide』の権限の割り当て作業を参照してください。
例
以下の例では、ログイン権限を持たず、どのグループのメンバーでもない新規ユーザー アカウントを作成する方法を示します。
CREATE USER pgranger
新しいユーザーの名前は pgranger です。ユーザー パスワードは NULL で、このユーザー アカウントはどのグループのメンバーでもありません。
CREATE USER "polly granger"
新しいユーザーの名前は polly granger で、非英数文字を含んでいます。ユーザー パスワードは NULL で、このユーザー アカウントはどのグループのメンバーでもありません。
————————
以下の例では、ログイン権限を持ち、どのグループのメンバーでもない新規ユーザー アカウントを作成する方法を示します。
CREATE USER pgranger WITH PASSWORD Prvsve1
新しいユーザーの名前は pgranger です。ユーザー パスワードは Prsve1(大文字と小文字を区別)です。
CREATE USER pgranger WITH PASSWORD "Nonalfa$"
新しいユーザーの名前は pgranger です。ユーザー パスワードは Nonalfa$(大文字と小文字を区別)で、非英数文字を含んでいます。
————————
以下の例では、グループのメンバーで、ログイン権限を持たない新規ユーザーを作成する方法を示します。
CREATE USER pgranger IN GROUP developers
新しいユーザーの名前は pgranger です。新しいユーザー アカウントは、グループ developers に割り当てられます。
————————
以下の例では、グループのメンバーで、ログイン権限を持つ新規ユーザーを作成する方法を示します。
CREATE USER pgranger WITH PASSWORD Prvsve1 IN GROUP developers
新しいユーザーの名前は pgranger です。新しいユーザー アカウントは、グループ developers に割り当てられ、大文字小文字を区別するパスワード Prvsve1 を持ちます。この構文の順序(CREATE USER..WITH PASSWORD...IN GROUP)は非常に重要です。
関連項目
CREATE VIEW
CREATE VIEW ステートメントを使用して、ストアド ビューまたは仮想テーブルを作成します。
構文
CREATE VIEW ビュー名 [ ( 列名 [ , 列名 ]... ) ]
[ ORDER BY order-by式 [ , order-by式 ]... ]
ビュー名 ::= ユーザー定義名
列名 ::= ユーザー定義名
備考
ビューは一種のデータベース オブジェクトで、クエリを格納し、テーブルのように振る舞います。ビューが返すデータは、SELECT ステートメントにより参照される、1 つ以上のテーブルに格納されます。ビュー内の行と列は、参照されるたびにリフレッシュされます。
ビュー名の最大長については、『Advanced Operations Guide』の識別子の制限を参照してください。ビュー内の列の最大数は 256 です。ビュー定義には 64 KB の制限があります。
Zen はグループ化ビューをサポートしています。グループ化ビューとは、SELECT ステートメントで次のいずれかを使用しているビューと定義されます。
• DISTINCT
• GROUP BY
• ORDER BY
• スカラー関数
• UNION
ビュー定義にプロシージャを含めることはできません。
ORDER BY
ビューにおける ORDER BY は、SELECT ステートメントにおける場合と同じように動作します。以下の点に特に留意してください。
• ORDER BY 句ではエイリアスを使用できます。
• ORDER BY 句ではスカラー サブクエリを使用できます。
• TOP や LIMIT は、ORDER BY を使用しているビューで使用することをお勧めします。
• エンジンが、ORDER BY によって順序付けされた結果を返すためにテンポラリ テーブルを使用し、クエリが動的カーソルを使用する場合、そのカーソルは静的に変換されます。たとえば、インデックス付けされていない列に対して ORDER BY が使用される場合には、常にテンポラリ テーブルが必要となります。前方のみのカーソルと静的カーソルは影響を受けません。
信頼されるビューと信頼されないビュー
信頼されるビューには WITH EXECUTE AS 'MASTER' を含めます。信頼されるオブジェクトと信頼されないオブジェクトを参照してください。
信頼されるビューと信頼されないビューの例
次のステートメントによって、大学に在籍している全員の電話番号リストを作成する、vw_Person という名前の信頼されないビューが作成されます。このビューには姓、名および電話番号が表示され、列ごとにヘッダーが付きます。Person テーブルは Demodata サンプル データベースの一部です。
CREATE VIEW vw_Person (lastn,firstn,phone) AS SELECT Last_Name, First_Name,Phone FROM Person
このビューに対する以降のクエリでは、SELECT ステートメントで列見出しを使用できます。
SELECT lastn, firstn FROM vw_Person
ビューを実行するユーザーは、Person テーブルの SELECT 権限を持っている必要があります。
————————
次の例では類似したビューが作成されますが、これは信頼されるビューです。
CREATE VIEW vw_trusted_Person (lastn,firstn,phone) WITH EXECUTE AS 'MASTER' AS SELECT Last_Name, First_Name,Phone FROM Person
user1 には、vw_Person の SELECT 権限が付与されているものとします。user1 は次のように SELECT ステートメントで列見出しを使用できます。
SELECT lastn, firstn FROM vw_trusted_Person
user1 は Person テーブルの SELECT 権限を持っている必要はありません。権限は信頼されるビューに付与されています。
————————
次のステートメントによって、大学に在籍している全員の電話番号リストを作成する、vw_Person という名前のビューが作成されます。このビューには姓、名および電話番号が表示され、列ごとにヘッダーが付きます。Person テーブルは Demodata サンプル データベースの一部です。
CREATE VIEW vw_Person (lastn, firstn, telphone) AS SELECT Last_Name, First_Name, Phone FROM Person
このビューに対する以降のクエリでは、次の例に示すように、SELECT ステートメントで列見出しを使用できます。
SELECT lastn, firstn FROM vw_Person
————————
前の例に ORDER BY 句を含めるように変更できます。
CREATE VIEW vw_Person_ordby (lastn, firstn, telphone) AS SELECT Last_Name, First_Name, Phone FROM Person ORDER BY phone
ビューは次のような結果を返します(簡潔にするため、すべてのレコードは表示されていません)。
Last_Name First_Name Phone
========= ========== ==========
Vqyles Rex 2105551871
Qulizada Ahmad 2105552233
Ragadio Ernest 2105554654
Luckey Anthony 2105557628
————————
次の例では、生徒の成績評価点平均(GPA)を降順で返し、さらに、その GPA ごとに生徒を姓の昇順で列挙するビューを作成します。
CREATE VIEW vw_gpa AS SELECT Last_Name,Left(First_Name,1) AS First_Initial,Cumulative_GPA AS GPA FROM Person LEFT OUTER JOIN Student ON Person.ID=Student.ID ORDER BY Cumulative_GPA DESC, Last_Name
ビューは次のような結果を返します(簡潔にするため、すべてのレコードは表示されていません)。
Last_Name First_Initial GPA
========================= =============== ======
Abuali I 4.000
Adachi K 4.000
Badia S 4.000
Rowan A 4.000
Ujazdowski T 4.000
Wotanowski H 4.000
Gnat M 3.998
Titus A 3.998
Mugaas M 3.995
————————
この例では、Person テーブルの先頭 10 レコードを ID 順で返すビューが作成されます。
CREATE VIEW vw_top10 AS SELECT TOP 10 * FROM person ORDER BY id;
ビューは次のような結果を返します(簡潔にするため、すべての列は表示されていません)。
ID First_Name Last_Name
========= ========== ==========
100062607 Janis Nipart
100285859 Lisa Tumbleson
100371731 Robert Mazza
100592056 Andrew Sugar
100647633 Robert Reagen
100822381 Roosevelt Bora
101042707 Avram Japadjief
10 行が影響を受けました。
————————
次の例では、ORDER BY を UNION と一緒に使用できることを示すためのビューを作成します。
CREATE VIEW vw_union_ordby_desc AS SELECT first_name FROM person UNION SELECT last_name FROM PERSON ORDER BY first_name DESC
ビューは次のような結果を返します(簡潔にするため、すべてのレコードは表示されていません)。
First_Name
===========
Zyrowski
Zynda
Zydanowicz
Yzaguirre
Yyounce
Xystros
Xyois
Xu
Wyont
Wynalda
Wykes
関連項目
DECLARE
備考
DECLARE ステートメントを使用して、SQL 変数を定義します。
このステートメントは、ストアド プロシージャ、ユーザー定義関数、およびトリガー内でのみ使用できます。
変数名はコロン(:)またはアットマーク(@)で始まる必要があります。これは、変数やパラメーターを定義するときと使用するときの両方に当てはまります。SET を使って変数に値を設定するには、まず変数が宣言されていなければなりません。
各変数について、別々の DECLARE ステートメントを使用します(単一のステートメントで複数の変数は宣言できません)。CHAR、DECIMAL、NUMERIC および VARCHAR など、サイズや有効桁数、小数部桁数が必要なデータ型には、それらの値を指定します。
例
次の例は、変数の宣言方法を、サイズ、有効桁数、または小数部桁数が必要な変数の宣言も含めて示しています。
DECLARE :SaleItem CHAR(15);
DECLARE :CruiseLine CHAR(25) DEFAULT 'Open Seas Tours'
DECLARE :UnitWeight DECIMAL(10,3);
DECLARE :Titration NUMERIC(12,3);
DECLARE :ReasonForReturn VARCHAR(200);
DECLARE :Counter INTEGER = 0;
DECLARE :CurrentCapacity INTEGER = 9;
DECLARE :Cust_ID UNIQUEIDENTIFIER = NEWID()
DECLARE :ISO_ID UNIQUEIDENTIFIER = '1129619D-772C-AAAB-B221-00FF00FF0099'
関連項目
DECLARE CURSOR
DECLARE CURSOR ステートメントにより、SQL カーソルを定義します。
構文
DECLARE カーソル名 CURSOR FOR 選択ステートメント [ FOR UPDATE | FOR READ ONLY ]
カーソル名 ::= ユーザー定義名
備考
DECLARE では、カーソルと変数はストアド プロシージャとトリガー内部でのみ許可されるため、このステートメントはストアド プロシージャまたはトリガー内部でのみ使用できます。
カーソルのデフォルト動作は読み取り専用です。したがって、更新(書き込みまたは削除)を明示的に示すには FOR UPDATE を使用する必要があります。
例
次の例では、Tuition テーブルの Degree、Residency、および Cost_Per_Credit 列から値を選択し、それらを ID 番号順に並べるカーソルが作成されます。
DECLARE BTUCursor CURSOR
FOR SELECT Degree, Residency, Cost_Per_Credit
FROM Tuition
ORDER BY ID;
————————
次の例では、削除を実行するために FOR UPDATE が使用されています。
CREATE PROCEDURE MyProc(IN :CourseName CHAR(7)) AS
BEGIN
DECLARE c1 CURSOR FOR SELECT name FROM course WHERE name = :CourseName FOR UPDATE;
OPEN c1;
FETCH NEXT FROM c1 INTO :CourseName;
DELETE WHERE CURRENT OF c1;
CLOSE c1;
END;
CALL MyProc('HIS 305')
DECLARE cursor1 CURSOR
FOR SELECT Degree, Residency, Cost_Per_Credit
FROM Tuition ORDER BY ID
FOR UPDATE;
関連項目
DEFAULT
テーブルには、ヌル値を許可しない列がある場合があります。エラーを回避するために、新しいレコードのそれらの列が必ず有効な値を持つよう、列のデフォルト値を定義しておくことができます。これを行うには、列定義の CREATE または ALTER で DEFAULT キーワードを使用して、INSERT および UPDATE ステートメントで使用される列値を設定します。この値は、次の一方または両方に当てはまる場合に使用されます。
• 明確な列値が指定されていない。
• 列ではバイナリ ゼロを使用できず、ヌル以外の有効な値を必要とする。
デフォルトの列値を定義すると、行を挿入または更新するときに VALUES 句で DEFAULT キーワードを使用すれば、その値を指定することができます。
要約すると、DEFAULT キーワードは次の場合に使用することができます。
• CREATE TABLE の列定義
• ALTER TABLE の列定義
• INSERT の VALUES 句
• UPDATE の VALUES 句
デフォルト値はリテラルまたは式です。CREATE TABLE または ALTER TABLE ステートメントでは、次の条件を満たしている必要があります。
• 列のデータ型と一致している
• 列に設定されている範囲や長さなどの制約に従っている
INSERT および UPDATE ステートメントでは、DEFAULT 式が定義されている列については、Zen が式を評価し、その結果を挿入または更新時に書き込みます。INSERT の場合、既存レコードの列は変更されないことに留意してください。
構文
DEFAULT キーワードの使用については、次のステートメントの構文を参照してください。
• INSERT
• UPDATE
備考
以下のトピックでは、DEFAULT としてのリテラル値または式について説明します。
IDENTITY データ型の制限
CREATE TABLE ステートメントまたは ALTER TABLE ステートメントでは、IDENTITY、SMALLIDENTITY、BIGIDENTITY データ型にデフォルト値ゼロ(DEFAULT 0 または DEFAULT '0')を設定することができます。これらのデータ型では、それ以外のデフォルト値は許可されません。
列のデフォルト値としてのスカラー関数および単純な式
Zen では、リテラル値やヌル値のほかに、列と同じデータ型の値を返しさえすれば、スカラー関数や単純な式を使用して DEFAULT 値を定義することができます。たとえば、CHAR や VARCHAR の文字列型の列に USER() を使用することができます。新しい INSERT ステートメントおよび UPDATE ステートメントでそれが使用されたときに、戻り値が評価されます。
次の例は、DEFAULT として単純な式やさまざまなスカラー関数を使用する方法を示します。
CREATE TABLE DEFAULTSAMPLE (
a INT DEFAULT 100,
b DOUBLE DEFAULT PI(),
c DATETIME DEFAULT NOW(),
d CHAR(20) DEFAULT USER(),
e VARCHAR(10) DEFAULT UPPER(DAYNAME(CURDATE())),
f VARCHAR(40) DEFAULT '{'+CONVERT(NEWID(),SQL_VARCHAR)+'}',
g INTEGER DEFAULT DAYOFYEAR(NOW())
);
INSERT INTO DEFAULTSAMPLE DEFAULT VALUES;
SELECT * FROM TX;
a b c d
=========== ======================= ============================== ===================
100 3.141592653589793 2021-11-12 17:25:59.288 Master
e f g
========= ======================================= ==========
FRIDAY {EF66F711-36D2-40FA-B928-BAFCC486DA6B} 316
ALTER TABLE での DEFAULT の使用
ALTER TABLE を使用して列定義を変更し、DEFAULT 属性を追加する場合、ALTER TABLE は既存の列定義に追加するのではなく、それを置き換えるため、既に定義されている列属性を含める必要があります。また、次の例に示すように、列を変更して DEFAULT 値を変えても、既存の値には影響しません。
CREATE TABLE Tab10 (a INT, b CHAR(20) CASE); --列 b は大文字小文字を無視します
ALTER TABLE Tab10 ALTER COLUMN b CHAR(20) DEFAULT 'xyz'; --列 b はデフォルト値を持ちますが、大文字小文字を無視しなくなりました
INSERT INTO Tab10 DEFAULT VALUES;
SELECT * FROM Tab10;
a b
=========== ====================
(Null) xyz
1 行が影響を受けました。
SELECT * FROM Tab10 WHERE b = 'XYZ'; --大文字小文字が一致しないので、行は返されません
a b
=========== ====================
0 行が影響を受けました。
ALTER TABLE Tab10 ALTER COLUMN b CHAR(20) CASE DEFAULT 'xyz'; --列 b は大文字小文字を無視し、「かつ」デフォルト値を持つようになりました
SELECT * FROM Tab10 WHERE b = 'XYZ'; --大文字小文字が一致する必要はありません
a b
=========== ====================
(Null) xyz
1 行が影響を受けました。
例
次のステートメントはテーブル Tab5 を作成します。列 col5 のデフォルト値は 200 とします。
CREATE TABLE Tab5
(col5 INT DEFAULT 200)
————————
次のステートメントはテーブル Tab1 を作成し、列 col1 は NOW() から返された結果の DATE 部分とします。
CREATE TABLE Tab1
(col1 DATE DEFAULT NOW())
————————
次のステートメントはテーブル Tab8 を作成し、列 col8 は、INSERT または UPDATE ステートメントの実行時間とします。
CREATE TABLE Tab8
(col8 TIMESTAMP DEFAULT CURRENT_TIMESTAMP())
————————
次のステートメントはテーブル Tab6 を作成し、列 col6 は、INSERT または UPDATE ステートメント実行後のユーザー名とします。DEFAULT USER を実際に利用できるのは、セキュリティが有効になっている場合のみです。有効になっていない場合、USER は常にヌルです。キーワード USER は USER() 関数と同じ結果をもたらします。
CREATE TABLE Tab6
(col6 VARCHAR(20) DEFAULT USER)
————————
次のステートメントは無効な例を示しています。TIME は DATE 列で許可されているデータ型ではないため、解析時エラーになります。
CREATE TABLE Tab
(col DATE DEFAULT CURTIME())
————————
次のステートメントは無効な例を示しています。'3.1' は数値に変換できますが、それは有効な整数ではないため、解析時エラーになります。
CREATE TABLE Tab
(col SMALLINT DEFAULT '3.1')
————————
次のステートメントは無効な例を示しています。CREATE TABLE ステートメントは成功しますが、-60000 は SMALLINT でサポートされる値の範囲外であるため、INSERT ステートメントは失敗します。
CREATE TABLE Tab
(col SMALLINT DEFAULT 3 * -20000)
INSERT INTO Tab values(DEFAULT)
————————
次のステートメントは、IDENTITY および SMALLIDENTITY データ型にデフォルト値ゼロを設定する正しい例を示しています。
CREATE TABLE t1 ( c1 IDENTITY DEFAULT '0' )
ALTER TABLE t1 ALTER c1 SMALLIDENTITY DEFAULT 0
————————
次のステートメントは、IDENTITY および SMALLIDENTITY データ型にデフォルト値を設定する無効な例を示しています。
CREATE TABLE t1 ( c1 IDENTITY DEFAULT 3 )
ALTER TABLE t1 ALTER c1 SMALLIDENTITY DEFAULT 1
関連項目
DELETE(位置付け)
DELETE(位置付け)ステートメントを使用して、SQL カーソルに関連付けられたビューの現在行を削除します。
構文
DELETE WHERE CURRENT OF カーソル名
カーソル名 ::= ユーザー定義名
備考
このステートメントは、ストアド プロシージャ、トリガー、およびセッション レベルでのみ使用できます。
メモ: セッション レベルでは位置付け DELETE ステートメントは使用できますが、DECLARE CURSOR ステートメントは使用できません。アクティブな結果セットのカーソル名を取得する方法は、アプリケーションが使用している Zen のアクセス方法によって決まります。アクセス方法については、Zen のドキュメントを参照してください。
例
次の一連のステートメントは、位置付け DELETE ステートメントの設定を示します。位置付け DELETE ステートメントに必要なステートメントは、DECLARE CURSOR、OPEN CURSOR、および FETCH FROM カーソル名です。
現代ヨーロッパ史の授業が時間割から削除されたので、この例ではサンプル データベースの Course テーブルから Modern European History(HIS 305)の行が削除されます。
CREATE PROCEDURE DropClass();
DECLARE :CourseName CHAR(7);
DECLARE c1 CURSOR
FOR SELECT name FROM COURSE WHERE name = :CourseName;
BEGIN
SET :CourseName = 'HIS 305';
OPEN c1;
FETCH NEXT FROM c1 INTO :CourseName;
DELETE WHERE CURRENT OF c1;
END;
関連項目
DELETE
このステートメントにより、データベース テーブルまたはビューから指定された行を削除します。
構文
DELETE [ FROM ] < テーブル名 | ビュー名 > [ エイリアス名 ]
[ FROM テーブル参照 [ , テーブル参照 ]...
[ WHERE 検索条件 ]
[ FROM テーブル参照 [ , テーブル参照 ]...
[ WHERE 検索条件 ]
テーブル名 ::= ユーザー定義名
ビュー名 ::= ユーザー定義名
テーブル参照 ::= { OJ 外部結合定義 }
| 結合定義
| ( 結合定義 )
外部結合定義 ::= テーブル参照 外部結合タイプ JOIN テーブル参照 ON 検索条件
外部結合タイプ ::= LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
検索条件 ::= 検索条件 AND 検索条件
| 検索条件 OR 検索条件
| NOT 検索条件
| ( 検索条件 )
| 述部
データベース名 ::= ユーザー定義名
ビュー名 ::= ユーザー定義名
結合定義 ::= テーブル参照 [ 結合タイプ ] JOIN テーブル参照 ON 検索条件
| テーブル参照 CROSS JOIN テーブル参照
| 外部結合定義
結合タイプ ::= INNER | LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
備考
DELETE ステートメントは、INSERT および UPDATE と同様にアトミックな方法で動作します。つまり、複数の行の削除に失敗した場合、同じステートメントによって実行された前の行の削除がすべてロール バックされます。
FROM 句
オプションの第 2 FROM 句と、行が削除されるテーブル(「削除テーブル」と呼びます)への参照に関して混乱が生じる可能性があります。第 2 FROM 句に削除テーブルが現れる場合、その出現のうちの 1 つは、行が削除されるテーブルと同じインスタンスになります。
たとえば、ステートメント DELETE t1 FROM t1, t2 WHERE t1.c1 = t2.c1 の場合、DELETE の直後の t1 と FROM の後の t1 は、テーブル t1 の同じインスタンスです。したがって、このステートメントは DELETE t1 FROM t2 WHERE t1.c1 = t2.c1 と同じことになります。
第 2 FROM 句に削除テーブルが複数回現れる場合、その出現のうちの 1 つは削除テーブルと同じインスタンスであると識別される必要があります。第 2 FROM 句の参照のうち、削除テーブルと同じインスタンスであると見なされるのは、エイリアスが指定されていない参照です。
したがって、ステートメント DELETE t1 FROM t1 a, t1 b WHERE a.c1 = b.c1 の場合、第 2 FROM 句の t1 のインスタンスはどちらもエイリアスを持っているため、これは正しくありません。次であれば有効です。DELETE t1 FROM t1, t1 b WHERE t1.c1 = b.c1
第 2 FROM 句には次の条件が適用されます。
• DELETE ステートメントにオプションの第 2 FROM 句を含める場合、FROM 句の前にあるテーブル参照にエイリアスを指定することはできません。たとえば、DELETE t1 a FROM t2 WHERE a.c1 = t2.c1 とすると、次のエラーが返されます。
SQL_ERROR (-1)
SQLSTATE "37000"
"オプションの FROM を伴う UPDATE/DELETE ステートメントでは、テーブル エイリアスは使用できません。"
ステートメントの有効なバージョンは、DELETE t1 FROM t2 WHERE t1.c1 = t2.c1 または DELETE t1 FROM t1 a, t2 WHERE a.c1 = t2.c1 です。
• 第 2 FROM 句に削除テーブルへの参照を 2 つ以上含める場合、それらの参照のうちの 1 つにだけエイリアスを指定できます。たとえば、DELETE t1 FROM t1 a, t1 b WHERE a.c1 = b.c1 とすると、次のエラーが返されます。
SQL_ERROR (-1)
SQLSTATE "37000"
"テーブル t1 があいまいです。"
誤りのあるステートメントでは、エイリアスを "a" とするテーブル t1 が削除テーブルと同じインスタンスであると仮定しています。正しいステートメントは、DELETE t1 FROM t1, t1 b WHERE t1.c1 = b.c1 です。
• DELETE ステートメントにおける第 2 FROM 句はセッション レベルでのみサポートされます。DELETE ステートメントがストアド プロシージャ内で発生する場合は、第 2 FROM 句はサポートされません。
例
次のステートメントによって、サンプル データベースの person テーブルから名前 Ellen の行が削除されます。
DELETE FROM person WHERE First_Name = 'Ellen'
次のステートメントによって、サンプル データベースの course テーブルから Modern European History(HIS 305)の行が削除されます。
DELETE FROM Course WHERE Name = 'HIS 305'
DISTINCT
DISTINCT キーワードを SELECT ステートメントに記述すると、結果から重複する値が削除されます。DISTINCT を使用することで、選択条件を満たす一意の行をすべて取得できます。
以下の規則が適用されます。
• Zen は、サブクエリでの DISTINCT の使用をサポートします。
• 選択リストに集計が含まれる場合、DISTINCT は無視されます。集計により、結果の行は重複しないことが既に保証されています。
例
次のステートメントは、教職員 ID 111191115 が担当するすべての講座を取得します。2 番目のステートメントでは DISTINCT を使用して、列の値が重複する行を取り除いています。
SELECT c.Name, c.Description
FROM Course c, class cl
WHERE c.name = cl.name AND cl.faculty_id = '111191115';
Name Description
======= ==================================================
CHE 203 Chemical Concepts and Properties I
CHE 203 Chemical Concepts and Properties I
CHE 205 Chemical Concepts and Properties II
CHE 205 Chemical Concepts and Properties II
SELECT DISTINCT c.Name, c.Description
FROM Course c, class cl
WHERE c.name = cl.name AND cl.faculty_id = '111191115';
Name Description
======= ==================================================
CHE 203 Chemical Concepts and Properties I
CHE 205 Chemical Concepts and Properties II
メモ: 次のような DISTINCT の使用法は許可されていません。
SELECT DISTINCT column1, DISTINCT column2
SELECT DISTINCT column1, DISTINCT column2
関連項目
DISTINCT のその他の使用法については、集計関数の DISTINCTを参照してください。
DROP DATABASE
DROP DATABASE ステートメントにより、データベースを削除します。Master ユーザーのみがこのステートメントを発行できます。
構文
DROP DATABASE [ IF EXISTS ] データベース名 [ DELETE FILES ]
データベース名 ::= ユーザー定義名
備考
このステートメントを発行するには、Master ユーザーとしてデータベースにログオンしている必要があります。DROP DATABASE ステートメントを使用すると、セキュリティ設定で削除が許可されていれば、現在ログオンしているデータベースも含め、あらゆるデータベースを削除できます。以下のセキュリティで保護されたデータベースを参照してください。
DROP DATABASE は、defaultdb や tempdb などのシステム データベースを削除する場合には使用できません。選択し、セキュリティで許可されていれば、このステートメントを使用して最後のユーザー定義データベースを削除できます。
DROP DATABASE ステートメントは、ストアド プロシージャおよびユーザー定義関数内では使用できません。
IF EXISTS 式を指定すると、データベースが存在しない場合、ステートメントはエラーではなく成功を返すようになります。IF EXISTS は、それ以外のエラーを抑制しません。
セキュリティで保護されたデータベース
「データベース」セキュリティ モデルで保護されたデータベースは削除できません。以下の方法でセキュリティ保護されているデータベースは削除できます。
• クラシック セキュリティ
• 混合セキュリティ
• リレーショナル セキュリティ(Master パスワード)と、クラシック セキュリティまたは混合セキュリティの組み合わせ
詳細については、『Advanced Operations Guide』の Zen セキュリティを参照してください。
DELETE FILES
DELETE FILES 句は、データ辞書ファイル(DDF)を削除するためのものです。データ ファイルは削除されません。
DELETE FILES を省略した場合、DDF は物理記憶域に残りますが、データベース名は dbnames.cfg から削除されます。dbnames.cfg から名前が削除されると、そのデータベースはもうデータベース エンジンにとって存在しないことになります。DDF を保持しておくことによって、データベースの再作成を選択した場合にその実行が可能になります。
DDF を削除するとき、DDF は使用中であってはいけないことに注意してください。たとえば、Zen Control Center を開いている場合に DELETE FILES 句を使用すると、"ファイルがロックされています" というエラーが返されます。ZenCC が開いている間は、DDF は使用中であると見なされ、削除されません。
例
次の例によって、データベース名 inventorydb は dbnames.cfg から削除されますが、データベースの DDF(およびデータ ファイル)は物理記憶域に保持されます。
DROP DATABASE inventorydb
————————
次の例では、データベース名 HRUSBenefits とその DDF が削除されます。HRUSBenefits のデータ ファイルは保持されます。
DROP DATABASE HRUSBenefits DELETE FILES
関連項目
DROP FUNCTION
DROP FUNCTION ステートメントにより、データベースからスカラ ユーザー定義関数(UDF)を削除します。
メモ: 存在しない UDF を削除しようとすると、エラー メッセージが表示されます。
構文
DROP FUNCTION [ IF EXISTS ] { 関数名 }
関数名 ::= 削除するユーザー定義関数の名前
備考
IF EXISTS 式を指定すると、関数が存在しない場合、ステートメントはエラーではなく成功を返すようになります。IF EXISTS は、それ以外のエラーを抑制しません。
例
次のステートメントによって、ユーザー定義関数 fn_MyFunc がデータベースから削除されます。
DROP FUNCTION fn_MyFunc
関連項目
DROP GROUP
このステートメントは、セキュリティで保護されているデータベース内の 1 つまたは複数のグループを削除します。
構文
DROP GROUP [ IF EXISTS ] グループ名 [ , グループ名 ]...
備考
Master ユーザーのみがこのステートメントを実行できます。複数のグループはカンマで区切ります。グループを削除するには空である必要があります。
このステートメントを実行するには、セキュリティ設定が有効になっている必要があります。
IF EXISTS 式を指定すると、グループが存在しない場合、ステートメントはエラーではなく成功を返すようになります。IF EXISTS は、それ以外のエラーを抑制しません。
例
次の例ではグループ zengroup が削除されます。
DROP GROUP zengroup
次の例では、リストを使用してグループを削除します。
DROP GROUP zen_dev, zen_marketing
関連項目
DROP INDEX
このステートメントにより、指定されたテーブルから特定のインデックスを削除します。
構文
DROP INDEX [ IF EXISTS ] [ テーブル名.]インデックス名 [ IN DICTIONARY ]
テーブル名 ::= ユーザー定義名
インデックス名 ::= ユーザー定義名
備考
IN DICTIONARY は高度な機能です。絶対に必要な場合に、システム管理者のみが使用してください。IN DICTIONARY キーワードを使用すると、基となるデータ ファイルからはインデックスを削除せずに、DDF からインデックスを削除できます。通常、Zen は DDF とデータ ファイルの正確な同期を保ちますが、この機能によりユーザーは、同期していないテーブルの辞書定義を既存のデータ ファイルに合致させることが柔軟に行えるようになります。これは、既存のデータ ファイルと合致する新しい定義を辞書内に作成したい場合に有用です。
注意! DDF の変更を、基となるデータ ファイルへの変更に合わせて行わないと、重大な問題が生じることがあります。
IF EXISTS 式を指定すると、インデックスが存在しない場合、ステートメントはエラーではなく成功を返すようになります。IF EXISTS は、それ以外のエラーを抑制しません。
この機能の詳細については、IN DICTIONARY の説明を参照してください。
部分インデックス
部分インデックスを削除する場合、PARTIAL 修飾子は必要ありません。
例
次のステートメントによって、指定された名前付きインデックスが Faculty テーブルから削除されます。
DROP INDEX Faculty.Dept
————————
次の例では、データ ファイルと関連付けられない「デタッチされた」テーブルが作成され、その後でテーブル定義へのインデックスの追加と削除が行われます。インデックスは、関連付けられる基となる Btrieve インデックスが存在しないため、デタッチされたインデックスとなります。
CREATE TABLE t1 IN DICTIONARY (c1 int, c2 int)
CREATE INDEX idx_1 IN DICTIONARY on t1(c1)
DROP INDEX t1.idx_1 IN DICTIONARY
関連項目
DROP PROCEDURE
このステートメントにより、現行データベースから 1 つまたは複数のストアド プロシージャを削除します。
構文
DROP PROCEDURE [ IF EXISTS ] プロシージャ名
備考
IF EXISTS 式を指定すると、プロシージャが存在しない場合、ステートメントはエラーではなく成功を返すようになります。IF EXISTS は、それ以外のエラーを抑制しません。
例
次のステートメントによって、ストアド プロシージャ myproc が辞書から削除されます。
DROP PROCEDURE myproc
関連項目
DROP TABLE
このステートメントにより、指定されたデータベースからテーブルを削除します。
構文
DROP TABLE [ IF EXISTS ] テーブル名 [ IN DICTIONARY ]
テーブル名 ::= 削除するテーブルのユーザー定義名
IN DICTIONARY
ALTER TABLE の IN DICTIONARY の解説を参照してください。
備考
テーブルに依存しているトリガーがある場合、テーブルは削除されません。
トランザクションが進行中で、それがテーブルを参照している場合は、エラーが表示されてテーブルは削除されません。
削除するテーブルにほかのテーブルが依存している場合は、テーブルの削除に失敗します。
主キーが存在する場合は削除されます。テーブルを削除する前にユーザーが主キーを削除する必要はありません。テーブルの主キーが別のテーブルに属する制約によって参照されている場合、テーブルは削除されず、エラーが表示されます。
テーブルに外部キーがある場合、外部キーは削除されます。
テーブルにその他の制約(たとえば、NOT NULL、CHECK、UNIQUE、NOT MODIFIABLE など)がある場合、テーブルが削除されるとそれらの制約は削除されます。
IF EXISTS 式を指定すると、テーブルが存在しない場合、ステートメントはエラーではなく成功を返すようになります。IF EXISTS は、それ以外のエラーを抑制しません。
例
次のステートメントによって、class テーブル定義が辞書から削除されます。
DROP TABLE Class
関連項目
DROP TRIGGER
このステートメントにより、現行データベースからトリガーを削除します。
構文
DROP TRIGGER [ IF EXISTS ] トリガー名
備考
IF EXISTS 式を指定すると、トリガーが存在しない場合、ステートメントはエラーではなく成功を返すようになります。IF EXISTS は、それ以外のエラーを抑制しません。
例
次の例では、InsTrig という名前のトリガーが削除されます。
DROP TRIGGER InsTrig
関連項目
DROP USER
DROP USER ステートメントは、データベースからユーザー アカウントを削除します。
構文
DROP USER [ IF EXISTS ] ユーザー名 [ , ユーザー名 ]...
備考
Master ユーザーのみがこのステートメントを実行できます。
このステートメントを実行するには、セキュリティ設定が有効になっている必要があります。
複数のユーザーはカンマで区切ります。
ユーザー名に空白やその他の非英数文字が含まれる場合は、ユーザー名を二重引用符で囲む必要があります。
ユーザー アカウントを削除しても、そのユーザーが作成したテーブルや、ビュー、その他のデータベース オブジェクトは削除されません。
IF EXISTS 式を指定すると、ユーザーが存在しない場合、ステートメントはエラーではなく成功を返すようになります。IF EXISTS は、それ以外のエラーを抑制しません。
ユーザーとグループの詳細については、『Advanced Operations Guide』の Master ユーザー、ユーザーとグループ、および『Zen User's Guide』の権限の割り当て作業を参照してください。
例
次の例では、ユーザー アカウント pgranger を削除します。
DROP USER pgranger
————————
次の例では、複数のユーザー アカウントを削除します。
DROP USER pgranger, "lester pelling"
関連項目
DROP VIEW
このステートメントにより、データベースから指定されたビューを削除します。
構文
DROP VIEW [ IF EXISTS ] ビュー名
ビュー名 ::= ユーザー定義名
備考
IF EXISTS 式を指定すると、ビューが存在しない場合、ステートメントはエラーではなく成功を返すようになります。IF EXISTS は、それ以外のエラーを抑制しません。
例
次のステートメントによって、vw_person ビュー定義が辞書から削除されます。
DROP VIEW vw_person
関連項目
END
備考
BEGIN [ATOMIC] の解説を参照してください。
EXECUTE
EXECUTE ステートメントには 2 とおりの使い方があります。
• ユーザー定義のプロシージャまたはシステム ストアド プロシージャを呼び出す場合。CALL ステートメントの代わりに EXECUTE ステートメントを使用できます。
• ストアド プロシージャ内で、文字列または、文字列を返す式を実行する場合。
構文
ストアド プロシージャを呼び出す場合:
EXEC[UTE] ストアド プロシージャ [ ( [ プロシージャ パラメーター [ , プロシージャ パラメーター ]... ] ) ]
ストアド プロシージャ ::= ストアド プロシージャの名前
プロシージャ パラメーター ::= ストアド プロシージャが必要とする入力パラメーター
ユーザー定義のストアド プロシージャ内の場合:
EXEC[UTE] ( 文字列 [ + 文字列 ]... )
文字列 ::= 文字列、文字列変数、または文字列を返す式
備考
ストアド プロシージャ構文の EXEC[UTE] (文字列...) は、NCHAR 値のリテラルおよび変数をサポートしていません。文字列の構築に使用される値は、実行前に CHAR 値へ変換されます。
例
次の例では、パラメーターのないプロシージャを実行します。
EXEC NoParms() または CALL NoParms
次の例では、パラメーターのあるプロシージャを実行します。
EXEC Parms(vParm1, vParm2)
EXECUTE CheckMax(N.Class_ID)
————————
次のプロシージャは、Billing テーブルから Student_ID を取り出します。
CREATE PROCEDURE tmpProc(IN :vTable CHAR(25)) RETURNS (sID INTEGER) AS
BEGIN
EXEC ('SELECT Student_ID FROM ' + :vtable);
END;
EXECUTE tmpProc('Billing')
関連項目
EXISTS
EXISTS キーワードを使用して、サブクエリの結果に行があるかどうかを検査します。サブクエリに行が含まれていれば、True が返されます。
構文
EXISTS ( サブクエリ )
備考
外部クエリが評価するすべての行について、Zen はサブクエリ内に関連する行が存在するかどうかを検査します。Zen は、外部クエリの結果のうち、サブクエリ内の関連する行に対応する各行を、ステートメントの結果テーブルに含めます。
EXISTS はストアド プロシージャ内のサブクエリにも使用できます。ただし、ストアド プロシージャ内のサブクエリ SELECT ステートメントに COMPUTE 句または INTO キーワードを含めることはできません。
多くの場合、EXISTS を含むサブクエリは IN を使って書き直すことができます。Zen は、IN を使用しているクエリの方がより効率的に処理できます。
例
次のステートメントは、成績評価点平均が 4.0 の人だけを含むリストを返します。
SELECT * FROM Person p WHERE EXISTS
(SELECT * FROM Enrolls e WHERE e.Student_ID = p.id
AND Grade = 4.0)
IN を使って、このステートメントを書き直すことができます。
SELECT * FROM Person p WHERE p.id IN
(SELECT e.Student_ID FROM Enrolls WHERE Grade = 4.0)
————————
次のプロシージャは、入力パラメーターの値を使って、Person テーブルから ID を選択します。プロシージャの最初の実行(EXEC)では、"Exists は true を返しました" が返ります。2 番目の EXEC では "Exists は false を返しました" が返ります。
CREATE PROCEDURE ex1(IN :vID INTEGER) RETURNS ( d1 VARCHAR(30) ) AS
BEGIN
IF EXISTS (SELECT id FROM person WHERE id < :vID)
THEN PRINT 'Exists は true を返しました';
ELSE PRINT 'Exists は false を返しました';
END IF;
END;
EXEC ex1(222222222);
EXEC ex1(1);
関連項目
FETCH
構文
FETCH [ [NEXT] FROM ] カーソル名 INTO 変数名
カーソル名 ::= ユーザー定義名
備考
FETCH ステートメントにより、指定したテーブル行に SQL カーソルを位置付け、ターゲット リストに値を入れる変数を配置して、その行から値を取り出します。
カーソルからデータをフェッチする場合は、NEXT および FROM キーワードを省略することができます。
メモ: Zen は前方スクロール タイプのカーソルのみサポートします。そのため、NEXT FROM を省略しても、カーソル レコードの流れを制御することはできません。
例
この例の FETCH ステートメントでは、カーソル c1 の値が OldName 変数に取り込まれます。また、位置付け UPDATE ステートメントにより、同じ Demodata サンプル データベース内の Course テーブルの Modern European History(HIS 305)の行が更新されます。
CREATE PROCEDURE UpdateClass();
BEGIN
DECLARE :CourseName CHAR(7);
DECLARE :OldName CHAR(7);
DECLARE c1 CURSOR FOR SELECT name FROM course WHERE name = :CourseName;
OPEN c1;
SET :CourseName = 'HIS 305';
FETCH NEXT FROM c1 INTO :OldName;
UPDATE SET name = 'HIS 306' WHERE CURRENT OF c1;
END;
————————
CREATE PROCEDURE MyProc(OUT :CourseName CHAR(7)) AS
BEGIN
DECLARE cursor1 CURSOR
FOR SELECT Degree, Residency, Cost_Per_Credit FROM Tuition ORDER BY ID;
OPEN cursor1;
FETCH NEXT FROM cursor1 INTO :CourseName;
CLOSE cursor1;
END
関連項目
FOREIGN KEY
備考
テーブル定義に外部キーを追加するには、ADD 句で FOREIGN KEY キーワードを使用します。
メモ: 外部キーを追加したり、その他の参照整合性(RI)操作を行ったりするには、その前にデータベース名を使用してデータベースにログインする必要があります。また、セキュリティが有効になっている場合は、外部キーの参照先テーブルの参照権がなければ、キーを追加できません。
従属テーブルに外部キーを定義するには、FOREIGN KEY 句を CREATE TABLE ステートメントで使用します。キーに列のリストを指定するだけでなく、キーの名前を定義できます。
外部キー列の列は、ヌル値を許可できます。ただし、インデックスに擬似ヌルの列が含まれていないことを確認してください。擬似ヌルの値はインデックスが作成されません。
外部キー名は、辞書内で固有の名前である必要があります。外部キー名を省略すると、Zen はキーの最初の列の名前を外部キー名として使用します。その名前の外部キーが辞書に既に含まれる場合は、外部キー名の重複エラーが発生します。
外部キーを指定すると、Zen によって、キーを構成する列のインデックスが作成されます。このインデックスは、対応する主キーのインデックスと同じ属性を持ちますが、値の重複が可能です。インデックスにほかの属性を割り当てるには、CREATE INDEX ステートメントを使用して明示的にインデックスを作成します。その後、ALTER TABLE ステートメントを使用して外部キーを定義します。インデックスを作成するときは、ヌル値が許可されず、大文字小文字の区別と照合順序の属性が、対応する主キー列のインデックスの属性と一致しているようにします。
外部キーの列は、主キーの参照先の列と、データ型、長さ、順序が同じである必要があります。唯一の例外は、外部キーでは整数列を使用して、主キーの IDENTITY、SMALLIDENTITY、または BIGIDENTITY 列を参照できることです。この場合、2 つの列は長さが同じである必要があります。
Zen は、テーブルを作成する前に、外部キーに例外がないかどうかを調べます。以前に定義された参照整合性(RI)制約に違反する状態が見つかった場合は、ステータス コードを生成し、テーブルを作成しません。
メモ: 既にデータを含むテーブルに外部キーを作成する際には、Zen は外部キー列および主キー列に既にあるデータ値を検証しません。この制限は、外部キーが作成された後の INSERT、UPDATE、DELETE 操作に適用されます。
外部キーを定義するときに、対応する主キーが含まれるテーブルの名前を指定する REFERENCES 句を含める必要があります。親テーブルの主キーは事前に定義されている必要があります。また、データベースのセキュリティが有効になっている場合は、主キーが含まれるテーブルの参照権が必要です。
CREATE TABLE ステートメントを使用して、自己参照を行う外部キーを作成することはできません。同じテーブルの主キーを参照する外部キーを作成するには、ALTER TABLE ステートメントを使用します。
また、1 つのステートメントで、同じ列セットに対する主キーと外部キーは作成できません。そのため、作成しているテーブルの主キーが別のテーブルの外部キーでもある場合は、ALTER TABLE ステートメントを使用して外部キーを作成する必要があります。
例
次のステートメントは、Class テーブルに新規の外部キーを追加します。(Faculty の ID 列はインデックスとして定義されており、ヌル値は含まれません。)
ALTER TABLE Class ADD CONSTRAINT Teacher FOREIGN KEY (Faculty_ID) REFERENCES Faculty ON DELETE RESTRICT
この例では、削除制限規則によって、ある教職員を削除しようとするとき、最初にその教職員の全講座を変更または削除しないとその教職員をデータベースから削除できないようになっています。
関連項目
GRANT
セキュリティで保護されたデータベースでは、GRANT ステートメントを使用して、テーブル、ビュー、およびストアド プロシージャのアクセス権限を管理します。GRANT では、これらの権限をユーザーに付与したり、新しいユーザーを作成したり、そのユーザーを既存のユーザー グループに割り当てたりすることができます。必要に応じて、GRANT を使用する前に、CREATE GROUP を使用して新しいグループを作成します。
以下のトピックでは、GRANT ステートメントの使用について説明します。
• 権限の制約
構文
GRANT CREATETAB | CREATEVIEW | CREATESP TO public またはユーザー/グループ名 [ , ユーザー/グループ名 ]...
GRANT LOGIN TO ユーザーおよびパスワード [ , ユーザーおよびパスワード ]... [ IN GROUP グループ名 ]
GRANT 権限 ON < * | [ TABLE ] テーブル名 [ オーナー ネーム ] | VIEW ビュー名 | PROCEDURE ストアド プロシージャ名 >
TO ユーザー/グループ名 [ , ユーザー/グループ名 ]...
* ::= すべてのオブジェクト(つまり、すべてのテーブル、ビュー、およびストアド プロシージャ)
権限 ::= ALL
| ALTER
| DELETE
| INSERT [ ( テーブルの列名[ , テーブルの列名 ]... ) ]
| REFERENCES
| SELECT [ ( テーブルの列名[ , テーブルの列名 ]... ) ]
| UPDATE [ ( テーブルの列名[ , テーブルの列名 ]... ) ]
| EXECUTE
テーブル名 ::= ユーザー定義のテーブル名
オーナー ネーム ::= ユーザー定義のオーナー ネーム
ビュー名 ::= ユーザー定義のビュー名
ストアド プロシージャ名 ::= ユーザー定義のストアド プロシージャ名
ユーザーおよびパスワード ::= ユーザー名 [:] パスワード
public またはユーザー/グループ名 ::= PUBLIC | ユーザー/グループ名
ユーザー/グループ名 ::= ユーザー名 | グループ名
ユーザー名 ::= ユーザー定義のユーザー名
テーブルの列名 ::= ユーザー定義の列名(テーブルのみ)
備考
CREATETAB、CREATESP、CREATEVIEW、および LOGIN TO キーワードは、SQL 文法の拡張機能です。GRANT ステートメントを使用して、CREATE TABLE、CREATE VIEW、および CREATE PROCEDURE に権限を付与することができます。次の表は、特定の操作に対する構文を示しています。
この操作に権限を付与する場合 | GRANT で使用するキーワード |
|---|---|
CREATE TABLE | CREATETAB |
CREATE VIEW | CREATEVIEW |
CREATE PROCEDURE | CREATESP |
LOGIN AS GROUP MEMBER | LOGIN TO |
CREATETAB、CREATEVIEW、および CREATESP は明示的に付与する必要があります。これらの権限は、GRANT ALL ステートメントの一部として含まれません。
GRANT LOGIN TO
GRANT LOGIN TO はユーザーを作成し、そのユーザーにセキュリティで保護されたデータベースへのアクセスを許可します。ユーザーを作成するには、ユーザー名とパスワードを指定する必要があります。任意で、ユーザーに既存のグループを使用するか、または GRANT LOGIN TO を使用する前に CREATE GROUP で新しいグループを作成することができます。
権限の制約
オブジェクトの権限には次の制約が適用されます。
オブジェクトの種類別
次の表は、オブジェクトの種類に適用される権限を示しています。
権限 | テーブル1 | ビュー1 | ストアド プロシージャ |
|---|---|---|---|
CREATETAB | X | ||
CREATEVIEW | X | ||
CREATESP | X | ||
ALTER2 | X | X | X |
DELETE | X | X | |
INSERT | X | X | |
REFERENCES | X | ||
SELECT | X | X | |
UPDATE | X | X | |
EXECUTE3 | X | ||
1 列はテーブルに対してのみ指定できます。ビューの権限はビュー全体に対してのみ付与でき、単一の列に対して付与することはできません。 2 テーブル、ビュー、またはストアド プロシージャを削除するには、ユーザーは対象オブジェクトの ALTER 権限を持っている必要があります。信頼されるビューおよびストアド プロシージャを削除できるのは、Master ユーザーのみです。 3 EXECUTE はストアド プロシージャにのみ適用されます。ストアド プロシージャを実行できるのは、CALL ステートメントまたは EXECUTE ステートメントのいずれかです。プロシージャは、信頼されるものでも信頼されないものでもかまいません。信頼されるオブジェクトと信頼されないオブジェクトを参照してください。 | |||
ALL キーワード
次の表は、オブジェクトの種類で ALL によって付与される権限を示しています。
ALL によって含まれる権限 | テーブル | ビュー | ストアド プロシージャ |
|---|---|---|---|
ALTER1 | X | X | X |
DELETE | X | X | |
INSERT | X | X | |
REFERENCES | X | ||
SELECT | X | X | |
UPDATE | X | X | |
EXECUTE | X | ||
1 テーブル、ビュー、またはストアド プロシージャを削除するには、ユーザーは対象オブジェクトの ALTER 権限を持っている必要があります。信頼されるビューおよびストアド プロシージャを削除できるのは、Master ユーザーのみです。 | |||
たとえば、GRANT ALL ON * to User1 を発行した場合、User1 は表に挙げられているすべての権限を持ちます。
GRANT ALL ON VIEW myview1 TO User2 を発行した場合、User2 は myview1 の ALTER、DELETE、INSERT、UPDATE、および SELECT 権限を持ちます。
GRANT とデータのセキュリティ
以下のトピックでは、データのセキュリティを管理するための GRANT の特定用途について説明します。
ユーザーおよびグループへの権限の付与
リレーショナル セキュリティは、セキュリティを有効にしたときに、データベースヘのフル アクセス権を持つ Master という名前のデフォルト ユーザーが存在するかどうかに基づきます。セキュリティを有効にすると、Master ユーザーにパスワードの指定が必要になります。
このステートメントを実行するには、セキュリティ設定が有効になっている必要があります。
Master ユーザーは、GRANT LOGIN TO、CREATE USER、または CREATE GROUP コマンドを使用してグループやほかのユーザーを作成したり、作成したグループやユーザーのデータ アクセス権を管理したりすることができます。
すべてのユーザーに同一の権限を付与したい場合は、PUBLIC グループに権限を付与します。すべてのユーザーは、PUBLIC グループに割り当てられているデフォルトの権限を継承します。
メモ: グループを使用する場合は、ユーザーを作成する前にグループを設定する必要があります。
ユーザー名とパスワードに空白またはその他の非英数文字が含まれる場合は、ユーザー名とパスワードを二重引用符で囲む必要があります。
ユーザーとグループの詳細については、『Advanced Operations Guide』の Master ユーザー、ユーザーとグループ、および『Zen User's Guide』の権限の割り当て作業を参照してください。
オーナー ネームによるアクセス権の付与
オーナー ネームは、Btrieve ファイルへのアクセスのロックを解除するバイト文字列です。Btrieve オーナー ネームは、オペレーティング システムのユーザー名やデータベース ユーザー名とはまったく関係なく、ファイル アクセス パスワードとして機能します。詳細については、オーナー ネームを参照してください。
セキュリティで保護された SQL データベース内のテーブルとして、オーナー ネームを持つ Btrieve ファイルがある場合、データベースの Master ユーザーは、そのテーブルにアクセスする権限をユーザー(Master ユーザー自身も含む)に付与するためには、GRANT ステートメントでオーナー ネームを提供する必要があります。
Master ユーザーが 1 人のユーザーに対して GRANT ステートメントを実行した場合、そのユーザーはデータベースにログインするだけで、オーナー ネームを指定しなくても、テーブルにアクセスできるようになります。この認証は、現在のデータベース接続の期間中持続します。また、SET OWNER ステートメントを使用すると、接続セッションに対して 1 つまたは複数のオーナー ネームを指定できることに留意してください。SET OWNER を参照してください。
ユーザーがオーナー ネームを持つテーブルに対して SQL コマンドを実行しようとした場合、Master ユーザーが GRANT ステートメントでオーナー ネームを使用することにより、そのユーザーにテーブルへのアクセス権を付与していない限り、アクセスは拒否されます。
テーブルのオーナー ネームに読み取り専用設定が選択されている場合は、すべてのユーザーがこのテーブルの SELECT 権限を持ちます。
ビューおよびストアド プロシージャに対する権限
ビューおよびストアド プロシージャは、そのビューまたはストアド プロシージャによって参照されるオブジェクトに対してどのように権限を処理したいかに応じて、信頼されるものでも信頼されないものでも指定できます。
信頼されるオブジェクトと信頼されないオブジェクト
ビューおよびストアド プロシージャは、テーブルやその他のビュー、その他のストアド プロシージャなどのオブジェクトを参照します。参照されるオブジェクトごとに権限を付与することは、オブジェクトとユーザーの数に応じて、非常に時間のかかるものとなります。多様な状況に合ったより簡潔な解決法として、信頼されるビューまたは信頼されるストアド プロシージャという概念があります。
信頼されるビューまたはストアド プロシージャとは、参照されるオブジェクトごとに権限を明示的に設定しなくても実行できるものです。たとえば、信頼されるビュー myview1 がテーブル t1 と t2 を参照している場合、Master ユーザーは t1 および t2 に権限を付与しなくても myview1 に権限を付与することができます。
信頼されないビューまたはストアド プロシージャとは、参照されるオブジェクトごとに権限を明示的に設定しなければ実行できないものです。
次の表では、信頼されるオブジェクトと信頼されないオブジェクトの特性を比較しています。
オブジェクト | 特性 | 注記 |
|---|---|---|
信頼されるビューまたは信頼されるストアド プロシージャ | メタデータ バージョン 2 を必要とします。 | Zen メタデータを参照してください。 |
CREATE ステートメントに WITH EXECUTE AS 'MASTER' 句を必要とします | CREATE VIEW および CREATE PROCEDURE を参照してください。 | |
Master ユーザーのみがオブジェクトを作成できます | 『Advanced Operations Guide』の Master ユーザーを参照してください。 | |
Master ユーザーのみがオブジェクトを削除できます | DROP VIEW および DROP PROCEDURE を参照してください。 | |
Master ユーザーはほかのユーザーにオブジェクト権限を付与する必要があります | デフォルトでは、Master ユーザーのみが信頼されるビューまたはストアド プロシージャにアクセスできるので、Master ユーザーがこれらのオブジェクトに権限を付与しなければなりません。 | |
GRANT および REVOKE ステートメントはオブジェクトに適用されます | REVOKE も参照してください。 | |
オブジェクトは、セキュリティで保護されたデータベースまたは保護されていないデータベースに存在することができます | 『Advanced Operations Guide』の Zen セキュリティを参照してください。 | |
信頼されるオブジェクトを信頼されないオブジェクトに変更する(またはその逆)には、オブジェクトを削除してから再作成する必要があります | ビューやストアド プロシージャ用の ALTER ステートメントを使用して、オブジェクトの信頼に関する特性の追加、削除を行うことはできません。信頼されるオブジェクトを信頼されないオブジェクトに変更しなければならない場合は、まずそのオブジェクトを削除してから、WITH EXECUTE AS 'MASTER' 句を指定しないでオブジェクトを作り直します。同様に、信頼されないオブジェクトを信頼されるオブジェクトに変更しなければならない場合は、まずそのオブジェクトを削除してから、WITH EXECUTE AS 'MASTER' 句を指定してオブジェクトを作り直します。 | |
信頼されないビューまたは信頼されないストアド プロシージャ | 任意のユーザーがオブジェクトを作成できます | ユーザーには CREATEVIEW または CREATESP 権限が付与されている必要があります。備考を参照してください。 |
任意のユーザーがオブジェクトを削除できます | ユーザーには、ビューまたはストアド プロシージャに対する ALTER 権限が付与されている必要があります。GRANT を参照してください。 | |
オブジェクトを削除するには ALTER 権限が必要となります | ALTER 権限は、テーブルを削除する場合にも必要です。デフォルトでは、Master ユーザーのみが信頼されるオブジェクトを削除できることに注意してください。ビューまたはストアド プロシージャの作成者でない(Master 以外の)ユーザーがビューやストアド プロシージャを削除するには、ALTER 権限が付与されている必要があります。 | |
デフォルトで、すべてのユーザーはオブジェクトに対するすべての権限を持っています | メタデータ バージョン 2 では、セキュリティで保護されていないデータベースに信頼されないオブジェクトが含まれている場合、データベースのセキュリティを有効にすれば、信頼されないオブジェクトのすべての権限は自動的に PUBLIC に付与されます。 | |
ビューまたはストアド プロシージャを実行するユーザーは、これらから参照されるオブジェクトの権限を必要とします | ユーザーは、最上位のオブジェクトに対する権限も持っている必要があります。つまり、ほかのオブジェクトを参照するビューやストアド プロシージャに対する権限ということです。 | |
GRANT および REVOKE ステートメントはオブジェクトに適用されます | ||
オブジェクトは、セキュリティで保護されたデータベースまたは保護されていないデータベースに存在することができます | 『Advanced Operations Guide』の Zen セキュリティを参照してください。 | |
信頼されるオブジェクトを信頼されないオブジェクトに変更する(またはその逆)には、オブジェクトを削除してから再作成する必要があります | 前述の、信頼されるビューまたは信頼されるストアド プロシージャの場合と同様です。 |
例
このセクションでは、GRANT のいくつかの例を示します。
GRANT ALL ステートメントは、指定したユーザーまたはグループに INSERT、UPDATE、ALTER、SELECT、DELETE、および REFERENCES の権限を付与します。また、辞書の CREATE TABLE 権限も付与されます。次のステートメントによって、ユーザー dannyd にテーブル Class の上記のすべての権限が付与されます。
GRANT ALL ON Class TO dannyd
————————
次のステートメントによって、ユーザー debieq にテーブル Class の ALTER 権限が付与されます。
GRANT ALTER ON Class TO debieq
————————
次のステートメントによって、ユーザー keithv および miked に、テーブル Class の INSERT 権限が付与されます。このテーブルは winsvr644AdminGrp というオーナー ネームを持ちます。
GRANT INSERT ON Class winsvr644AdminGrp TO keithv, miked
————————
次のステートメントによって、ユーザー keithv および miked に、テーブル Class の INSERT 権限が付与されます。
GRANT INSERT ON Class TO keithv, miked
————————
次のステートメントによって、ユーザー keithv および brendanb に、Person テーブル内の 2 つの列 First_name と Last_name の INSERT 権限が付与されます。
GRANT INSERT(First_name,last_name) ON Person to keithv,brendanb
————————
次のステートメントによって、ユーザー aideenw および punitas に CREATE TABLE 権限が付与されます。
GRANT CREATETAB TO aideenw, punitas
————————
次の GRANT LOGIN TO ステートメントは ravi という名前のユーザーにログイン権限を与え、パスワード password を指定します。
GRANT LOGIN TO ravi:password
メモ: GRANT LOGIN TO ステートメントを使用してログイン権限を与えられたユーザー アカウントが現存しない場合、そのユーザー アカウントが作成されます。
ストアド プロシージャで GRANT LOGIN ステートメントを使用する場合は、ユーザー名とパスワードをコロンではなく空白文字で区切る必要があります。コロン文字は、ストアド プロシージャ内でローカル変数の識別に使用されます。
ストアド プロシージャで GRANT LOGIN ステートメントを使用する場合は、ユーザー名とパスワードをコロンではなく空白文字で区切る必要があります。コロン文字は、ストアド プロシージャ内でローカル変数の識別に使用されます。
このユーザー名およびパスワードは Zen データベースのみを対象としたもので、オペレーティング システムまたはネットワークの認証に使用されるユーザー名およびパスワードとは無関係です。Zen ユーザー名、グループ、およびパスワードは Zen Control Center(ZenCC)を使用して設定することもできます。
次の例では、dannyd と rgarcia という名前のユーザーにログイン権限が与えられ、パスワードがそれぞれ password、1234567 と指定されます。
GRANT LOGIN TO dannyd:password,rgarcia:1234567
名前に空白が含まれる場合は、次のように二重引用符を使用できます。このステートメントによって、Jerry Gentry と Punita という名前のユーザーにログイン権限が与えられ、パスワードがそれぞれ sun、moon と指定されます。
GRANT LOGIN TO ''Jerry Gentry'' :sun, Punita:moon
次の例では、パスワード 123456 を持つ Jerry Gentry という名前のユーザーと、パスワード abcdef を持つ rgarcia という名前のユーザーにログイン権限が与えられます。また、グループ zen_dev にこれらのユーザーが追加されます。
GRANT LOGIN TO "Jerry Gentry":123456, rgarcia:abcdef IN GROUP zen_dev
————————
Master ユーザーは、オーナー ネームを持たないテーブルのすべての権限を持ちます。Btrieve オーナー ネームを持つテーブルの権限を付与するには、Master ユーザーは GRANT ステートメントで正しいオーナー ネームを指定しなければなりません。
次の例では、Master ユーザーに Btrieve オーナー ネーム abcd を持つテーブル t1 の SELECT 権限が与えられます。
GRANT SELECT ON t1 'abcd' TO Master
テーブルのオーナー ネームは、ZenCC の[ツール]メニューにある Function Executor または Maintenance ユーティリティを使用して設定できます。詳細については、『Advanced Operations Guide』のオーナー ネームを参照してください。
————————
Master ユーザーによる次の SQL ステートメント セットの実行後、ユーザー jsmith は現在のデータベース内のすべてのテーブルに対する SELECT 権を持ちます。また、ユーザーは tab1 の DELETE 権および tab2 の UPDATE 権も持ちます。
GRANT DELETE ON tab1 TO jsmith
GRANT SELECT ON * TO jsmith
GRANT UPDATE ON tab2 TO jsmith
その後、CREATE TABLE 権を持つユーザーによって次のステートメントが実行された場合、ユーザー jsmith は新しく作成されたテーブルの SELECT 権を持ちます。
CREATE TABLE tab3 (col1 INT)
————————
GRANT CREATETAB TO user1
————————
GRANT CREATESP TO user1
————————
次の例では、すべてのユーザーにストアド プロシージャ cal_rtrn_rate の EXECUTE 権限が付与されます。
GRANT EXECUTE ON PROCEDURE cal_rtrn_rate TO PUBLIC
————————
次の例は、Accounting グループのメンバーは employee テーブルの salary 列だけを更新できることを示しています(employee は Demodata サンプル データベースの一部です)。
次のようなストアド プロシージャが存在するとします。
CREATE PROCEDURE employee_proc_upd(in :EmpID integer, in :Salary money) WITH EXECUTE AS 'Master';
BEGIN
UPDATE employee SET Salary = :Salary WHERE EmployeeID = :Empid;
END
GRANT EXECUTE ON PROCEDURE employee_proc_upd TO Accounting
グループ Accounting に属するユーザーは、Employee テーブル内の saraly 以外の列を更新できないことに注目してください。これは、権限がストアド プロシージャに対してのみ付与されており、そのストアド プロシージャが saraly 列のみを更新するためです。
————————
次の例では、Demodata サンプル データベースのセキュリティが有効で、ユーザー名 USAcctsMgr が追加されているものとします。ここで、そのユーザーに対し、テーブル Person の ID 列への SELECT 権を付与します。以下のステートメントを使用します。
GRANT SELECT ( ID ) ON Person TO 'USAcctsMgr'
関連項目
GROUP BY
SELECT ステートメント中の GROUP BY 構文に加えて、Zen では、ベンダー文字列を含むことができる拡張された GROUP BY 構文もサポートしています。
GROUP BY クエリを行うと、見つかったグループごとに 1 行の選択リストを含む結果セットが返されます(選択リストの構文については、SELECT を参照してください)。
次の例では、エスケープ シーケンス内にベンダー文字列を含む、拡張 GROUP BY を示します。
create table at1 (col1 integer, col2 char(10));
insert into at1 values (1, 'abc');
insert into at1 values (2, 'def');
insert into at1 values (3, 'aaa');
SELECT (--(*vendor(Microsoft), product(ODBC) fn left(at1.col2, 1) *)--) atv, count(*) Total FROM at1
GROUP BY atv
ORDER BY atv DESC
戻り値:
atv Total
====== ===========
d 1
a 2
関連項目
HAVING
HAVING 句は SELECT ステートメントの中で GROUP BY キーワードと一緒に使用して、集計値が特定の基準を満たしているグループのみを表示します。
HAVING 句内の式には、定数、セット関数、または GROUP BY 式リスト内の式の複製を含めることができます。
Zen データベース エンジンは、GROUP BY のない HAVING キーワードをサポートしていません。
HAVING キーワードでは、エイリアスを使用することができます。ただし、エイリアスはテーブル内のどの列名とも異なっていなければなりません。
例
次の例では、講座名が 5 つを超える学部名が返されます。
SELECT Dept_Name, COUNT(*) FROM Course GROUP BY Dept_Name HAVING COUNT(*) > 5
上と同じ例でエイリアス(ここでは dn と ct)を使用して、同様の結果を得られます。
SELECT Dept_Name dn, COUNT(*) ct FROM Course GROUP BY dn HAVING ct > 5
COUNT(式) によって、述部にある式の非ヌル値がすべてカウントされるということを覚えておいてください。COUNT(*) ではヌル値を含むすべての値がカウントされます。
————————
次の例では、講座数が 5 つを超える Accounting という名前の学部名が返されます。
SELECT Dept_Name, COUNT(*) FROM Course GROUP BY Dept_Name HAVING COUNT(*) > 5 AND Dept_Name = 'Accounting'
関連項目
IF
構文
IF ( ブール条件 )
BEGIN
SQL ステートメント
END
ELSE
BEGIN
SQL ステートメント
END
備考
IF ステートメントにより、条件の値に基づく条件付き実行を提供します。IF ... THEN ... ELSE ... END IF 構造は、2 つのステートメント ブロックのどちらに基づいて実行するかをフロー制御します。IF ... ELSE 構文も使用できます。
IF ステートメントは、ストアド プロシージャとトリガーの本体で使用できます。
IF ステートメントをネストできる数に制限はありませんが、クエリは通常どおり、合計長の制限やその他のアプリケーション制限の影響を受けます。
メモ: Zen と T.SQL の構文の混合構文を使用することはできません。IF...THEN...ELSE...END IF 構文または IF...ELSE 構文のいずれかを使用できます。IF または ELSE 条件で複数のステートメントを使用する場合は、BEGIN と END を使ってステートメント ブロックの始まりと終わりを示す必要があります。
例
次の例では、IF ステートメントを使用して、vInteger の値が正か負かによって変数 Negative を 1 または 0 に設定します。
IF (:vInteger < 0) THEN
SET :Negative = '1';
ELSE
SET :Negative = '0';
END IF;
————————
次の例では、IF ステートメントを使用して、定義された条件(SQLSTATE = '02000')のループをテストします。この条件が満たされた場合、WHILE ループが終了します。
FETCH_LOOP:
WHILE (:counter < :NumRooms) DO
FETCH NEXT FROM cRooms INTO :CurrentCapacity;
IF (SQLSTATE = '02000') THEN
LEAVE FETCH_LOOP;
END IF;
SET :counter = :counter + 1;
SET :TotalCapacity = :TotalCapacity +
:CurrentCapacity;
END WHILE;
IF(:vInteger >50)
BEGIN
SET :vInteger = :vInteger + 1;
INSERT INTO test VALUES('Test');
END;
ELSE
SET :vInteger = :vInteger - 1;
関連項目
IN
備考
IN 演算子を使用して、外部クエリの結果が、サブクエリの結果に含まれるかどうかを検査します。ステートメントの結果テーブルには、外部クエリが返す行で、サブクエリ内に関連する行があるものだけが含まれます。
例
次の例は、Chemistry 408 を受講した全学生の名前をリストします。
SELECT p.First_Name + ' ' + p.Last_Name FROM Person p, Enrolls e WHERE (p.id = e.student_id) AND (e.class_id IN
(SELECT c.ID FROM Class c WHERE c.Name = 'CHE 408'))
Zen では、まずサブクエリが評価され、Class テーブルから Chemistry 408 の ID が取得されます。次に外部クエリが実行され、結果は、その講座の Enrolls テーブルにエントリがある学生だけに制限されます。
一般に、IN クエリは、EXISTS キーワードまたは制限句を持つ簡単な結合条件を使用すると、より効率的に行うことができます。Zen では、サブクエリよりも結合の方が効率的に最適化されます。そのため、クエリの目的がデータベースのサブセットでの値の有無を判定することでない限り、簡単な結合条件を使用する方が効率的です。
関連項目
INSERT
このステートメントにより、1 つのテーブルに列の値を挿入します。
構文
INSERT INTO テーブル名
[ ( 列名 [ , 列名 ]... ) ] 挿入値
[ ON DUPLICATE KEY UPDATE 列名 = < NULL | DEFAULT | 式 | サブクエリ式 [ , 列名 = ... ] >
[ ORDER BY order-by式 [ , order-by式 ]... ]
テーブル名 ::= ユーザー定義名
列名 ::= ユーザー定義名
挿入値 ::= values句 | クエリ スペック
values句 ::= VALUES ( 式 [ , 式 ]... ) | DEFAULT VALUES
式 ::= 式 - 式 | 式 + 式
サブクエリ式 ::= ( クエリ スペック ) [ ORDER BY order-by式
[ , order-by式 ]... ] [ limit句 ]
[ , order-by式 ]... ] [ limit句 ]
クエリ スペック ::= ( クエリ スペック )
FROM テーブル参照 [ , テーブル参照 ]...
[ WHERE 検索条件 ]
[ HAVING 検索条件 ] ]
備考
INSERT ステートメントは、DELETE および UPDATE と同様にアトミックな方法で動作します。つまり、複数の行の挿入に失敗した場合、同じステートメントによって実行された前の行の挿入がすべてロール バックされます。
INSERT ON DUPLICATE KEY UPDATE
Zen v13 R2 では、INSERT ON DUPLICATE KEY UPDATE により、INSERT が拡張されました。この挿入機能は、一意のキーについて、挿入または更新される値と、対象テーブル内の値を自動的に比較します。重複する主キーまたはインデックス キーのいずれかが見つかった場合は、それらの行の値が更新されます。重複する主キーもインデックス キーも見つからなかった場合は、新しい行が挿入されます。一般的な専門用語では、この動作は「upsert」と呼ばれます。
INSERT では、値リストまたは SELECT クエリのいずれかを使用できます。すべての INSERT コマンドと同様に、この動作はアトミックです。
この機能の実例については、INSERT ON DUPLICATE KEY UPDATE の例を参照してください。
リテラル文字列の最大長より長いデータの挿入
Zen でサポートされるリテラル文字列の最大長は 15,000 バイトです。これよりも長いデータを処理するには、直接の SQL ステートメントを使用し、挿入を複数の呼び出しに分割します。次のようなステートメントで開始します。
INSERT INTO table1 SET longfield = '15000 バイトのテキスト' WHERE 制限
次に、それ以上のデータを追加する次のステートメントを発行します。
INSERT INTO table1 SET longfield = notefield + '15000 バイトを超えたテキスト' WHERE 制限
例
INSERT の例
このトピックでは、単純な INSERT の例を示します。重複する一意キーを用いて、挿入ではなく更新する場合については、INSERT ON DUPLICATE KEY UPDATE の例を参照してください。
次のステートメントでは、VALUES 句で式を使ってテーブルにデータを追加しています。
CREATE TABLE t1 (c1 INT, c2 CHAR(20))
INSERT INTO t1 VALUES ((78 + 12)/3, 'This is' + CHAR(32) + 'a string')
SELECT * FROM t1
c1 c2
---------- ----------------
30 This is a string
————————
次のステートメントでは、3 つの VALUES 句を使用して、Course テーブルにデータを直接追加しています。
INSERT INTO Course(Name, Description, Credit_Hours, Dept_Name)
VALUES ('CHE 308', 'Organic Chemistry II', 4, 'Chemistry')
INSERT INTO Course(Name, Description, Credit_Hours, Dept_Name)
VALUES ('ENG 409', 'Creative Writing II', 3, 'English')
INSERT INTO Course(Name, Description, Credit_Hours, Dept_Name)
VALUES ('MAT 307', 'Probability II', 4, 'Mathematics')
————————
以下の INSERT ステートメントでは、SELECT 句を使用して、授業を受けた学生の ID 番号が Student テーブルから取り出されます。
次に、その ID 番号が Billing テーブルに挿入されます。
INSERT INTO Billing (Student_ID)
SELECT ID FROM Student WHERE Cumulative_Hours > 0
————————
次の例は、CURTIME()、CURDATE()、NOW() の各変数を使用して、現在の現地時刻、日付、タイムスタンプの値を INSERT ステートメントに挿入する方法を示します。
CREATE TABLE Timetbl (c1 TIME, c2 DATE, c3 TIMESTAMP)
INSERT INTO Timetbl(c1, c2, c3) VALUES(CURTIME(), CURDATE(), NOW())
————————
次の例は、INSERT および UPDATE ステートメントでのデフォルト値の基本的な使い方を示します。
CREATE TABLE t1 (c1 INT DEFAULT 10, c2 CHAR(10) DEFAULT 'abc')
INSERT INTO t1 DEFAULT VALUES
INSERT INTO t1 (c2) VALUES (DEFAULT)
INSERT INTO t1 VALUES (100, DEFAULT)
INSERT INTO t1 VALUES (DEFAULT, 'bcd')
INSERT INTO t1 VALUES (DEFAULT, DEFAULT)
SELECT * FROM t1
c1 c2
---------- ----------
10 abc
10 abc
100 abc
10 bcd
10 abc
UPDATE t1 SET c1 = DEFAULT WHERE c1 = 100
UPDATE t1 SET c2 = DEFAULT WHERE c2 = 'bcd'
UPDATE t1 SET c1 = DEFAULT, c2 = DEFAULT
SELECT * FROM t1
c1 c2
---------- ----------
10 abc
10 abc
10 abc
10 abc
10 abc
————————
直前に記した CREATE TABLE ステートメントを基にした場合、次の 2 つの INSERT ステートメントはまったく同じです。
INSERT INTO t1 (c1,c2) VALUES (20,DEFAULT)
INSERT INTO t1 (c1) VALUES (20)
————————
次の SQL コードは、複数の UPDATE 値での DEFAULT の使い方を示します。
CREATE TABLE t2 (c1 INT DEFAULT 10,
c2 INT DEFAULT 20 NOT NULL,
c3 INT DEFAULT 100 NOT NULL)
INSERT INTO t2 VALUES (1, 1, 1)
INSERT INTO t2 VALUES (2, 2, 2)
SELECT * FROM t2
c1 c2 c3
---------- ---------- ----------
1 1 1
2 2 2
UPDATE t2 SET c1 = DEFAULT, c2 = DEFAULT, c3 = DEFAULT
WHERE c2 = 2
SELECT * FROM t2
c1 c2 c3
---------- ---------- ----------
1 1 1
10 20 100
INSERT ON DUPLICATE KEY UPDATE の例
このトピックでは、INSERT ON DUPLICATE KEY UPDATE の例を示します。単純な INSERT については、INSERT の例を参照してください。
わかりやすくするために、以下のクエリ結果では、挿入された値を黒色で、更新された値を赤色で示しています。各例は前の例に基づいて進めているため、順番に実行していくと動作を確認できます。
————————
VALUES 句があり、列リストがない INSERT INTO。一意のインデックス セグメント列の値を使用できます。
CREATE TABLE t1 (
a INT NOT NULL DEFAULT 10,
b INT,
c INT NOT NULL,
d INT DEFAULT 20,
e INT NOT NULL DEFAULT 1,
f INT NOT NULL DEFAULT 2,
g INT,
h INT,
PRIMARY KEY(e, f) );
CREATE UNIQUE INDEX t1_ab ON t1 ( a, b, c, d );
INSERT INTO t1 VALUES ( 1, 2, 3, 4, 5, 6, 7, 8 )
ON DUPLICATE KEY UPDATE t1.a = 10, t1.b = 20, t1.c = 30, t1.d = 40;
SELECT * FROM t1;
a b c d e f g h
======== ======== ======== ======== ======== ======== ======== ========
1 2 3 4 5 6 7 8
————————
VALUES 句と完全な列リストがある INSERT INTO。行は更新されます。
INSERT INTO t1 ( a, b, c, d, e, f, g, h ) VALUES ( 1, 2, 3, 4, 5, 6, 7, 8 )
ON DUPLICATE KEY UPDATE t1.a = 10, t1.b = 20, t1.c = 30, t1.d = 40;
SELECT * FROM t1;
a b c d e f g h
======== ======== ======== ======== ======== ======== ======== ========
10 20 30 40 5 6 7 8
————————
VALUES 句と部分的な列リストがある INSERT INTO。新しい行が挿入され、その行が更新されます。
INSERT INTO t1 ( a, b, c, d ) VALUES ( 1, 2, 3, 4 )
ON DUPLICATE KEY UPDATE t1.a = 11, t1.b = 12, t1.c = 13, t1.d = 14;
SELECT * FROM t1;
a b c d e f g h
======== ======== ======== ======== ======== ======== ======== ========
10 20 30 40 5 6 7 8
1 2 3 4 1 2 (Null) (Null)
INSERT INTO t1 ( a, b, c ) VALUES ( -1, -2, -3 )
ON DUPLICATE KEY UPDATE t1.a = 11, t1.b = 12, t1.c = 13, t1.d = 14;
SELECT * FROM t1;
a b c d e f g h
======== ======== ======== ======== ======== ======== ======== ========
10 20 30 40 5 6 7 8
11 12 13 14 1 2 (Null) (Null)
————————
VALUES 句と DEFAULT がある INSERT INTO。行は、以前の状態に戻すように更新された後、重複キーに基づいて更新されます。
UPDATE t1 SET a = 1, b = 2, c = 3, d = 4, e = 11, f = 12 WHERE a = 11;
SELECT * FROM t1;
a b c d e f g h
======== ======== ======== ======== ======== ======== ======== ========
10 20 30 40 5 6 7 8
1 2 3 4 11 12 (Null) (Null)
INSERT INTO t1 ( a, b, c, d, e, f ) VALUES ( 1, 2, 3, 4, DEFAULT, DEFAULT )
ON DUPLICATE KEY UPDATE g = VALUES ( a ) + VALUES ( b ) + VALUES ( c ), h = VALUES ( e ) + VALUES ( f );
SELECT * FROM t1;
a b c d e f g h
======== ======== ======== ======== ======== ======== ======== ========
10 20 30 40 5 6 7 8
1 2 3 4 11 12 6 3
————————
UPDATE の SET 句でサブクエリ式を使用して、Demodata サンプル データベースの Person テーブルの値を基に更新します。
INSERT INTO t1 VALUES ( 1, 2, 3, 4, 5, 6, 7, 8 )
ON DUPLICATE KEY UPDATE t1.a = 10, t1.b = 20, t1.c = ( SELECT TOP 1 id FROM demodata.person ORDER BY id ), t1.d = ( SELECT TOP 1 id FROM demodata.person ORDER BY id DESC, last_name );
SELECT * FROM t1;
a b c d e f g h
======== ======== ======== ======== ======== ======== ======== ========
10 20 100062607 998332124 5 6 7 8
1 2 3 4 11 12 6 3
DEFAULT を使用した場合に発生するエラー
次の例は、列が NOT NULL として定義されており、デフォルト値が定義されていないことによって起こり得るエラー状況を示します。
CREATE TABLE t1 (c1 INT DEFAULT 10, c2 INT NOT NULL, c3 INT DEFAULT 100 NOT NULL)
INSERT INTO t1 DEFAULT VALUES -- エラー:列 <c2> にデフォルト値が割り当てられていません。
INSERT INTO t1 VALUES (DEFAULT, DEFAULT, 10) -- エラー:列 <c2> にデフォルト値が割り当てられていません。
INSERT INTO t1 (c1,c2,c3) VALUES (1, DEFAULT, DEFAULT) -- エラー:列 <c2> にデフォルト値が割り当てられていません。
INSERT INTO t1 (c1,c3) VALUES (1, 10) -- エラー:列 <c2> はヌル値を許可しません。
————————
次の例は、IDENTITY 列およびデフォルト値を持つ列に対し INSERT を使用したとき、どのようになるかを示します。
CREATE TABLE t (id IDENTITY, c1 INTEGER DEFAULT 100)
INSERT INTO t (id) VALUES (0)
INSERT INTO t VALUES (0,1)
INSERT INTO t VALUES (10,10)
INSERT INTO t VALUES (0,2)
INSERT INTO t (c1) VALUES (3)
SELECT * FROM t
SELECT によって、テーブルに次の行が含まれていることが示されます。
1、100
2、1
10、10
11、2
12、3
最初の行は、IDENTITY 列に対して VALUES 句で 0 を指定すると、テーブルが空の場合に挿入される値は 1 であることを示します。
またこの行は、デフォルト値を持つ列に対して VALUES 句で値を指定しないと、指定されているデフォルト値が挿入されることも示します。
2 行目は、IDENTITY 列に対して VALUES 句で 0 を指定すると、挿入される値は、IDENTITY 列中で最も大きな値より 1 大きい値になることを示します。
この行はまた、デフォルト値を持つ列に対して VALUES 句で値を指定すると、指定した値によりデフォルト値が上書きされることを示します。
3 行目は、IDENTITY 列に対して VALUES 句で 0 以外の値を指定すると、指定した値が挿入されることを示します。IDENTITY 列に対して指定された値を含む行が既に存在する場合は、"レコードのキー フィールドに重複するキー値があります(Btrieve エラー 5)" というメッセージが返され、INSERT は失敗します。
4 行目では再び、IDENTITY 列に対して VALUES 句で 0 を指定すると、IDENTITY 列中で最も大きな値より 1 大きい値が挿入されることが示されています。これは、値の間に「ギャップ」がある場合でも当てはまります(つまり、IDENTITY 列が最も大きな値よりも小さい値の行が 1 行以上欠落するということです)。
5 行目は、IDENTITY 列に対して VALUES 句で値を指定しないと、挿入される値は、IDENTITY 列中で最も大きな値より 1 大きい値になることを示します。
関連項目
JOIN
1 つのテーブルまたはビューを指定することも、複数のテーブルを指定することもできます。あるいは、1 つのビューと複数のテーブルを指定することもできます。複数のテーブルを指定する場合、テーブルを結合するといいます。
構文
結合定義 ::= テーブル参照 [ 結合タイプ ] JOIN テーブル参照 ON 検索条件
| テーブル参照 CROSS JOIN テーブル参照
| 外部結合定義
結合タイプ ::= INNER | LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
外部結合定義 ::= テーブル参照 外部結合タイプ JOIN テーブル参照
ON 検索条件
外部結合タイプ ::= LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
次の例は、2 つのテーブルの外部結合を示しています。
SELECT * FROM Person LEFT OUTER JOIN Faculty ON Person.ID = Faculty.ID
次の例は、ベンダー文字列に埋め込まれた外部結合を示しています。文字 "OJ" は大文字と小文字のどちらでもかまいません。
SELECT t1.deptno, ename FROM {OJ emp t2 LEFT OUTER JOIN dept t1 ON t2.deptno=t1.deptno}
Zen は、Microsoft の ODBC ドキュメントに明記されている 2 つのテーブルの外部結合をサポートしています。単純な 2 つのテーブルの外部結合のほかにも、Zen では n とおりのネストされた外部結合がサポートされています。
外部結合は、ベンダー文字列に埋め込んでも埋め込まなくてもかまいません。ベンダー文字列が使用された場合、Zen ではそれをストリップし、実際の外部結合テキストを解析します。
LEFT OUTER
Zen データベースは、SQL92(SQL2)をモデルとする LEFT OUTER JOIN を使用しています。構文は、クロス結合、右外部結合、完全外部結合、および内部結合が組み込まれた全 SQL92 構文のサブセットです。以下の TableRefList は、SELECT ステートメント内の FROM キーワードと、後続の WHERE、HAVING、およびその他の句の間に置かれます。TableRef と LeftOuterJoin の再帰的な性質に注意してください。TableRef が TableRef を含む左外部結合で、その TableRef も左外部結合で、というように続けることができます。
TableRefList :
TableRef [, TableRefList]
| TableRef
| OuterJoinVendorString [, TableRefList]
TableRef :
TableName [CorrelationName]
| LeftOuterJoin
| (LeftOuterJoin )
LeftOuterJoin :
TableRef LEFT OUTER JOIN TableRef ON SearchCond
検索条件(SearchCond)には結合条件が含まれます。この条件の通常の形式は、LT.ColumnName = RT.ColumnName のようになります。ここで、LT は左テーブル、RT は右テーブル、ColumnName は指定されたドメイン内の列を表します。検索条件内の各述部には、非リテラル式が含まれている必要があります。
左外部結合の実装は、Microsoft の ODBC ドキュメントに示されている構文の範囲を超えています。
ベンダー文字列
前のセクションの構文は、Microsoft ODBC ドキュメントに記載されていますが、詳しい説明は含まれていません。さらに、左外部結合の最初と最後のベンダー文字列エスケープ シーケンスによって外部結合のコア構文は変わりません。
Zen データベースでは、ベンダー文字列を含まない外部結合構文を受け入れます。ただし、複数データベースにわたる ODBC 準拠を必要とするアプリケーションでは、ベンダーの文字列構成を使用する必要があります。ODBC のベンダー文字列外部結合では 3 つ以上のテーブルはサポートされないため、例に記載されている構文を使用しなければならない場合があります。
例
以下の例では、次の 4 つのテーブルを使用します。
Emp テーブル
FirstName | LastName | DeptID | EmpID |
|---|---|---|---|
Franky | Avalon | D103 | E1 |
Gordon | Lightfoot | D102 | E2 |
Lawrence | Welk | D101 | E3 |
Bruce | Cockburn | D102 | E4 |
Dept テーブル
DeptID | LocID | Name |
|---|---|---|
D101 | L1 | TV |
D102 | L2 | Folk |
Addr テーブル
EmpID | Street |
|---|---|
E1 | 101 Mem Lane |
E2 | 14 Young St. |
Loc テーブル
LocID | Name |
|---|---|
L1 | PlanetX |
L2 | PlanetY |
以下の例は、単純な 2 方向左外部結合を示しています。
SELECT * FROM Emp LEFT OUTER JOIN Dept ON Emp.DeptID = Dept.DeptID
この単純な 2 方向外部結合では、次の結果セットが作成されます。
Emp | Dept | |||||
|---|---|---|---|---|---|---|
FirstName | LastName | DeptID | EmpID | DeptID | LocID | Name |
Franky | Avalon | D103 | E1 | NULL | NULL | NULL |
Gordon | Lightfoot | D102 | E2 | D102 | L2 | Folk |
Lawrence | Welk | D101 | E3 | D101 | L1 | TV |
Bruce | Cockburn | D102 | E4 | D102 | L2 | Folk |
テーブル内の Franky Avalon の NULL エントリに注目してください。これは、D103 の DeptID が Dept テーブル内に見つからなかったためです。標準(INNER)結合では、Franky Avalon はまとめて結合セットから削除されてしまうでしょう。
アルゴリズム
前の例で Zen データベース エンジンが使用しているアルゴリズムは、次のようになります。左テーブルを取り出して、右テーブルを走査します。現行の右テーブル行で ON 条件が TRUE になる場合ごとに、現行の左テーブル行に追加される適合した右テーブル行から成る結果セット行を返します。
ON 条件が TRUE の右テーブル行がない(現行の左テーブル行に対し、すべての右テーブル行で ON 条件が FALSE になる)場合は、すべての列の値を NULL にして右テーブルの行インスタンスを作成します。
その結果セットは、行ごとに現行の左テーブル行と結合され、返される結果セット内でインデックス付けされます。左テーブル行ごとにこのアルゴリズムが繰り返されて、完全な結果セットが構築されます。前述の単純な 2 方向左外部結合では、Emp が左テーブルで Dept が右テーブルです。
メモ: アルゴリズムとは関係ありませんが、左テーブルを右テーブルに追加する場合、クエリの選択リスト内に指定されたように適切に射影が行われることが前提となります。この射影の範囲は、すべての列(たとえば、SELECT * FROM ...)から、結果セット内の 1 つの列(たとえば、SELECT FirstName FROM...)です。
————————
放射状左外部結合では、1 つの中央テーブルにほかのすべてのテーブルが結合されます。以下の 3 方向の放射状左外部結合の例では、Emp が中央テーブルで、すべての結合はそのテーブルから射影したものです。
SELECT * FROM (Emp LEFT OUTER JOIN Dept ON Emp.DeptID = Dept.DeptID) LEFT OUTER JOIN Addr ON Emp.EmpID = Addr.EmpID
Emp | Dept | Addr | ||||||
|---|---|---|---|---|---|---|---|---|
First Name | Last Name | Dept ID | Emp ID | Dept ID | Loc ID | Name | Emp ID | Street |
Franky | Avalon | D103 | E1 | NULL | NULL | NULL | E1 | 101 Mem Lane |
Gordon | Lightfoot | D102 | E2 | D102 | L2 | Folk | E2 | 14 Young St |
Lawrence | Welk | D101 | E3 | D101 | L1 | TV | NULL | NULL |
Bruce | Cockburn | D102 | E4 | D101 | L1 | TV | NULL | NULL |
————————
チェーン状の左外部結合では、1 つのテーブルが別のテーブルに結合され、そのテーブルがまた別のテーブルに結合されます。次の例は、3 方向のチェーン状左外部結合を示しています。
SELECT * FROM (Emp LEFT OUTER JOIN Dept ON Emp.DeptID = Dept.DeptID) LEFT OUTER JOIN Loc ON Dept.LocID = Loc.LocID
Emp | Dept | Loc | ||||||
|---|---|---|---|---|---|---|---|---|
First Name | Last Name | Dept ID | Emp ID | Dept ID | Loc ID | Name | Loc ID | Name |
Franky | Avalon | D103 | E1 | NULL | NULL | NULL | NULL | NULL |
Gordon | Lightfoot | D102 | E2 | D102 | L2 | Folk | L2 | PlanetY |
Lawrence | Welk | D101 | E3 | D101 | L1 | TV | L1 | PlanetX |
Bruce | Cockburn | D102 | E4 | D101 | L1 | TV | L1 | PlanetX |
この結合は、次のように表すこともできます。
SELECT * FROM Emp LEFT OUTER JOIN (Dept LEFT OUTER JOIN Loc ON Dept.LocID = Loc.LocID) ON Emp.DeptID = Dept.DeptID
最初の構文は放射状結合とチェーン状結合の両方に使用できるため、最初の構文をお勧めします。ネストされた左外部結合 ON 条件はネスト外部のテーブル内の列を参照できないため、この 2 番目の構文は放射状結合には使用できません。つまり、次のクエリでは Emp.EmpID への参照は不正です。
SELECT * FROM Emp LEFT OUTER JOIN (Dept LEFT OUTER JOIN Addr ON Emp.EmpID = Addr.EmpID) ON Emp.DeptID = Dept.DeptID
————————
次の例は、最適化が足りない 3 方向の放射状左外部結合を示しています。
SELECT * FROM Emp E1 LEFT OUTER JOIN Dept ON E1.DeptID = Dept.DeptID, Emp E2 LEFT OUTER JOIN Addr ON E2.EmpID = Addr.EmpID WHERE E1.EmpID = E2.EmpID
Emp | Dept | Addr | ||||||
|---|---|---|---|---|---|---|---|---|
First Name | Last Name | Dept ID | Emp ID | Dept ID | Loc ID | Name | Emp ID | Street |
Franky | Avalon | D103 | E1 | NULL | NULL | NULL | E1 | 101 Mem Lane |
Gordon | Lightfoot | D102 | E2 | D102 | L2 | Folk | E2 | 14 Young St |
Lawrence | Welk | D101 | E3 | D101 | L1 | TV | NULL | NULL |
Bruce | Cockburn | D102 | E4 | D101 | L1 | TV | NULL | NULL |
Emp 内の EmpID に NULL 値がなく、EmpID が重複値のない列である場合、このクエリでは、Loc テーブルの結果と同じ結果が返されます。ただし、このクエリは Loc テーブルで示される結果ほど最適化されておらず、はるかに遅くなる可能性があります。
関連項目
LAG
LAG は、ウィンドウ関数としてのみ使用できるセット関数です。LAG は、結果セットの現在のパーティションにある前の行から値を取得する場合に使用されます。GROUP BY 集計としては使用できません。
構文
LAG ( 式[ , lagオフセット式[ , lagデフォルト式 ] ] over句 )
各項目の説明は次のとおりです。
• 式は、結果セット内の行の列または式です。
• lagオフセット式は、結果セット内の現在の行から何行前にある行の値を表示するかを示す整数式です。
• lagデフォルト式は、現在のパーティション内の lagオフセット式の行がまだ結果セットに累積されていない場合に返すための値です。
例
以下に示す LAG の例を実行するために、まず次の手順を実行してください。
1. ZenCC の Zen エクスプローラーで[データベース]を右クリックし、次に[新規作成]>[データベース]を選択して一時データベースを作成します。この場合は SAMPLEDB という名前にします。
2. SAMPLEDB を右クリックして[SQL ドキュメント]を選択します。
3. SQL Editor で次の SQL スクリプトを実行して、SAMPLEDB に checkout0 というテーブルを作成します。
create table checkout0 (StartTime TIMESTAMP, LaneNo INTEGER, Items INTEGER, Total MONEY(6,2), Duration INTEGER);
insert into checkout0 values('2021-01-07 22:20:37.852', 1, 7, 18.72, 87);
insert into checkout0 values('2021-01-07 22:22:47.852', 1, 9, 23.45, 107);
insert into checkout0 values('2021-01-07 22:24:57.852', 1, 17, 68.22, 183);
insert into checkout0 values('2021-01-07 22:31:07.852', 1, 12, 48.17, 99);
insert into checkout0 values('2021-01-07 22:33:27.852', 1, 11, 37.77, 77);
insert into checkout0 values('2021-01-07 22:34:39.852', 1, 7, 23.32, 94);
insert into checkout0 values('2021-01-07 22:36:41.852', 1, 14, 56.61, 112);
insert into checkout0 values('2021-01-07 22:19:37.852', 2, 6, 16.72, 80);
insert into checkout0 values('2021-01-07 22:23:47.852', 2, 10, 25.45, 117);
insert into checkout0 values('2021-01-07 22:26:57.852', 2, 18, 72.22, 196);
insert into checkout0 values('2021-01-07 22:31:07.852', 2, 11, 58.17, 109);
insert into checkout0 values('2021-01-07 22:33:47.852', 2, 14, 47.77, 87);
insert into checkout0 values('2021-01-07 22:35:49.852', 2, 9, 27.32, 84);
insert into checkout0 values('2021-01-07 22:37:41.852', 2, 15, 46.16, 122);
insert into checkout0 values('2021-01-07 22:20:07.852', 3, 8, 18.82, 64);
insert into checkout0 values('2021-01-07 22:24:17.852', 3, 8, 19.54, 74);
insert into checkout0 values('2021-01-07 22:27:37.852', 3, 16, 62.44, 131);
insert into checkout0 values('2021-01-07 22:31:37.852', 3, 13, 51.87, 119);
insert into checkout0 values('2021-01-07 22:34:17.852', 3, 12, 37.65, 89);
insert into checkout0 values('2021-01-07 22:36:19.852', 3, 11, 28.23, 86);
insert into checkout0 values('2021-01-07 22:38:11.852', 3, 18, 65.26, 128);
4. これで、レジ精算システムのデータを使用する以下の例を実行する準備ができました。
すべてのウィンドウ関数と同様、結果のデフォルトの順序は、OVER 句で指定されている <partition 列>、<order 列> になります。この順序は、外部 ORDER BY を使用することによって変更できます。
次のクエリは、各 LaneNo が 7 行あることを示します。COUNT(*) を使用して、各行に 1 から 7 の番号を付けることができます。
SELECT LaneNo, StartTime, RowNumInPart FROM (select LaneNo, StartTime, COUNT(*) OVER (PARTITION BY LaneNo ORDER BY StartTime) FROM checkout0) AS T(LaneNo, StartTime, RowNumInPart);
————————
次のクエリでは、LAG 関数を使用して、現在の行から 3 行前にある行の、RowNumInPart 列で示される値を取得する方法を示します。各パーティションが少なくとも 3 行になるまでは 0 が返されることに注目してください。
SELECT LaneNo, StartTime, RowNumInPart, LAG(RowNumInPart, 3, 0) OVER (PARTITION BY LaneNo ORDER BY StartTime) FROM (select LaneNo, StartTime, COUNT(*) OVER (PARTITION BY LaneNo ORDER BY StartTime) FROM checkout0) AS T(LaneNo, StartTime, RowNumInPart);
————————
次のクエリは、LAG のデフォルトのオフセットである 1 行を使用して、各パーティション内の連続した 2 つの行ごとの時間差(秒単位)を表示します。
SELECT LaneNo, StartTime, DATEDIFF (SECOND, LAG(StartTime) OVER (PARTITION BY LaneNo ORDER BY StartTime), StartTime) AS Diff_in_secs FROM checkout0;
————————
次のクエリは、レーン 1 の精算を前の精算と比較することで、精算ごとの品目数の変化を経時的に表示する方法を示します。
SELECT StartTime, LaneNo, Items, Items-LAG(Items) OVER (PARTITION BY LaneNo ORDER BY StartTime) AS delta_items FROM checkout0 WHERE LaneNo = 1;
LEAVE
備考
LEAVE ステートメントにより、ブロックまたはループ ステートメントを抜けて実行を継続します。LEAVE ステートメントは、ストアド プロシージャまたはトリガーの本体で使用できます。
例
次の例では、変数 vInteger の値が 1 ずつ増え、値が 11 になると、ループが LEAVE ステートメントで終了します。
TestLoop:
LOOP
IF (:vInteger > 10) THEN
LEAVE TestLoop;
END IF;
SET :vInteger = :vInteger + 1;
END LOOP;
関連項目
LIKE、ILIKE と ESCAPE の使用
LIKE および ILIKE はどちらも、文字ベースの列データ内でのパターン検索を可能にします。LIKE は大文字と小文字を区別するのに対し、ILIKE は大文字と小文字を区別しないという点が異なります。どちらも、ESCAPE 句を使用してエスケープ文字を指定できます。
構文
WHERE 式 [ NOT ] < LIKE | ILIKE > [ N ] 値 | ? [ エスケープ句 ]
エスケープ句 := ESCAPE [ N ] エスケープ文字
エスケープ文字 := '文字' | '' | ?
備考
LIKE 演算子または ILIKE 演算子の右辺のパターン値は、次のいずれかを指定する必要があります。
• 一致させる単純な文字列定数。
• 実行時に提供される動的パラメーター。これは、一致させる文字列を疑問符で示します。パラメーターはストアド プロシージャ内に配置できません。SQL Editor は動的パラメーターをサポートしていませんが、アプリケーション コードはサポートしています。
• USER キーワード。
パターン値では、パーセント記号ワイルドカードを使用して、列値内の 0 個以上の文字と一致させることができます。1 文字と一致させるには、アンダースコア ワイルドカードを使用します。どちらのワイルドカードも、パターン内で複数回使用できます。
次の表に、ワイルドカードやその他の特殊文字の使用に関する詳細を示します。
文字 | 用途 |
|---|---|
パーセント記号 "%" | 0 個以上の文字と一致するワイルドカード。たとえば、Dan% は Dan、Daniel、Danny と一致します。 |
アンダースコア "_" | 1 つの文字と一致するワイルドカード。 |
円記号 "\" | デフォルトのエスケープ文字。ワイルドカード文字または別のエスケープ文字が続く場合、その文字を文字自体と一致するリテラルとして扱います。たとえば、列値内の "%" と一致させるには、パーセント記号の前に円記号を使用します("\%")。ただし、値パターン内のエスケープ文字の後にワイルドカード文字または別のエスケープ文字以外の文字が続く場合、エスケープ文字の効果はありません。 |
2 つの一重引用符 "''" | 間にスペースを入れない 2 つの一重引用符には、次の 2 つの用途があります。 • 結果文字列内の一重引用符を照合します。たとえば、データベースの列に Jim's house という値が含まれている場合、WHERE 句で LIKE 'Jim''s house' を指定すると、このパターンと一致させることができます。 • ESCAPE キーワードの後に使用してヌル値を指定します。これにより、円記号がエスケープ文字として無効になり、他の文字と同じようにパターン値で使用できるようになります。 メモ: 二重引用符はパターン文字列内では特殊文字でないため、すべての文字や数字と同様に使用できます。 |
ESCAPE 文字は次のいずれかになります。
• 単一文字。データベースで使用される任意のコード ページから指定できます。
• 2 つの一重引用符 ''。ヌル エスケープ文字を指定します。
• 疑問符。アプリケーション コードによって提供される動的パラメーターを示します。
Unicode での ESCAPE
パターン値とエスケープ文字の前にオプションの N プレフィックスがある場合は、N で始まるデータ型(NCHAR、NLONGVARCHAR、NVARCHAR など)に Unicode 文字を使用することを示します。N プレフィックスがない場合、ESCAPE を指定した LIKE および ILIKE でパターン値を Unicode 列と比較すると、結果が不完全または不正確になる可能性があります。
LIKE の例
このトピックでは LIKE の使用方法を説明します。ILIKE との比較のために、ILIKE の例を参照してください。
次の例は、長さ 5 文字、かつ中間の 3 文字が abc であるすべての列値と一致します。
SELECT Building_Name FROM Room WHERE Building_Name LIKE '_abc_'
————————
次の例は、円記号を含むすべての列値と一致します。
SELECT Building_Name FROM Room where Building_Name LIKE '%\\%'
————————
次の例は、パーセント記号で始まる列値以外のすべての列値と一致します。
SELECT Building_Name FROM Room where Building_Name NOT LIKE '\%%'
————————
次の例は、1 つ以上の一重引用符を含むすべての列値と一致します。
SELECT Building_Name FROM Room where Building_Name LIKE '%''%'
————————
次の例は、2 番目の文字が二重引用符であるすべての列値と一致します。
SELECT Building_Name FROM Room WHERE Building_Name LIKE '_"%'
————————
次の例では、Building_Name 列が入力変数 :rname に格納された文字列を含み、Type 列が入力変数 :rtype に格納された文字列を含む行を返す、ストアド プロシージャが作成されます。
CREATE PROCEDURE room_test(IN :rname CHAR(20), IN :rtype CHAR(20))
RETURNS(Building_Name CHAR(25), "Type" CHAR(20));
BEGIN
DECLARE :like1 CHAR(25);
DECLARE :like2 CHAR(25);
SET :like1 = '%' + :rname + '%';
SET :like2 = '%' + :rtype + '%';
SELECT Building_Name, "Type" FROM Room WHERE Building_Name LIKE :like1 AND "Type" LIKE :like2;
END;
次のステートメントを上記のストアド プロシージャ内に記述した場合、LIKE 演算子の右辺の式が単純な定数でないことが原因で、構文エラーが発生します。
次の構文は正しくないため、失敗します。
SELECT Building_Name, "Type" from Room WHERE Building_Name LIKE '%' + :rname + '%';
ILIKE の例
次の 2 つの LIKE と ILIKE の例は、Demodata サンプル データベースから同じ結果を返します。ILIKE ステートメントでは、UPPER 文字列関数を使用する必要はありません。
SELECT First_Name, Last_Name, Email_Address from Person
WHERE UPPER(Email_Address) LIKE '%@BTU.EDU%';
WHERE UPPER(Email_Address) LIKE '%@BTU.EDU%';
SELECT First_Name, Last_Name, Email_Address from Person
WHERE Email_Address ILIKE '%@btu.edu%';
WHERE Email_Address ILIKE '%@btu.edu%';
メモ: 最適化のために、ILIKE は大文字と小文字を区別する列に作成されたインデックスを使用できません。
ESCAPE を使用した LIKE または ILIKE の例
次の ESCAPE を使用した LIKE の例では、列値のパス名内の円記号をエスケープするためにエスケープ文字として感嘆符 "!" を指定し、円記号がデフォルトのエスケープ文字として扱われないようにしています。
CREATE TABLE backup_log (path VARCHAR(50), backup_file VARCHAR(50) );
INSERT INTO backup_log VALUES ('C:\Data\', 'Backup240420');
INSERT INTO backup_log VALUES ('D:\Data\', 'Backup240421');
SELECT path + backup_file as C_Files FROM backup_log WHERE path LIKE 'C:!\%' ESCAPE '!';
結果:
C_Files
====================
C:\Data\Backup240420
関連項目
LOOP
備考
LOOP ステートメントは、ステートメント ブロックの実行を繰り返します。
これはストアド プロシージャとトリガーでのみ使用できます。
Zen では、事後条件ループ REPEAT ... UNTIL はサポートされていません。
例
次の例では、変数 vInteger の値が 1 ずつ増え、値が 11 になるとループが終了します。
TestLoop:
LOOP
IF (:vInteger > 10) THEN
LEAVE TestLoop;
END IF;
SET :vInteger = :vInteger + 1;
END LOOP;
関連項目
NOT
備考
NOT キーワードと EXISTS キーワードを一緒に使用すると、サブクエリの結果に行が存在しないことを検査できます。外部クエリが評価するすべての行について、Zen はサブクエリ内に関連する行が存在するかどうかを検査します。Zen は、外部クエリの結果のうち、サブクエリ内の関連する行に対応する各行を、ステートメントの結果テーブルから除外します。
NOT と IN 演算子を組み合わせることにより、外部クエリの結果が、サブクエリの結果に含まれないかどうかを検査できます。結果テーブルには、外部クエリが返す行で、サブクエリ内に関連する行が存在しないものだけが含まれます。
例
次のステートメントは、どの講座にも登録されていない学生のリストを返します。
SELECT * FROM Person p WHERE NOT EXISTS
(SELECT * FROM Student s WHERE s.id = p.id
AND Cumulative_Hours = 0)
IN を使って、このステートメントを書き直すことができます。
SELECT * FROM Person p WHERE p.id NOT IN
(SELECT s.id FROM Student s WHERE Cumulative_Hours = 0)
関連項目
OPEN
構文
OPEN カーソル名
カーソル名 ::= ユーザー定義名
備考
OPEN ステートメントにより、カーソルが開きます。カーソルを開くには、事前にカーソルが定義されていなければなりません。
カーソルと変数はストアド プロシージャとトリガー内部でのみ許可されるため、このステートメントはストアド プロシージャまたはトリガーの内部でのみ使用できます。
例
次の例では、宣言されたカーソル BTUCursor が開きます。
DECLARE BTUCursor CURSOR
FOR SELECT Degree, Residency, Cost_Per_Credit FROM Tuition ORDER BY ID;
OPEN BTUCursor;
————————
CREATE PROCEDURE MyProc(IN :CourseName CHAR(7)) AS
BEGIN
DECLARE cursor1 CURSOR
FOR SELECT Degree, Residency, Cost_Per_Credit FROM Tuition ORDER BY ID;
(追加コードはここに記述します)
OPEN cursor1;
FETCH cursor1 INTO :CourseName;
(追加コードはここに記述します)
CLOSE cursor1;
(追加コードはここに記述します)
END
関連項目
PARTIAL
備考
255 バイトを超える CHAR 列および VARCHAR 列でのインデックス作成を可能にするには、CREATE INDEX ステートメントに PARTIAL キーワードを記述します。部分インデックスを構成する列に格納されるバイト数が、オーバーヘッドも含めて 255 バイトより少なければ、PARTIAL は無視されます。
メモ: DROP INDEX ステートメントでは、部分インデックスを削除する場合に PARTIAL を必要としません。
UNIQUE と PARTIAL は相互に排他的であるため、1 つの CREATE INDEX 内で使用することはできません。
関連項目
PRIMARY KEY
備考
テーブル定義に主キーを追加するには、ADD 句で PRIMARY KEY を使用します。主キーは、ヌル値を含まない、重複のないインデックスです。主キーを指定すると、Zen によって、定義された列のグループに対して、指定された属性で重複のないインデックスが作成されます。
テーブルに複数の主キーがあってはならないので、既に主キーが定義されているテーブルに主キーを追加することはできません。テーブルの主キーを変更するには、ALTER TABLE ステートメントで DROP 句を使用して既存のキーを削除し、新しい主キーを追加します。
メモ: 主キーを追加したり、その他の参照整合性(RI)操作を行ったりするには、その前にデータベース名を使用してデータベースにログインする必要があります。
テーブル定義に主キーを追加するには、ALTER TABLE ステートメントの ADD 句に PRIMARY KEY を含めます。
主キーを追加する前に、主キー列リスト内の列が NOT NULL として定義されていることを確認する必要があります。主キーは重複のないインデックスであるため、ヌル値を許可しない列でのみ作成することができます。
ヌル値を許可しない列に基づく重複のないインデックスが既に存在する場合、ADD PRIMARY KEY によって別の重複のないインデックスは作成されません。代わりに、既存の重複のないインデックスが主キーになります。たとえば、次のステートメントでは、T1_C1C2 という名前付きインデックスが主キーになります。
CREATE TABLE t1 (c1 INT NOT NULL, c2 CHAR(10) NOT NULL)
CREATE UNIQUE INDEX t1_c1c2 ON t1(c1,c2)
ALTER TABLE t1 ADD PRIMARY KEY(c1, c2)
このような主キーを削除した場合、その主キーは重複のないインデックスに切り替わります。
ALTER TABLE t1 DROP PRIMARY KEY
ヌル値を許可しない列に基づく重複のないインデックスがテーブル内に存在しない場合は、ADD PRIMARY KEY によって、ヌル値を許可しない列に基づいて重複のないインデックスが作成されます。DROP PRIMARY KEY によって、重複のないインデックスは完全に削除されます。
テーブル定義に主キーを追加するには、CREATE TABLE ステートメントに PRIMARY KEY 句を含めます。
データベースに参照制約を定義するには、PRIMARY KEY 句を使用して親テーブルの主キーを指定する必要があります。主キーは、1 つまたは複数の列で構成することができますが、ヌルではない列に対してのみ定義できます。指定する列は、CREATE TABLE ステートメントの列定義リストに含まれている必要もあります。
主キーを指定すると、Zen によって、定義された列のグループに対して、指定された属性でインデックスが作成されます。CREATE TABLE ステートメント内で、列が NOT NULL として明確に定義されていない場合、Zen はその列を強制的にヌル値を許可しない列にします。また、Zen はその列に基づいて重複のないインデックスを作成します。
たとえば、次の 2 つのステートメントは同じ結果になります。
CREATE TABLE t1 (c1 INT, c2 CHAR(10), PRIMARY KEY(c1,c2))
CREATE TABLE t1 (c1 INT NOT NULL, c2 CHAR(10) NOT NULL, PRIMARY KEY(c1,c2))
例
次のステートメントは、Faculty というテーブルに主キーを定義します。
ALTER TABLE Faculty ADD PRIMARY KEY (ID)
ID 列は、ヌル値を含まない重複のないインデックスとして定義されています。
関連項目
PRINT
備考
PRINT を使用して、変数の値または定数を印刷します。PRINT ステートメントは Windows ベースのプラットフォームにのみ適用されます。ほかのオペレーティング システムのプラットフォームでは無視されます。
PRINT はストアド プロシージャ内でのみ使用できます。
例
次の例では、変数 :myvar の値が印刷されます。
PRINT( :myvar );
PRINT 'MYVAR = ' + :myvar;
————————
次の例では、テキスト文字列の後に数値が印刷されます。数値はテキスト文字列に変換して印刷しなければなりません。
PRINT 'History 101 に登録されている生徒数: ' + convert(:int_val, SQL_CHAR);
————————
Windows Vista のリリース前は、[デスクトップとの対話をサービスに許可]を設定したローカル システム アカウントを使用して Zen がサービスとして実行されている場合には、ストアド プロシージャ内で PRINT を使用してダイアログ ボックスに出力を送ることができました。Windows Vista リリース以降、オペレーティング システムはこの出力を許可しなくなりました。次の回避策に示すように、値を文字列に変換して、SELECT ステートメントでそれを返すことができます。
DROP PROCEDURE varsub2;
CREATE PROCEDURE varsub2 ()
RETURNS (TestString CHAR(25));
DECLARE :vInteger INT;
DECLARE :tstring CHAR(25);
SET :vInteger = 0;
BEGIN
WHILE (:vInteger < 10) DO
SET :vInteger = :vInteger + 1;
END WHILE;
SET :tstring = 'The counter value is = ' + convert(:vInteger, SQL_CHAR);
SELECT :tstring;
END;
Call varsub2;
関連項目
PUBLIC
備考
PUBLIC キーワードを FROM に記述すると、Create Table 権が明示的に割り当てられていない全ユーザーからこの権限を取り消すことができます。
FROM 句には、アクセス権を取り消すグループまたはユーザーを指定します。単一の名前または名前のリストを指定することもできますが、PUBLIC キーワードを記述すれば、権限が明示的に割り当てられていない全ユーザーのアクセス権を取り消すことができます。
例
辞書内の全ユーザーにアクセス権を割り当てるには、次の例のように PUBLIC キーワードを使用して PUBLIC グループにアクセス権を付与します。
GRANT SELECT ON Course TO PUBLIC
このステートメントは、辞書内で定義されている全ユーザーに、Course テーブルの Select 権を割り当てます。後で PUBLIC グループの Select 権を取り消した場合、Select 権が明示的に付与されたユーザーだけがテーブルにアクセスできます。
次のステートメントでは、PUBLIC キーワードを使用して、辞書内で定義されている全ユーザーに Create Table 権を付与します。
GRANT CREATETAB TO PUBLIC
関連項目
RELEASE SAVEPOINT
RELEASE SAVEPOINT ステートメントを使用して、セーブポイントを削除します。
構文
RELEASE SAVEPOINT セーブポイント名
セーブポイント名 ::= ユーザー定義名
備考
AUTOCOMMIT がオフの場合、RELEASE、ROLLBACK、および SAVEPOINT はセッション レベル(ストアド プロシージャの外部)でのみサポートされます。そうでない場合、RELEASE、ROLLBACK、および SAVEPOINT はストアド プロシージャ内で使用しなければなりません。
ストアド プロシージャ内でコミットされたステートメントは、呼び出し元の SQL アプリケーションの一番外側のトランザクションによって制御されます。
例
次の例では、SAVEPOINT を設定し、その後で条件を調べて SAVEPOINT を ROLLBACK するか RELEASE するかが判断されます。
CREATE PROCEDURE Enroll_student( IN :student ubigint, IN :classnum INTEGER);
BEGIN
DECLARE :CurrentEnrollment INTEGER;
DECLARE :MaxEnrollment INTEGER;
SAVEPOINT SP1;
INSERT INTO Enrolls VALUES (:student, :classnum, 0.0);
SELECT COUNT(*) INTO :CurrentEnrollment FROM Enrolls WHERE class_id = :classnum;
SELECT Max_size INTO :MaxEnrollment FROM Class WHERE ID = :classnum;
IF :CurrentEnrollment >= :MaxEnrollment THEN
ROLLBACK TO SAVEPOINT SP1;
ELSE
RELEASE SAVEPOINT SP1;
END IF;
END;
COUNT(式) によって、述部にある式の非ヌル値がすべてカウントされるということを覚えておいてください。COUNT(*) ではヌル値を含むすべての値がカウントされます。
関連項目
RESTRICT
備考
RESTRICT を指定した場合、Zen は DELETE RESTRICT 規則を使用します。外部キー値が親テーブルの行を参照している場合、ユーザーはその行を削除できません。
削除規則を指定しない場合、Zen はデフォルトで RESTRICT 規則を適用します。
関連項目
REVOKE
REVOKE ステートメントにより、ユーザー ID を削除し、セキュリティで保護されているデータベースにおける特定のユーザーの権限を取り消します。REVOKE ステートメントを使って、CREATE TABLE、CREATE VIEW、および CREATE PROCEDURE の権限を取り消すことができます。
構文
REVOKE CREATETAB | CREATEVIEW | CREATESP FROM public またはユーザー/グループ名 [ , public またはユーザー/グループ名 ]...
REVOKE LOGIN FROM ユーザー名 [ , ユーザー名 ]...
REVOKE 権限 ON < * | [ TABLE ] テーブル名 [ オーナー ネーム ] | VIEW ビュー名 | PROCEDURE ストアド プロシージャ名 > FROM ユーザー/グループ名 [ , ユーザー/グループ名 ]...
* ::= すべてのオブジェクト(つまり、すべてのテーブル、ビュー、およびストアド プロシージャ)
権限 ::= ALL
| SELECT [ ( 列名 [ , 列名 ]... ) ]
| UPDATE [ ( 列名 [ , 列名 ]... ) ]
| INSERT [ ( 列名 [ , 列名 ]... ) ]
| DELETE
| ALTER
| REFERENCES
| EXECUTE
テーブル名 ::= ユーザー定義のテーブル名
ビュー名 ::= ユーザー定義のビュー名
ストアド プロシージャ名 ::= ユーザー定義のストアド プロシージャ名
public またはユーザー/グループ名 ::= PUBLIC | ユーザー/グループ名
ユーザー/グループ名 ::= ユーザー名 | グループ名
ユーザー名 ::= ユーザー定義のユーザー名
グループ名 ::= ユーザー定義のグループ名
次の表は、特定の操作に対する構文を示しています。
この操作の権限を取り消す場合 | REVOKE で使用するキーワード |
|---|---|
CREATE TABLE | CREATETAB |
CREATE VIEW | CREATEVIEW |
CREATE PROCEDURE | CREATESP |
次の表は、ALL キーワードを使用した場合に取り消される権限を示しています。
ALL によって取り消される権限 | テーブル | ビュー | ストアド プロシージャ |
|---|---|---|---|
ALTER | X | X | X |
DELETE | X | X | |
INSERT | X | X | |
REFERENCES | X | ||
SELECT | X | X | |
UPDATE | X | X | |
EXECUTE | X |
例
次のステートメントによって、dannyd からテーブル Class のすべての権限が取り消されます。
REVOKE ALL ON Class FROM 'dannyd'
次のステートメントでは、dannyd と rgarcia からテーブル Class のすべての権限が取り消されます。
REVOKE ALL ON Class FROM dannyd, rgarcia
————————
次のステートメントによって、dannyd と rgarcia からテーブル Class の DELETE 権限が取り消されます。
REVOKE DELETE ON Class FROM dannyd, rgarcia
————————
次の例では、keithv と miked からテーブル Class の INSERT 権限が取り消されます。
REVOKE INSERT ON Class FROM keithv, miked
次の例では、keithv と brendanb から、テーブル Person の列 First_name と Last_name の INSERT 権限が取り消されます。
REVOKE INSERT(First_name,Last_name) ON Person FROM keithv, brendanb
————————
次のステートメントによって、dannyd からテーブル Class の ALTER 権限が取り消されます。
REVOKE ALTER ON Class FROM dannyd
————————
次の例では、dannyd と rgarcia からテーブル Class の SELECT 権限が取り消されます。
REVOKE SELECT ON Class FROM dannyd, rgarcia
次のステートメントによって、dannyd と rgarcia から、テーブル Person の列 First_name と Last_name の SELECT 権限が取り消されます。
REVOKE SELECT(First_name, Last_name) ON Person FROM dannyd, rgarcia
————————
次の例では、dannyd と rgarcia からテーブル Person の UPDATE 権限が取り消されます。
REVOKE UPDATE ON Person ON dannyd, rgarcia
————————
次の例では、user1 から CREATE VIEW 権限が取り消されます。
REVOKE CREATEVIEW FROM user1;
————————
次の例では、ストアド プロシージャ MyProc1 に対する user1 の EXECUTE 権限が取り消されます。
REVOKE EXECUTE ON PROCEDURE MyProc1 FROM user1;
————————
次の例では、Demodata サンプル データベースのセキュリティが有効になっており、ユーザー名 USAcctsMgr に対して、テーブル Person の ID 列に SELECT 権が付与されているものとします。そのユーザーから、対象列の SELECT 権限を取り消します。以下のステートメントを使用します。
REVOKE SELECT ( ID ) ON Person FROM 'USAcctsMgr'
関連項目
ROLLBACK
ROLLBACK は、データベースを現行トランザクションが開始される前の状態に戻します。このステートメントにより、最後に行った SAVEPOINT または START TRANSACTION 以降に取得したロックを解放します。
ROLLBACK TO SAVEPOINT は、指定されたセーブポイントまでトランザクションをロールバックします。
構文
セーブポイント名 ::= ユーザー定義名
備考
AUTOCOMMIT がオフの場合、ROLLBACK、SAVEPOINT、および RELEASE はセッション レベル(ストアド プロシージャの外部)でのみサポートされます。そうでない場合、ROLLBACK、SAVEPOINT、および RELEASE はストアド プロシージャ内で使用しなければなりません。
ストアド プロシージャ内でコミットされたステートメントは、呼び出し元の SQL アプリケーションの一番外側のトランザクションによって制御されます。
ネストされたトランザクションの場合、ROLLBACK は一番近い START TRANSACTION までロール バックします。たとえば、トランザクションが 5 レベルまでネストされている場合、すべてのトランザクションを元に戻すには 5 つの ROLLBACK ステートメントが必要になります。トランザクションは、コミットされるかロール バックされるかのいずれかで、両方はされません。つまり、コミットされたトランザクションをロール バックすることはできません。
例
次のステートメントによって、トランザクションの開始以降に行われたデータベースの変更を元に戻します。
ROLLBACK WORK;
次のステートメントによって、Svpt1 と名付けられた最後のセーブポイント以降に行われたデータベースの変更を元に戻します。
ROLLBACK TO SAVEPOINT Svpt1;
関連項目
SAVEPOINT
SAVEPOINT は、ロール バック可能なトランザクション内のポイントを定義します。
構文
SAVEPOINT セーブポイント名
セーブポイント名 ::= ユーザー定義名
備考
AUTOCOMMIT がオフの場合、ROLLBACK、SAVEPOINT、および RELEASE はセッション レベル(ストアド プロシージャの外部)でのみサポートされます。そうでない場合、ROLLBACK、SAVEPOINT、および RELEASE はストアド プロシージャ内で使用しなければなりません。
ストアド プロシージャ内でコミットされたステートメントは、呼び出し元の SQL アプリケーションの一番外側のトランザクションによって制御されます。
SAVEPOINT は、それが定義されているプロシージャにのみ適用されます。つまり、別のプロシージャ内に定義されている SAVEPOINT は参照できません。
例
次の例では、SAVEPOINT を設定し、その後で条件を調べて SAVEPOINT を ROLLBACK するか RELEASE するかが判断されます。
CREATE PROCEDURE Enroll_student( IN :student ubigint, IN :classnum INTEGER);
BEGIN
DECLARE :CurrentEnrollment INTEGER;
DECLARE :MaxEnrollment INTEGER;
SAVEPOINT SP1;
INSERT INTO Enrolls VALUES (:student, :classnum, 0.0);
SELECT COUNT(*) INTO :CurrentEnrollment FROM Enrolls WHERE class_id = :classnum;
SELECT Max_size INTO :MaxEnrollment FROM Class WHERE ID = :classnum;
IF :CurrentEnrollment >= :MaxEnrollment THEN
ROLLBACK TO SAVEPOINT SP1;
ELSE
RELEASE SAVEPOINT SP1;
END IF;
END;
COUNT(式) によって、述部にある式の非ヌル値がすべてカウントされるということを覚えておいてください。COUNT(*) ではヌル値を含むすべての値がカウントされます。
関連項目
SELECT
指定された情報をデータベースから取り出します。SELECT ステートメントにより、テンポラリ ビューを作成します。
構文
クエリ スペック ::= ( クエリ スペック )
FROM テーブル参照 [ , テーブル参照 ]...
[ WHERE 検索条件 ]
[ HAVING 検索条件 ] ]
式またはサブクエリ ::= 式 | ( クエリ スペック ) [ ORDER BY order-by式
[ , order-by式 ]... ] [ limit句 ]
サブクエリ式 ::= ( クエリ スペック ) [ ORDER BY order-by式
[ , order-by式 ]... ] [ limit句 ]
limit句 ::= [ LIMIT [オフセット,] 行数 | 行数 OFFSET オフセット | ALL [ OFFSET オフセット ] ]
オフセット ::= 数値 | ?
行数 ::= 数値 | ?
選択リスト ::= * | 選択項目 [ , 選択項目 ]...
テーブル参照 ::= { OJ 外部結合定義 }
| 結合定義
| ( 結合定義 )
外部結合定義 ::= テーブル参照 外部結合タイプ JOIN テーブル参照
ON 検索条件
外部結合タイプ ::= LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
テーブル ヒント ::= INDEX ( インデックス値 [ , インデックス値 ]... )
インデックス値 ::= 0 | インデックス名
インデックス名 ::= ユーザー定義名
結合定義 ::= テーブル参照 [ 結合タイプ ] JOIN テーブル参照 ON 検索条件
| テーブル参照 CROSS JOIN テーブル参照
| 外部結合定義
結合タイプ ::= INNER | LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
検索条件 ::= 検索条件 AND 検索条件
| 検索条件 OR 検索条件
| NOT 検索条件
| ( 検索条件 )
| 述部
| 式またはサブクエリ 比較演算子 式またはサブクエリ
比較演算子 ::= < | > | <= | >= | = | <> | !=
式またはサブクエリ ::= 式 | ( クエリ スペック )
式 ::= 式 - 式
| 式 + 式
| 式 * 式
| 式 / 式
| 式 & 式
| 式 | 式
| 式 ^ 式
| ( 式 )
| -式
| +式
| 列名
| ?
| リテラル
| セット関数
| スカラー関数
| { fn スカラー関数 }
| ウィンドウ関数
else式 ] END
| COALESCE ( 式, 式 [ ,...] )
| SQLSTATE
| サブクエリ式
| NULL
| : ユーザー定義名
| USER
| グローバル変数
| 仮想列
サブクエリ式 ::= ( クエリ スペック )
| LAG ( 式 [ , 式 [ , 式 ] ] over句 )
スカラー関数 ::= スカラー関数を参照
グローバル変数 ::= @:IDENTITY
| @:ROWCOUNT
| @@BIGIDENTITY
| @@IDENTITY
| @@ROWCOUNT
| @@SPID
| @@VERSION
仮想列 ::= SYS$CREATE
| SYS$UPDATE
ウィンドウ関数 ::= セット関数 over句
over句 ::= OVER ( [ partition-by句 ] order-by-in-over句 [ row句 ] )
partition-by句 ::= PARTITION BY 式 [ , 式 ]...
order-by-in-over句 ::= ORDER BY 式 [ ASC | DESC ] [ , 式 [ ASC | DESC ] ]...
row句 ::= ROWS ウィンドウ フレームの範囲
ウィンドウ フレームの範囲::= { UNBOUNDED PRECEDING
| 符号なし整数リテラル PRECEDING
| CURRENT ROW }
メモ:OVER 句での ORDER BY の使用は、Zen SQL の他の場所での ORDER BY とは異なります。本リリースに適用される詳細および関連情報については、SQL ウィンドウ関数を参照してください。
備考
ここでは、SELECT の使用に関連する次のトピックについて説明します。
FOR UPDATE
SELECT FOR UPDATE は、クエリで選択されたテーブル内の 1 つまたは複数の行をロックします。レコード ロックは、次の COMMIT または ROLLBACK ステートメントが発行されたときに解放されます。
この競合を避けるため、SELECT FOR UPDATE は行を取得しているときロックします。
ステートメント レベル SQL_ATTR_CONCURRENCY が SQL_CONCUR_LOCK に設定されている場合、SELECT FOR UPDATE はトランザクション内で優先されます。SQL_ATTR_CONCURRENCY が SQL_CONCUR_READ_ONLY に設定されている場合、データベース エンジンはエラーを返しません。
SELECT FOR UPDATE は WAIT および NOWAIT キーワードをサポートしません。SELECT FOR UPDATE は、短時間で行をロックできない場合(20 回再試行)、ステータス コード 84:レコードまたはページはロックされています。 を返します。
制約
SELECT FOR UPDATE ステートメントには以下の制約があります。
• トランザクション内のみで有効です。トランザクション外で使用された場合、そのステートメントは無視されます。
• 単一のテーブルのみでサポートされます。SELECT FOR UPDATE は、JOIN や単純でないビュー、また、GROUP BY、DISTINCT、UNION キーワードと共には使用できません。
• CREATE VIEW ステートメント内では使用できません。
GROUP BY
Zen では、列リストの GROUP BY がサポートされているほか、式リストや、GROUP BY 式リスト内のあらゆる式に対する GROUP BY がサポートされています。GROUP BY 拡張の詳細については、GROUP BY を参照してください。GROUP BY のない HAVING はサポートされていません。
次の特性のいずれかを備えた SELECT ステートメントを実行することによって生成される結果セットおよびストアド ビューは、読み取り専用になります(更新できません)。つまり、位置付け UPDATE や位置付け DELETE、および SQLSetPos 呼び出しを使用して、結果セットあるいはストアド プロシージャでデータを追加、変更、削除することは許可されません。
• 選択リストに集計を含んでいる
SELECT SUM(c1) FROM t1
SELECT SUM(c1) FROM t1
• 選択リストに DISTINCT を指定している
SELECT DISTINCT c1 FROM t1
SELECT DISTINCT c1 FROM t1
• ビューに GROUP BY を使用している
SELECT SUM(c1), c2 FROM t1 GROUP BY c2
SELECT SUM(c1), c2 FROM t1 GROUP BY c2
• ビューは結合である(複数のテーブルを参照する)
SELECT * FROM t1, t2
SELECT * FROM t1, t2
• ビューに UNION 演算子を使用しており、UNION ALL が指定されていないか、もしくはすべての SELECT ステートメントが同じテーブルを参照していない
SELECT c1 FROM t1 UNION SELECT c1 FROM t1
SELECT c1 FROM t1 UNION ALL SELECT c1 FROM t2
SELECT c1 FROM t1 UNION SELECT c1 FROM t1
SELECT c1 FROM t1 UNION ALL SELECT c1 FROM t2
ストアド ビューでは UNION 演算子を使用できないので注意してください。
• ビューに、外部クエリ内のテーブル以外のテーブルを参照するサブクエリを含んでいる
SELECT c1 FROM t1 WHERE c1 IN (SELECT c1 FROM t2)
SELECT c1 FROM t1 WHERE c1 IN (SELECT c1 FROM t2)
SQL ウィンドウ関数
Zen は、ANSI 標準の SQL ウィンドウ使用のサブセットを提供します。本リリースにおけるこの初期導入には、一定の制限事項および考慮事項があります。
制限事項
OVER 句には次の制限があります。
• SELECT ステートメント内のすべての OVER 句は、それらの PARTITION BY、ORDER BY、および ROWS 句と一致している必要があります。PARTITION BY の式は同一かつ同順である必要があり、ORDER BY の式も同一かつ同順、ROWS 句は同一である必要があります。これらのうち OVER 句に存在しない句は、他の句にも存在しない必要があります。
• OVER 句には ORDER BY 句を含める必要があります。PARTITION BY 句は省略可能です。PARTITION BY が存在する場合、この句で ORDER BY 句と同じ列を使用してはいけません。PARTITION BY がない場合は、結果セット全体が 1 つのパーティションとして扱われます。
• PARTITION BY 句の ROWS の指定では、次のキーワードがサポートされています。
• UNBOUNDED
• n PRECEDING
• CURRENT ROW
• PARTITION BY 句の ROWS の指定では、次のキーワードはサポートされていません。
• BETWEEN
• FOLLOWING
• RANGE キーワードはサポートされていません。
• DISTINCT キーワードは、セット関数ではサポートされていません。
• OVER 句の ORDER BY 句では、COLLATE の指定はサポートされていません。
• ウィンドウ関数は、前方のみのカーソルでしか使用できません。
考慮事項
ANSI SQL 標準では、特定の構文の組み合わせはデフォルトの RANGE セマンティクスを意味しますが、現在の Zen リリースでは RANGE はサポートされていません。したがって、現在の Zen リリースでは、デフォルトの RANGE 指定が RANGE UNBOUNDED PRECEDING である場合には、このデフォルトは ROWS UNBOUNDED PRECEDING として実装されます。
通常、これら 2 つのデフォルトの違いが結果セットに影響するのは、PARTITION BY 句と ORDER BY 句で返される列の値の組み合わせが行ごとに一意でない場合だけです。そのため、現在の Zen リリースでは、そのような列の値の組み合わせが行ごとに一意でない場合は、ROWS UNBOUNDED PRECEDING を明示的に指定することをお勧めします。これにより期待される結果が返ります。
動的パラメーター
動的パラメーター(疑問符(?)で表されます)は、SELECT 項目としてはサポートされていません。動的パラメーターが述部の一部であれば、SELECT ステートメント内で使用することができます。たとえば、SELECT * FROM faculty WHERE id = ? は、動的パラメーターが述部の一部なので有効です。
Zen Control Center の SQL Editor では、述部に動的パラメーターを含む SQL ステートメントを実行できないことに留意してください。
変数は、ストアド プロシージャ内でのみ SELECT 項目として使用することができます。CREATE PROCEDURE を参照してください。
エイリアス
WHERE、HAVING、ORDER BY、または GROUP BY 句にエイリアスを含めることができます。エイリアス名はテーブル内のどの列名とも異なっていなければなりません。次のステートメントは、WHERE 句と GROUP BY 句でエイリアス a および b を使用する例を示しています。
SELECT Student_ID a, Transaction_Number b, SUM (Amount_Owed) FROM Billing WHERE a < 120492810 GROUP BY a, b UNION SELECT Student_ID a, Transaction_Number b, SUM (Amount_Paid) FROM Billing WHERE a > 888888888 GROUP BY a, b
SUM と DECIMAL の精度
DECIMAL 型のフィールドで SUM 集計関数を使用する場合は、次の規則が適用されます。
• 結果の有効桁数は 74 ですが、小数部桁数は列定義に依存します。
• 74 を超える桁数の数値(本当に、非常に大きな数値です)が計算された場合、結果でオーバーフロー エラーが発生することがあります。オーバーフローが発生した場合、値は返らず、SQLSTATE に数値が範囲外であることを示す 22003 が設定されます。
サブクエリ
サブクエリは一種の SELECT ステートメントで、ステートメント内に 1 つ以上の SELECT ステートメントを含んでいます。サブクエリは、ステートメントの処理を進めるために値を生成します。一番上の SELECT ステートメントでサブクエリをネストできる最大数は 16 です。
サポートされるサブクエリのタイプは次のとおりです。
• comparison
• quantified
• in
• exists
• correlated
• expression
• table
相関サブクエリ述部は、グループ化された列を参照する HAVING 句ではサポートされていません。
expression サブクエリは、SELECT リストの中でサブクエリを使用できます。たとえば、SELECT (SELECT SUM(c1) FROM t1 WHERE t1.c2 = t1.(c2) FROM t2 のように記述できます。サブクエリの SELECT リストに指定できる項目は 1 つのみです。たとえば、次のステートメントは、サブクエリの SELECT リストに 2 つ以上の項目が含まれているため、エラーが返ります。SELECT p.id, (SELECT SUM(b.amount_owed), SUM(b.amount_paid) FROM billing b) FROM person p
式としてのサブクエリは相関でも非相関でもかまいません。相関サブクエリは、一番上のステートメントに指定されているテーブル内の 1 つ以上の列を参照します。非相関サブクエリは、一番上のステートメントに指定されているテーブル内の列を参照しません。次の例は、WHERE 句の相関サブクエリを示しています。
SELECT * FROM student s WHERE s.Tuition_id IN
(SELECT t.ID FROM tuition t WHERE t.ID = s.Tuition_ID);
メモ: テーブル サブクエリでは、非相関サブクエリはサポートされますが、相関サブクエリはサポートされません。
相関および非相関のサブクエリは、どちらも単一の値のみ返すことができます。このため、相関サブクエリおよび非相関サブクエリはスカラー サブクエリとも呼ばれます。
スカラー サブクエリは、DISTINCT、GROUP BY、および ORDER BY 句に含むことができます。
サブクエリは式の左辺で使用することができます。
式またはサブクエリ 比較演算子 式またはサブクエリ
ここで、式は 1 つの式、比較演算子は次のうちのいずれかです。
< (より小さい) | > (より大きい) | <= (小さいかまたは等しい) | >= (大きいかまたは等しい) | = (等しい) |
<> (等しくない) | != (等しくない) | LIKE | IN | NOT IN |
このセクションの残り部分では、以下の項目について説明します。
サブクエリの最適化
左辺のサブクエリの動作は、サブクエリが相関サブクエリでなく、すべての結合条件が 1 つの外部結合である場合の、IN、NOT IN、および =ANY について最適化されています。それ以外の条件は最適化されないことがあります。次は、これらの条件を満たすクエリの例です。
SELECT count(*) FROM person WHERE id IN (SELECT faculty_id FROM class)
Zen はインデックスに基づいてサブクエリを最適化するため、サブクエリでインデックスを使用するとパフォーマンスが向上します。たとえば、次のステートメント内のサブクエリは、student_id が Billing テーブルのインデックスであるため、この列によって最適化されます。
SELECT (SELECT SUM(b.amount_owed) FROM billing b WHERE b.student_id = p.id) FROM person p
サブクエリ内の UNION
1 つのサブクエリの中で、複数の異なる UNION グループをかっこで囲むことは許可されていません。かっこは各 SELECT ステートメントの中で使用できます。
たとえば、次のステートメントで、IN の後のかっこと最後のかっこは許可されません。
SELECT c1 FROM t5 WHERE c1 IN ( (SELECT c1 FROM t1 UNION SELECT c1 FROM t2) UNION ALL (SELECT c1 FROM t3 UNION SELECT c1 from t4) )
テーブル サブクエリ
テーブル サブクエリを使用すると、複数のクエリを組み合わせて 1 つの詳細なクエリにすることができます。テーブル サブクエリは、データベースに残らない動的ビューです。一番上の SELECT クエリが完了したら、テーブル サブクエリに関連付けられたすべてのリソースが解放されます。
メモ: テーブル サブクエリでは、非相関サブクエリのみが使用できます。相関サブクエリは使用できません。
次の改ページ調整の例(1 ページあたり 100 行ずつの 1500 行)は、ORDER BY キーワードを使用したテーブル サブクエリの使用方法を示しています。
最初の 100 行
SELECT * FROM ( SELECT TOP 100 * FROM ( SELECT TOP 100 * FROM person ORDER BY last_name asc ) AS foo ORDER BY last_name desc ) AS bar ORDER BY last_name ASC
2 番目の 100 行
SELECT * FROM ( SELECT TOP 100 * FROM ( SELECT TOP 200 * FROM person ORDER BY last_name asc ) AS foo ORDER BY last_name DESC ) AS bar ORDER BY last_name ASC
...
15 番目の 100 行
SELECT * FROM ( SELECT TOP 100 * FROM ( SELECT TOP 1500 * FROM person ORDER BY last_name ASC ) AS foo ORDER BY last_name DESC ) AS bar ORDER BY last_name ASC
テーブル ヒントの使用
テーブル ヒント機能を使用すると、クエリの最適化のために、どのインデックスを使用するかを指定することができます。テーブル ヒントは、データベース エンジンが使用するデフォルトのクエリ オプティマイザーより優先されます。
テーブル ヒントで INDEX(0) が指定されていると、エンジンは関連するテーブルのテーブル スキャンを実行します。テーブル スキャンは、インデックスを使用して特定のデータ要素を見つけるのではなく、テーブル内の各行を読み取ります。
テーブル ヒントに INDEX(インデックス名) が指定されている場合、エンジンはインデックス名を使用し、JOIN 条件の制約や、DISTINCT、GROUP BY、ORDER BY の使用に基づいてテーブルを最適化します。指定されたインデックスでテーブルが最適化できない場合、エンジンは既存のインデックスに基づいて最適化を試みます。
複数のインデックス名を指定した場合、エンジンは最適なパフォーマンスを得られるインデックスを選択するか、OR 最適化のために複数のインデックスを使用します。わかりやすくするために例を示します。以下を想定します。
CREATE INDEX ndx1 on t1(c1)
CREATE INDEX ndx2 on t1(c2)
CREATE INDEX ndx3 on t1(c3)
SELECT * FROM t1 WITH (INDEX (ndx1, ndx2)) WHERE c1 = 1 AND c2 > 1 AND c3 = 1
データベース エンジンは、ndx2 を使用するのではなく ndx1 を使用して、c1 = 1 を最適化します。ndx3 は、テーブル ヒントに含まれていないため、考慮に入れません。
以下について考えてみましょう。
SELECT * FROM t1 WITH (INDEX (ndx1, ndx2)) WHERE (c1 = 1 OR c2 > 1) AND c3 = 1
エンジンは ndx1 と ndx2 の両方を使用して(c1 = 1 OR c2 > 1)を最適化します。
テーブル ヒントの中で複数のインデックス名が表れる順序は重要ではありません。データベース エンジンは、指定されたインデックスから最も優れた最適化を行えるインデックスを選択します。
テーブル ヒント内で重複するインデックス名は無視されます。
結合されたビューでは、FROM 句の最後ではなく、適切なテーブル名の後にテーブル ヒントを指定します。たとえば、次は正しいステートメントです。
SELECT * FROM person WITH (INDEX(Names)), student WHERE student.id = person.id AND last_name LIKE 'S%'
これに対し、次のステートメントは正しくありません。
SELECT * FROM person, student WITH (INDEX(Names)) WHERE student.id = person.id AND last_name LIKE 'S%'
メモ: テーブル ヒント機能は上級ユーザー向けです。一般的に、データベース クエリ オプティマイザーが最も優れた最適化方法を選択するので、テーブルヒントは必要ではありません。
テーブル ヒントの制限事項
• テーブル ヒントで使用できるインデックス名の最大数は、SQL ステートメントの最大長(64 KB)によってのみ制限されます。
• テーブル ヒント内のインデックス名は、テーブル名で完全に修飾されていてはなりません。
間違った SQL: | SELECT * FROM t1 WITH (INDEX(t1.ndx1)) WHERE t1.c1 = 1 |
戻り値: | SQL_ERROR |
szSqlState: | 37000 |
メッセージ: | 構文エラー:SELECT * FROM t1 WITH (INDEX(t1.<< ??? >>ndx1)) WHERE t1.c1 = 1 |
• テーブル ヒントは、SELECT ステートメント内でビューと共に使用された場合は無視されます。
間違った SQL: | SELECT * FROM myt1view WITH (INDEX(ndx1)) |
戻り値: | SQL_SUCCESS_WITH_INFO |
szSqlState: | 01000 |
メッセージ: | ビューと共に指定されたインデックス ヒントは無視されます。 |
• インデックス名以外ではゼロが唯一の有効なヒントです。
間違った SQL: | SELECT * FROM t1 WITH (INDEX(85)) |
戻り値: | SQL_ERROR |
szSqlState: | S1000 |
メッセージ: | インデックス ヒントが無効です。 |
• テーブル ヒント内のインデックス名には既存のインデックスを指定する必要があります。
間違った SQL: | SELECT * FROM t1 WITH (INDEX(ndx4)) |
戻り値: | SQL_ERROR |
szSqlState: | S0012 |
メッセージ: | インデックス名が無効です。インデックスが見つかりません。 |
• テーブル ヒントは、サブクエリ AS テーブルには指定できません。
間違った SQL: | SELECT * FROM (SELECT c1, c2 FROM t1 WHERE c1 = 1) AS a WITH (INDEX(ndx2)) WHERE a.c2 = 10 |
戻り値: | SQL_ERROR |
szSqlState: | 37000 |
メッセージ: | 構文エラー:SELECT * FROM (SELECT c1, c2 FROM t1 WHERE c1 = 1) AS a WITH<< ??? >>(INDEX(ndx2)) WHERE a.c2 = 10 |
システム データ v2 のアクセス
13.0 および 16.0 形式を使用するデータ ファイルでは、システム データ v2 により、レコード作成およびレコード更新のタイム スタンプに基づく Btrieve キーが有効になります。これらの作成キーおよび更新キーには以下の特性があります。
• 作成キーは既存の Btrieve システム キー 125 に取って代わり、トランザクション ログで使用されます。
• 更新キーによって、キー 125 の作成時刻のタイム スタンプなど、特定の時点以降に変更された行を特定することができます。更新キーは Btrieve システム キー 124 です。
• どちらのキーも、セプタ秒精度を持つ TIMESTAMP(7) 形式、YYYY-MM-DD HH:MM:SS.sssssss です。
• SQL クエリでは、列名 sys$create および sys$update を使用してタイム スタンプにアクセスできます。作業例については、Sys$create および Sys$update を使用したクエリを参照してください。
例
この単純な SELECT ステートメントによって、Faculty テーブルの全データが取り出されます。
SELECT * FROM Faculty
このステートメントによって、person および faculty テーブルから、person テーブル内の id 列と faculty テーブル内の id 列が同じデータが取り出されます。
SELECT Person.id, Faculty.salary FROM Person, Faculty WHERE Person.id = Faculty.id
このセクションの残り部分では、SELECT ステートメントのさまざまな例を示します。次の見出しのうちのいくつかは、SELECT の構文定義に示される変数に基づいています。
FOR UPDATE
次の例ではテーブル t1 を使用して FOR UPDATE の使用法を示します。t1 は Demodata サンプル データベースの一部であるとします。ストアド プロシージャは SELECT FOR UPDATE ステートメントのためのカーソルを作成します。ループで t1 から c1=2 の行の各レコードをフェッチし、c1 の値を 4 に設定します。
プロシージャは、IN パラメーターとして値 2 を渡して呼び出されます。
この例は、2 人のユーザー A と B は Demodata にログインしているものとします。ユーザー A が以下の処理を行います。
DROP TABLE t1
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
CREATE PROCEDURE p1 (IN :a INTEGER)
AS
BEGIN
DECLARE :b INTEGER;
DECLARE :i INTEGER;
DECLARE c1Bulk CURSOR FOR SELECT * FROM t1 WHERE c1 = :a FOR UPDATE;
START TRANSACTION;
OPEN c1Bulk;
BulkLinesLoop:
LOOP
FETCH NEXT FROM c1Bulk INTO :i;
IF SQLSTATE = '02000' THEN
LEAVE BulkLinesLoop;
END IF;
UPDATE SET c1 = 4 WHERE CURRENT OF c1Bulk;
END LOOP;
CLOSE c1Bulk;
SET :b = 0;
WHILE (:b < 100000) DO
BEGIN
SET :b = :b + 1;
END;
END WHILE;
COMMIT WORK;
END;
CALL p1(2)
WHILE ループがトランザクションの COMMIT を遅延させることに注意してください。この遅延の間、ユーザー B は t1 の更新を試みるとします。これらの行はユーザー A が SELECT FOR UPDATE ステートメントでロックしているため、ユーザー B にはステータス コード 84 が返されます。
————————
次の例ではテーブル t1 を使用して、SELECT FOR UPDATE がストアド プロシージャの外部で使用された場合のレコードのロック方法を示します。t1 は Demodata サンプル データベースの一部であるとします。
この例は、2 人のユーザー A と B は Demodata にログインしているものとします。ユーザー A が以下の処理を行います。
DROP TABLE t1
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
(AUTOCOMMIT をオフにする)
(実行して取り出す):"SELECT * FROM t1 WHERE c1 = 2 FOR UPDATE"
c1 = 2 である 2 つのレコードは、ユーザー A が COMMIT WORK または ROLLBACK WORK ステートメントを発行するまでロックされます。
(ユーザー B が t1 の更新を試みる):"UPDATE t1 SET c1=3 WHERE c1=2" これらの行はユーザー A が SELECT FOR UPDATE ステートメントでロックしているため、ユーザー B にはステータス コード 84 が返されます。
(ここで、ユーザー A がトランザクションをコミットしたとします。)c1 = 2 である 2 つのレコードのロックは解除されます。
これで、ユーザー B は "UPDATE t1 SET c1=3 WHERE c1=2" を実行して、c1 の値を変更できます。
概算数値リテラル
SELECT * FROM results WHERE quotient =-4.5E-2
INSERT INTO results (quotient) VALUES (+5E7)
BETWEEN 述語
式1 BETWEEN 式2 and 式3 という構文では、式1 >= 式2 かつ、式1 <= 式3 の場合に True が返されます。式1 >= 式3 または式1 <= 式2 の場合は、False が返されます。
式2 と式3 は動的パラメーター(たとえば、SELECT * FROM emp WHERE emp_id BETWEEN ? AND ?)にすることができます。
次の例では、ID が 10000 と 20000 の間にある名が Person テーブルから取り出されます。
SELECT First_name FROM Person WHERE ID BETWEEN 10000 AND 20000
相関名
テーブルと列の相関名はどちらもサポートされています。
次の例では、person テーブルと faculty テーブルからデータが選択されます。2 つのテーブルを区別するためにエイリアスの T1 と T2 を使用しています。
SELECT * FROM Person t1, Faculty t2 WHERE t1.id = t2.id
また、テーブルの相関名は、次の例のように FROM 句を使って指定することもできます。
SELECT a.Name, b.Capacity FROM Class a, Room b
WHERE a.Room_Number = b.Number
正確な数値リテラル
SELECT car_num, price FROM cars WHERE car_num = 49042 AND price = 49999.99
IN 述語
これにより、名が Bill と Roosevelt のレコードがテーブル Person から選択されます。
SELECT * FROM Person WHERE First_name IN ('Roosevelt', 'Bill')
セット関数
Zen ではセット関数 AVG、COUNT、COUNT_BIG、LAG、MAX、MIN、STDEV、STDEVP、SUM、VAR、および VARP がサポートされています。それぞれ以下の例で説明します。
LAG は、ウィンドウ関数としてのみ有効です。この詳細と例については、LAG キーワードを参照してください。
AVG、MAX、MIN、および SUM
集計関数の AVG、MAX、MIN、および SUM は、一般に予想されるとおりに動作します。次の例は、Faculty サンプル テーブルの Salary フィールドを用いてこれらの関数の使い方を示しています。
SELECT AVG(Salary) FROM Faculty
SELECT MAX(Salary) FROM Faculty
SELECT MIN(Salary) FROM Faculty
SELECT SUM(Salary) FROM Faculty
ほとんどの場合、これらの関数は GROUP BY と一緒に使用され、次の例で示すように、共通の列を持つ一連の行に適用されます。
SELECT AVG(Salary) FROM Faculty GROUP BY Dept_Name
次の例では、amount_paid の総額が 100 以上の場合に、student_id と amount_paid の総額が billing テーブルから取り出されます。次に、student_id 別にレコードが分類されます。
SELECT Student_ID, SUM(Amount_Paid)
FROM Billing
GROUP BY Student_ID
HAVING SUM(Amount_Paid) >=100.00
式が正の整数リテラルの場合、そのリテラルが結果セット内の列の番号として解釈され、その列について順序付けが行われます。セット関数またはセット関数を含む式については、順序付けは許可されません。
COUNT および COUNT_BIG
COUNT(式)および COUNT_BIG(式)によって、述部にある式の非ヌル値すべてがカウントされます。COUNT(*) および COUNT_BIG(*) では、ヌル値を含むすべての値がカウントされます。COUNT() は、最大値が 2,147,483,647 である INTEGER データ型を返します。COUNT_BIG() は、最大値が 9,223,372,036,854,775,807 である BIGINT データ型を返します。
次の例は、成績評価点平均が 3.5 以上ある(および、結果がヌルでない)化学専攻の学生の数を返します。
SELECT COUNT(*) FROM student WHERE (CUMULATIVE_GPA > 3.4 and MAJOR='Chemistry')
STDEV および STDEVP
STDEV 関数は、データのサンプルに基づいて、すべてのデータの標準偏差を返します。STDEVP 関数は、指定された式のすべての値の母集団に対する標準偏差を返します。各関数の方程式は以下のとおりです。 
次の例は、Student サンプル テーブルから、専攻科目別に成績評価点平均の標準偏差を返します。
SELECT STDEV(Cumulative_GPA), Major FROM Student GROUP BY Major
次の例は、Student サンプル テーブルから、専攻科目別に成績評価点平均の母集団の標準偏差を返します。
SELECT STDEVP(Cumulative_GPA), Major FROM Student GROUP BY Major
VAR および VARP
VAR 関数は、データのサンプルに基づいて、すべての値の統計的分散を返します。VARP 関数は、指定された式のすべての値の母集団に対する統計的分散を返します。各関数の方程式は以下のとおりです。 
次の例は、Student サンプル テーブルから、専攻科目別に成績評価点平均の統計的分散を返します。
SELECT VAR(Cumulative_GPA), Major FROM Student GROUP BY Major
次の例は、Student サンプル テーブルから、専攻科目別に成績評価点平均の母集団の統計的分散を返します。
SELECT VARP(Cumulative_GPA), Major FROM Student GROUP BY Major
STDEV、STDEVP、VAR、および VARP の場合、式は数値データ型である必要があり、8 バイトの DOUBLE が返されるということに注意してください。式の最小値と最大値の差が範囲外である場合は、浮動小数点のオーバーフロー エラーになります。式に集計関数を含むことはできません。式フィールドに値が入っている行が少なくとも 2 つはある必要があります。そうでないと、結果は計算されず、NULL が返されます。
日付リテラル
日付値を参照してください。
時刻リテラル
時刻値を参照してください。
タイムスタンプ リテラル
タイムスタンプ値を参照してください。
文字列リテラル
文字列値を参照してください。
日付演算
日付演算を参照してください。
IF
IF システム スカラー関数によって、条件の真の値に基づく条件付き実行が提供されます。
次の式は、列ヘッダー Prime1 を出力し、amount_owed 列の値が 2000 の場合は 2000 を、2000 でない場合は 0 を出力します。
SELECT Student_ID, Amount_Owed,
IF (Amount_Owed = 2000, Amount_Owed, Convert(0, SQL_DECIMAL)) "Prime1"
FROM Billing
次の例では、Class テーブルから、Section 列が 001 の場合はその値を、001 でない場合は "xxx" を、列ヘッダー Prime1 の下に出力します。
さらに、列ヘッダー Prime2 の下に、Section 列の値が 002 の場合はその値を、002 でない場合は "yyy" を出力します。
SELECT ID, Name, Section,
IF (Section = '001', Section, 'xxx') "Prime1",
IF (Section = '002', Section, 'yyy') "Prime2"
FROM Class
ネストした IF 関数を使用して、ヘッダー Prime1 とヘッダー Prime2 を合体させることができます。次のクエリは、列ヘッダー Prime の下に、Section 列の値が 001 か 002 の場合は Section 列の値を出力し、それ以外の場合は "xxx" を出力します。
SELECT ID, Name, Section,
IF (Section = '001', Section, IF(Section = '002', Section, 'xxx')) Prime
FROM Class
複数データベースの結合
必要であれば、データベース名を FROM 句内のエイリアス付きのテーブル名の前に付加して、結合で使用する 2 つ以上の異なるデータベースにあるテーブルを区別することができます。
指定したデータベースはすべて同じデータベース エンジンで処理し、同じデータベース コード ページ設定である必要があります。これらのデータベースは同じ物理ボリューム上になくてもかまいません。現行データベースはセキュリティで保護されていてもいなくてもかまいませんが、結合内のそれ以外のデータベースはセキュリティで保護されていない必要があります。参照整合性に関しては、すべての RI キーが同一のデータベース内に存在している必要があります。(エンコードも参照してください。)
リテラル データベース名は選択リストまたは WHERE 句内で使用することはできません。選択リストまたは WHERE 句内で特定の列を参照する場合は、指定する各テーブルのエイリアスを使用する必要があります。例を参照してください。
2 つの異なるデータベース accounting と customers が同じサーバー上に存在していると仮定します。次の例のようなテーブル エイリアスと SQL 構文を使って 2 つのデータベースにあるテーブルを結合することができます。
SELECT ord.account, inf.account, ord.balance, inf.address
FROM accounting.orders ord, customers.info inf
WHERE ord.account = inf.account
————————
次の例では、2 つのデータベースは acctdb と loandb です。テーブル エイリアスはそれぞれ a と b です。
SELECT a.loan_number_a, b.account_no, a.current_bal, b.balance
FROM acctdb.ds500_acct_master b LEFT OUTER JOIN loandb.ml502_loan_master a ON (a.loan_number_a = b.loan_number)
WHERE a.current_bal <> (b.balance * -1)
ORDER BY a.loan_number_a
左外部結合
次の例は、Demodata データベースの Person テーブルと Student テーブルにアクセスして、学生の姓と、名の頭文字、および GPA を取得する方法を示します。LEFT OUTER JOIN を使用すると、Person テーブル内のすべての行がフェッチされます(LEFT OUTER JOIN の左側にあるテーブル)。すべての人が GPA を持っているわけではないため、列によっては結果にヌル値を持ちます。以下は、外部結合がどのように働き、両方のテーブルから一致しない行を返すかを示します。
SELECT Last_Name, Left(First_Name,1) AS First_Initial, Cumulative_GPA AS GPA FROM "Person"
LEFT OUTER JOIN "Student" ON Person.ID=Student.ID
ORDER BY Cumulative_GPA DESC, Last_Name
完全に整数の GPA を持つ人全員がわかり、彼らをその姓の長さに従って並べたいとします。MOD ステートメントと LENGTH スカラー関数を使用して、クエリに次の文を追加することにより、これを実現できます。
WHERE MOD(Cumulative_GPA,1)=0 ORDER BY LENGTH(Last_Name)
右外部結合
LEFT OUTER JOIN と RIGHT OUTER JOIN との違いは、一致しないすべての行を表示する対象が RIGHT OUTER JOIN の右側に定義されたテーブルである点です。クエリの LEFT OUTER JOIN の部分を RIGHT OUTER JOIN を使用するように変更します。GPA がない場合でも、右テーブル(この場合は Student)から不一致行がすべて表示される点が異なります。ただし、Student テーブル内の行はすべて GPA を持つため、すべての行がフェッチされます。
SELECT Last_Name, Left(First_Name,1) AS First_Initial, Cumulative_GPA AS GPA FROM "Person"
RIGHT OUTER JOIN "Student" ON Person.ID=Student.ID
ORDER BY Cumulative_GPA DESC, Last_Name
カルテシアン結合
カルテシアン結合は、両方のテーブルの行を可能な限りすべて組み合わせた行列です。カルテシアン内の行数は、1 番目のテーブル内の行数に 2 番目のテーブル内の行数を掛けた値に等しくなります。
データベース内に次のようなテーブルがあるとします。
Addr テーブル
EmpID | Street |
|---|---|
E1 | 101 Mem Lane |
E2 | 14 Young St. |
Loc テーブル
LocID | Name |
|---|---|
L1 | PlanetX |
L2 | PlanetY |
次のステートメントにより、上記のテーブルのカルテシアン結合を実行します。
SELECT * FROM Addr,Loc
これにより、次のデータ セットが生成されます。
EmpID | Street | LocID | Name |
E1 | 101 Mem Lane | L1 | PlanetX |
E1 | 101 Mem Lane | L2 | PlanetY |
E2 | 14 Young St | L1 | PlanetX |
E2 | 14 Young St | L2 | PlanetY |
Sys$create および Sys$update を使用したクエリ
次の例は、作成時以降に更新されたレコードを検索する簡単な例を示します。
create table sensorData SYSDATA_KEY_2 (location varchar(20), temp real);
insert into sensorData values('Machine1', 77.3);
insert into sensorData values('Machine2', 79.8);
insert into sensorData values('Machine3', 65.4);
insert into sensorData values('Machine4', 90.0);
select "sys$create", "sys$update", sensorData.* from sensorData;
--行を更新します
update sensorData set temp = 90.1 where location = 'Machine1';
--更新された行を検索します
select "sys$create", "sys$update", sensorData.* from sensorData where sys$update > sys$create;
集計関数の DISTINCT
DISTINCT は集計関数で有用です。SUM、AVG、および COUNT と一緒に使用した場合は、重複する値を取り除いてから、総計、平均、件数を求めます。MIN および MAX と一緒に使用することはできますが、返される最大と最小の結果は変わりません。
たとえば、学部ごとの給与の最低額、最高額、平均額を知りたいと仮定します。このとき、同額の給与は除くことにします。次のステートメントは、computer science 学部以外の学部に対してこれを実行します。
SELECT dept_name, MIN(salary), MAX(salary), AVG(DISTINCT salary) FROM faculty WHERE dept_name<>'computer science' GROUP BY dept_name
反対に、同額の給与も含む場合は DISTINCT を省きます。
SELECT dept_name, MIN(salary), MAX(salary), AVG(salary) FROM faculty WHERE dept_name<>'computer science' GROUP BY dept_name
SELECT ステートメントでの DISTINCT の使用方法については、DISTINCT を参照してください。
TOP または LIMIT
TOP または LIMIT キーワードを使用することにより、SELECT ステートメントで返される行数を制限することができます。数値はリテラルの正の値でなければなりません。32 ビットの符号なし整数として定義します。たとえば、次のように指定します。
SELECT TOP 10 * FROM Person
Demodata の Person テーブルから最初の 10 行が返されます。
LIMIT は、OFFSET キーワードを提供する点を除けば、TOP とまったく同じです。OFFSET により、返されたレコード内で最初の行を選択することで、結果セット内を「スクロール」できるようになります。たとえば、オフセットを 5 にした場合、返される最初の行は行 6 になります。LIMIT には、オフセットを指定する方法が 2 つあります。次の例に示すように、OFFSET キーワードを使用する方法と使用しない方法で、どちらも同じ結果が返されます。
SELECT * FROM Person LIMIT 10 OFFSET 5
SELECT * FROM Person LIMIT 5,10
OFFSET キーワードを使用しない場合は、オフセット値を行数の前に、カンマで区切って置く必要があることに注意してください。
TOP または LIMIT を ORDER BY と一緒に使用することができます。その場合、データベース エンジンはテンポラリ テーブルを生成し、ORDER BY で使用できるインデックスがない場合は、そこにクエリの結果セット全体を置きます。テンポラリ テーブル内の行は、結果セットにおいて、ORDER BY で指定した順序で並べられますが、TOP または LIMIT によって決められた行数のみがクエリで返されます。
TOP または LIMIT を使用するビューは、ほかのテーブルやビューと結合できます。
TOP や LIMIT と SET ROWCOUNT の主な違いは、SET ROWCOUNT が現在のデータベース セッション中に発行される後続のステートメントすべてに作用するのに対し、TOP や LIMIT は現在のステートメントにのみ作用する点です。
クエリで SET ROWCOUNT と、TOP または LIMIT を使用した場合は、2 つの値のうち小さい方の値に等しい行数を返します。
TOP と LIMIT は、1 つのクエリまたはサブクエリ内でいずれか一方を使用できますが、両方は使用できません。
カーソルのタイプと TOP または LIMIT
TOP 句または LIMIT 句を持ち、動的カーソルを使用する SELECT クエリは、カーソルのタイプを静的カーソルに変換します。前方のみのカーソルと静的カーソルは影響を受けません。
TOP または LIMIT の例
次の例では、TOP と LIMIT の両方の句を使用しています。これらは、キーワードとして互いに代替でき、同じ結果を得られますが、LIMIT の方が返される行に関してより多くの制御を提供します。
SELECT TOP 10 * FROM person; -- 10 行を返します
SELECT * FROM person LIMIT 10; -- 10 行を返します
SELECT * FROM person LIMIT 10 OFFSET 5; -- 行 6 から 10 行を返します
SELECT * FROM person LIMIT 5,10; -- 行 6 から 10 行を返します
SET ROWCOUNT = 5;
SELECT TOP 10 * FROM person; -- 5 行を返します
SELECT * FROM person LIMIT 10; -- 5 行を返します
SET ROWCOUNT = 12;
SELECT TOP 10 * FROM person ORDER BY id; -- id 列で順序付けされた全リストから最初の 10 行を返します
SELECT * FROM person LIMIT 20 ORDER BY id; -- id 列で順序付けされた全リストから最初の 12 行を返します
————————
次の例では、TOP または LIMIT が VIEW、UNION、またはサブクエリで使用された場合のさまざまな動作を示します。
CREATE VIEW v1 (c1) AS SELECT TOP 10 id FROM person;
CREATE VIEW v2 (d1) AS SELECT TOP 5 c1 FROM v1;
SELECT * FROM v2 -- 5 行を返します
SELECT TOP 10 * FROM v2 -- 5 行を返します
SELECT TOP 2 * FROM v2 -- 2 行を返します
SELECT * FROM v2 LIMIT 10 -- 5 行を返します
SELECT * FROM v2 LIMIT 10 OFFSET 3 -- 行 4 から 2 行を返します
SELECT * FROM v2 LIMIT 3,10 -- 行 4 から 2 行を返します
SELECT TOP 10 id FROM person UNION SELECT TOP 13 faculty_id FROM class -- 17 行を返します
SELECT TOP 10 id FROM person UNION ALL SELECT TOP 13 faculty_id FROM class -- 23 行を返します
SELECT id FROM person WHERE id IN (SELECT TOP 10 faculty_id from class) -- 5 行を返します
SELECT id FROM person WHERE id >= any (SELECT TOP 10 faculty_id from class) -- 1040 行を返します
————————
次の例では、ID が特定の番号より上の学生について、その姓と支払う義務のある金額を返します。
SELECT p_last_name, b_owed FROM
(SELECT TOP 10 id, last_name FROM person ORDER BY id DESC) p (p_id, p_last_name),
(SELECT TOP 10 student_id, SUM (amount_owed) FROM billing GROUP BY student_id ORDER BY student_id DESC) b (b_id, b_owed)
WHERE p.p_id = b.b_id AND p.p_id > 714662900
ORDER BY p_last_name ASC
テーブル ヒントの例
このトピックでは、テーブル ヒントの作業例を提供します。Zen で SQL ステートメントを使用して、それらを作成します。
DROP TABLE t1
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 VALUES (1,10)
INSERT INTO t1 VALUES (1,10)
INSERT INTO t1 VALUES (2,20)
INSERT INTO t1 VALUES (2,20)
INSERT INTO t1 VALUES (3,30)
INSERT INTO t1 VALUES (3,30)
CREATE INDEX it1c1 ON t1 (c1)
CREATE INDEX it1c1c2 ON t1 (c1, c2)
CREATE INDEX it1c2 ON t1 (c2)
CREATE INDEX it1c2c1 ON t1 (c2, c1)
DROP TABLE t2
CREATE TABLE t2 (c1 INTEGER, c2 INTEGER)
INSERT INTO t2 VALUES (1,10)
INSERT INTO t2 VALUES (1,10)
INSERT INTO t2 VALUES (2,20)
INSERT INTO t2 VALUES (2,20)
INSERT INTO t2 VALUES (3,30)
INSERT INTO t2 VALUES (3,30)
テーブル ヒントの使用には、一定の制約が適用されます。テーブル ヒントの制限事項の例を参照してください。
————————
次の例は、インデックス it1c1c2 で最適化します。
SELECT * FROM t1 WITH (INDEX(it1c1c2)) WHERE c1 = 1
これを次の例と対比してみます。制約は c1 = 1 のみから成るため、次の例ではインデックス it1c2 ではなく it1c1 で最適化しています。クエリの最適化に使用できないインデックスがクエリに指定されている場合、ヒントは無視されます。
SELECT * FROM t1 WITH (INDEX(it1c2)) WHERE c1 = 1
————————
次の例はテーブル t1 のテーブル スキャンを実行します。
SELECT * FROM t1 WITH (INDEX(0)) WHERE c1 = 1
————————
次の例は、インデックス it1c1c2 および it1c2c1 で最適化します。
SELECT * FROM t1 WITH (INDEX(it1c1c2, it1c2c1)) WHERE c1 = 1 OR c2 = 10
————————
次の例は、ビューの作成でテーブル ヒントを使用します。すべてのレコードがビューから選択されると、SELECT ステートメントはインデックス it1c1c2 で最適化します。
DROP VIEW v2
CREATE VIEW v2 as SELECT * FROM t1 WITH (INDEX(it1c1c2)) WHERE c1 = 1
SELECT * FROM v2
————————
次の例はサブクエリでテーブル ヒントを使用し、インデックス it1c1c2 で最適化します。
SELECT * FROM (SELECT c1, c2 FROM t1 WITH (INDEX(it1c1c2)) WHERE c1 = 1) AS a WHERE a.c2 = 10
————————
次の例はサブクエリでテーブル ヒントを使用し、エイリアス名 "a" を使用します。このエイリアス名は必須です。
SELECT * FROM (SELECT Last_Name FROM Person AS P with (Index(Names)) ) a
————————
次の例は、c1 = 1 制約に基づいてクエリを最適化し、インデックス it1c1c2 に基づいて GROUP BY 句を最適化します。
SELECT c1, c2, count(*) FROM t1 WHERE c1 = 1 GROUP BY c1, c2
————————
次の例はインデックス it1c1 で最適化し、前の例とは異なり、制約のみで最適化して GROUP BY 句では最適化しません。
SELECT c1, c2, count(*) FROM t1 WITH (INDEX(it1c1)) WHERE c1 = 1 GROUP BY c1, c2
GROUP BY 句は指定したインデックス it1c1 を使用して最適化できないため、データベース エンジンは GROUP BY を処理するのにテンポラリ テーブルを使用します。
————————
次の例は JOIN 句でテーブル ヒントを使用し、インデックス it1c1c2 で最適化します。
SELECT * FROM t2 INNER JOIN t1 WITH (INDEX(it1c1c2)) ON t1.c1 = t2.c1
これを、テーブル ヒントを使用せずインデックス it1c1 で最適化する次のステートメントと対比してみます。
SELECT * FROM t2 INNER JOIN t1 ON t1.c1 = t2.c1
————————
次の例は JOIN 句でテーブル ヒントを使用し、テーブル t1 でテーブル スキャンを実行します。
SELECT * FROM t2 INNER JOIN t1 WITH (INDEX(0)) ON t1.c1 = t2.c1
これを、同じくテーブル t1 のテーブル スキャンを実行する次の例と対比してみます。ただし、JOIN 句が使用されていないため、このステートメントはテンポラリ テーブル結合を使用します。
SELECT * FROM t2, t1 WITH (INDEX(0)) WHERE t1.c1 = t2.c1
関連項目
SELECT(INTO 付き)
SELECT(INTO 付き)ステートメントを使用すると、指定したテーブルから列の値を選択して、変数に挿入したり、テーブルにデータを入れることができます。
構文
FROM テーブル参照 [ , テーブル参照 ]...[ WHERE 検索条件 ]
[ GROUP BY 式 [ , 式 ]...[ HAVING 検索条件 ] ] [ UNION [ ALL ] クエリ スペック ] [ ORDER BY order-by式 [ , order-by式 ]... ]
クエリ スペック ::= ( クエリ スペック )
FROM テーブル参照 [ , テーブル参照 ]...
[ WHERE 検索条件 ]
[ HAVING 検索条件 ] ]
変数 ::= ユーザー定義名
テーブル名 ::= テーブルのユーザー定義名
テンポラリ テーブル名 ::= テンポラリ テーブルのユーザー定義名
残りの構文定義については、SELECT を参照してください。
備考
変数は、ストアド プロシージャ、トリガー、およびユーザー定義関数内で生じる必要があります。
SELECT INTO を使用してテーブルにデータを入れられるのは、SELECT INTO ステートメントがユーザー定義関数またはトリガーの外部で使用される場合のみです。ユーザー定義関数またはトリガーの内部で、SELECT INTO を使用してテーブルを作成したりデータを入れることは許可されていません。
SELECT INTO をストアド プロシージャ内で使用することは許可されています。
SELECT INTO ステートメントによって作成し、データを入れることができるテーブルは 1 つだけです。単独の SELECT INTO ステートメントで複数のテーブルの作成とデータ投入を行うことはできません。
SELECT INTO で作成された新規テーブルは、ソース テーブルからの CASE および NOT NULL 制約によってのみ保守することができます。DEFAULT および COLLATE などのこれ以外の制約では保守できません。さらに、新しいテーブルにはインデックスは作成されません。
例
SELECT INTO を使用してテンポラリ テーブルにデータを入れる方法については、CREATE (テンポラリ) TABLEの例を参照してください。
次の例では、Person テーブルの、名前が Bill であるデータの first_name と last_name の値を変数 :x、:y に割り当てます。
SELECT first_name, last_name INTO :x, :y FROM person WHERE first_name = 'Bill'
関連項目
SET
SET ステートメントは、宣言された変数に値を割り当てます。
構文
SET 変数名 = プロシージャ式
備考
変数を設定するには、事前に変数が宣言されていなければなりません。SET は、ストアド プロシージャとトリガーでのみ使用できます。
例
次の例では、var1 に値 10 を割り当てます。
SET:var1 = 10;
関連項目
SET ANSI_PADDING
SET ANSI_PADDING ステートメントにより、NULL(バイナリ ゼロ)で埋められた CHAR データ型をリレーショナル エンジンで処理できるようになります。CHAR は固定長の文字データ型として定義されます。
Zen は 2 つのインターフェイス、トランザクショナルとリレーショナルをサポートしています。MicroKernel エンジンでは、CHAR を NULL で埋めることができます。一方、リレーショナル エンジンは ANSI 標準の埋め込み方法に従っているため、CHAR は空白で埋められます。たとえば、デフォルトでは、CREATE TABLE ステートメントで作成した CHAR 列は常に空白で埋められます。
両方のインターフェイスを使用しているアプリケーションの場合、NULL で埋められた文字列の処理が必要になる可能性があります。
構文
SET ANSI_PADDING = < ON | OFF >
備考
デフォルト値は ON です。これは、空白で埋められた文字列が CHAR に挿入されるということです。論理式の比較で、先頭の空白は意味のないものと見なされます。先頭の NULL は意味のあるものと見なされます。
このステートメントを OFF に設定すると、NULL で埋められた文字列が CHAR に挿入されるようになります。先頭の NULL と空白はどちらも論理式の比較で意味のないものと判断されます。
Windows では、ANSI 埋め込みは、レジストリ設定によって DSN に対してオンまたはオフに設定できます。Actian Web サイトの Zen Knowledge Base で "ansipadding" を検索してください。
以下の文字列関数は NULL の埋め込みをサポートしています。
CHAR_LENGTH | CONCAT | LCASE または LOWER |
LEFT | LENGTH | LOCATE |
LTRIM | POSITION | REPLACE |
REPLICATE | RIGHT | RTRIM |
STUFF | SUBSTRING | UCASE または UPPER |
ANSI_PADDING が各関数にどのような影響を与えるかについては、対応するスカラー関数の記述を参照してください。
制限
SET ANSI_PADDING には次の制限が適用されます。
• このステートメントは固定長の文字データ型 CHAR にのみ適用され、NCHAR、VARCHAR、NVARCHAR、LONGVARCHAR、および NLONGVARCHAR には適用されません。
• ステートメントはセッション レベルに適用されます。
例
次の例は、SET ANSI_PADDING を ON にした状態と OFF にした状態で、INSERT ステートメントによる文字列の埋め込みがどのような結果になるかを示しています。
DROP TABLE t1
CREATE TABLE t1 (c1 CHAR(4))
SET ANSI_PADDING = ON
INSERT INTO t1 VALUES ('a') -- 文字列 a = a\0x20\0x20\0x20
INSERT INTO t1 VALUES ('a' + CHAR(0) + CHAR(0) + CHAR(0)) -- 文字列 a = a\0x00\0x00\0x00
DROP TABLE t1
CREATE TABLE t1 (c1 CHAR(4))
SET ANSI_PADDING = OFF
INSERT INTO t1 VALUES ('a') -- 文字列 a = a\0x00\0x00\0x00
INSERT INTO t1 VALUES ('a' + CHAR(32) + CHAR(32) + CHAR(32)) -- 文字列 a = a\0x20\0x20\0x20
————————
次の例は、SET ANSI_PADDING を ON にした状態と OFF にした状態で、UPDATE ステートメントによる文字列の埋め込みがどのような結果になるかを示しています。
DROP TABLE t1
CREATE TABLE t1 (c1 CHAR(4))
SET ANSI_PADDING = ON
UPDATE t1 SET c1 = 'a' -- すべての行の c1 = a\0x20\0x20\0x20
UPDATE t1 SET c1 = 'a' + CHAR(0) + CHAR(0) + CHAR(0) -- すべての行の c1 = a\0x00\0x00\0x00
DROP TABLE t1
CREATE TABLE t1 (c1 CHAR(4))
SET ANSI_PADDING = OFF
UPDATE t1 SET c1 = 'a' -- すべての行の c1 = a\0x00\0x00\0x00
UPDATE t1 SET c1 = 'a' + CHAR(32) + CHAR(32) + CHAR(32) -- すべての行の c1 = a\0x20\0x20\0x20
————————
次の例は、文字型の列 c1 の内容をバイナリ形式で表示できるよう、c1 を BINARY データ型にキャストする方法を示します。テーブル t1 には次の 6 行のデータがあるとします。
a\x00\x00\x00\x00
a\x00\x00\x00\x00
a\x00\x20\x00\x00
a\x00\x20\x00\x00
a\x20\x20\x20\x20
a\x20\x20\x20\x20
次のステートメントにより、c1 が BINARY データ型にキャストされます。
SELECT CAST(c1 AS BINARY(4)) FROM t1
SELECT ステートメントは以下の結果を返します。
0x61000000
0x61000000
0x61002000
0x61002000
0x61202020
0x61202020
関連項目
SET CACHED_PROCEDURES
SET CACHED_PROCEDURES ステートメントは、データベース エンジンが SQL セッションのメモリにキャッシュするストアド プロシージャの数を指定します。
構文
SET CACHED_PROCEDURES = プロシージャ数
備考
プロシージャ数の値は、ゼロからおよそ 20 億までの整数です。データベース エンジンは、デフォルトを自動的に 50 とします。各セッションは、SET ステートメントを発行することにより、そのセッションでキャッシュするプロシージャ数を変更できます。
SET CACHED_PROCEDURES の対となるステートメントは SET PROCEDURES_CACHE です。
• 両方の SET ステートメントをゼロに設定すると、データベース エンジンはストアド プロシージャをキャッシュしません。さらに、エンジンはストアド プロシージャに使用される既存のキャッシュを削除します。つまり、エンジンは、両方のステートメントをゼロに設定する前にキャッシュされたすべてのストアド プロシージャをキャッシュから消去します。
• 一方のステートメントだけをゼロまたはゼロ以外の値に設定した場合、もう一方のステートメントは暗黙的にゼロに設定されます。暗黙的にゼロに設定されたステートメントは無視されます。たとえば、70 プロシージャをキャッシュすることのみに関心があり、メモリの量に関心がなければ、CACHED_PROCEDURES を 70 に設定します。データベース エンジンは暗黙的に PROCEDURES_CACHE をゼロに設定します。つまり、設定を無視します。
CACHED_PROCEDURES をゼロ以外の値に設定すると、以下の条件が適用されます。プロシージャの実行によって、キャッシュされたプロシージャ数が CACHED_PROCEDURES 値を超える場合、データベース エンジンは、最近最も使用頻度の低いプロシージャをキャッシュから削除します。
メモリ キャッシュを使用している場合、プロシージャの実行後もコンパイルしたストアド プロシージャを保持しています。一般的に、キャッシングによって、キャッシュされたプロシージャの次回からの呼び出しのパフォーマンスが向上します。キャッシュの設定やアプリケーションが実行する SQL によっては、過度のメモリ スワッピングやスラッシングが発生するので注意してください。スラッシングはパフォーマンスの低下を招きます。
レジストリ設定
キャッシュするプロシージャ数は、SET ステートメントのほかにレジストリ設定でも指定できます。レジストリ設定はすべてのセッションに適用され、初期値を設定する便利な方法です。各セッションは SET ステートメントを使用して、そのセッション固有の値を指定できます。この値はレジストリ設定より優先されます。
レジストリ設定は、Zen Enterprise Server または Cloud Server がサポートされるすべてのサーバー プラットフォームに適用されます。レジストリ設定は手作業で変更する必要があります。Windows では、オペレーティング システムで提供されているレジストリ エディターを使用します。Linux では、psregedit ユーティリティを使用することができます。
レジストリ設定が指定されていない場合、データベース エンジンはデフォルトを自動的に 50 とします。
キャッシュされるプロシージャ数のレジストリ設定を Windows で指定するには
1. 以下のキーを見つけます。
HKEY_LOCAL_MACHINE\SOFTWARE\Actian\Zen\SQL Relational Engine
メモ:ほとんどの Windows システムで、このキーの場所は HKEY_LOCAL_MACHINE\SOFTWARE\Actian\Zen です。ただし、HKEY_LOCAL_MACHINE\SOFTWARE の下位以降の場所はオペレーティング システムによって異なる可能性があります。
2. このキーに、CachedProcedures という新しい文字列値を作成します。
3. CachedProcedures をキャッシュしたいプロシージャ数に設定します。
Linux の Zen レジストリでキャッシュ プロシージャ レジストリ キーを設定するには
1. 以下のキーを見つけます。
PS_HKEY_CONFIG\SOFTWARE\Actian\Zen\SQL Relational Engine
2. このキーに、CachedProcedures という新しい文字列値を作成します。
3. CachedProcedures をキャッシュしたいプロシージャ数に設定します。
キャッシングの除外
ストアド プロシージャは以下の条件に当てはまる場合、キャッシュ設定にかかわらず、キャッシュされません。
• ストアド プロシージャが、ローカルまたはグローバル テンポラリ テーブルを参照する。ローカル テンポラリ テーブルはポンド記号(#)で始まる名前を持ちます。グローバル テンポラリ テーブルは 2 つのポンド記号(##)で始まる名前を持ちます。CREATE (テンポラリ) TABLE を参照してください。
• ストアド プロシージャにデータ定義言語(DDL)ステートメントが含まれている。データ定義ステートメントを参照してください。
• ストアド プロシージャに、文字列または文字列を返す式を実行するための EXEC[UTE] ステートメントが含まれている。たとえば、次のような例です。EXEC ('SELECT Student_ID FROM ' + :myinputvar)
例
次の例は、最大 20 のストアド プロシージャを格納する 2 MB のキャッシュ メモリを設定します。
SET CACHED_PROCEDURES = 20
SET PROCEDURES_CACHE = 2
————————
次の例は、最大 500 のストアド プロシージャを格納する 1,000 MB のキャッシュ メモリを設定します。
SET CACHED_PROCEDURES = 500
SET PROCEDURES_CACHE = 1000
————————
次の例は、ストアド プロシージャをキャッシュせず、既にキャッシュされているプロシージャを削除する指定をします。
SET CACHED_PROCEDURES = 0
SET PROCEDURES_CACHE = 0
————————
次の例は、120 個のストアド プロシージャをキャッシュし、キャッシュで使用するメモリ量は設定しない指定をします。
SET CACHED_PROCEDURES = 120
データベース エンジンは暗黙的に PROCEDURES_CACHE をゼロに設定します。
関連項目
SET DECIMALSEPARATORCOMMA
Zen データベース エンジンは、デフォルトでピリオド(.)を整数部と小数部の間の区切り文字として使い、小数値データを表示します(たとえば、100.95)。SET DECIMALSEPARATORCOMMA ステートメントを使用すれば、整数部と小数部をカンマで区切って結果を表示するよう指定することができます(たとえば、100,95)。
すべての SET ステートメントと同様に、このステートメントの効果は現在のデータベース セッションの間中、または別の SET DECIMALSEPARATORCOMMA ステートメントが発行されるまで適用されます。
構文
SET DECIMALSEPARATORCOMMA = < ON | OFF >
備考
デフォルト値は OFF です。これは、ピリオドをデフォルトの小数点の記号として使用します。
カンマを小数点の記号として使用する地域では、カンマまたはピリオドを区切り文字として使用して小数値データを入力することができます(カンマを区切り文字として使用したリテラル値は、'123,43' などのように一重引用符で囲む必要があります)。ただし、(SELECT ステートメントの結果のように)データが返される場合、SET DECIMALSEPARATORCOMMA=ON が指定されていなければ、データは常にピリオドを使って表示されます。
また、小数点の記号にピリオドを使って入力したデータがデータベースに含まれる場合、このステートメントを使用して出力と表示でカンマを区切り文字にするよう指定することができます。
このカンマは出力と表示にのみ影響します。挿入、更新あるいは比較で使用する値にはまったく影響しません。
例
次の例では、ピリオドで区切られたデータの挿入方法と、SET DECIMALSEPARATORCOMMA ステートメントが SELECT の結果にどのように影響するかを示します。
CREATE TABLE t1 (c1 real, c2 real)
INSERT INTO t1 VALUES (102.34, 95.234)
SELECT * FROM t1
結果:
c1 c2
------- -------
102,34 95.234
SET DECIMALSEPARATORCOMMA=ON
SELECT * FROM t1
結果:
c1 c2
------- -------
102,34 95,234
————————
次の例では、カンマで区切られたデータの挿入方法と、SET DECIMALSEPARATORCOMMA ステートメントが SELECT の結果にどのように影響するかを示します。
メモ: カンマを区切り文字として使用できるのは、クライアントとサーバーの両方またはどちらか一方のオペレーティング システムの地域の設定がカンマを区切り文字として使用するロケールに設定されている場合のみです。たとえば、クライアントとサーバーの両方で U.S. のロケール設定をしていた場合、次の例を実行しようとするとエラーになります。
CREATE TABLE t1 (c1 real, c2 real)
INSERT INTO t1 VALUES ('102,34', '95,234')
SELECT * FROM t1
結果:
c1 c2
------- -------
102,34 95.234
SET DECIMALSEPARATORCOMMA=ON
SELECT * FROM t1
結果:
c1 c2
------- -------
102,34 95,234
関連項目
SET DEFAULTCOLLATE
SET DEFAULTCOLLATE ステートメントは、CHAR、VARCHAR、LONGVARCHAR、NCHAR、NVARCHAR、または NLONGVARCHAR データ型のすべての列に使用する照合順序を指定します。ステートメントには次のオプションがあります。
• ヌル値。現在のコード ページの数値順をデフォルトとします
• オルタネート コレーティング シーケンス(ACS)規則を含んでいるファイルへのパス
• インターナショナル ソート規則(ISR)テーブル名
• ICU(International Components for Unicode)照合順序名
構文
SET DEFAULTCOLLATE = < NULL | 'ソート順' >
ソート順 ::= ACS ファイルのパス名、ISR テーブルの名前、またはサポートされる ICU 照合順序名
備考
SET DEFAULTCOLLATE ステートメントは、便利なグローバル セッション設定を提供します。しかし、個々の列定義で COLLATE キーワードを使用すれば、その列特定の照合順序を設定できます。そうした場合、SET DEFAULTCOLLATE はその列には影響しません。
DEFAULTCOLLATE のデフォルト設定はヌルです。
ACS ファイルの使用
ソート順パラメーターとして ACS ファイルを指定した場合は、次のステートメントが適用されます。
• 呼び出し元アプリケーションではなく、データベース エンジンからアクセス可能なパスを指定する必要があります。
• パスは一重引用符で囲む必要があります。
• パスは、少なくとも 1 文字以上 255 文字以下でなければなりません。
• パスは既に存在しており、ACS ファイルの名前を含んでいる必要があります。ACS ファイルは、MicroKernel エンジンで使用される形式の 265 バイト イメージです。Zen はデフォルトで、よく使われる ACS ファイル upper.alt を C:\ProgramData\Actian\Zen\samples にインストールします。カスタム ファイルを使用することもできます。カスタム ファイルの詳細については、『Zen Programmer's Guide』のユーザー定義 ACS を参照してください。
• DDF ディレクトリに対して相対的である、相対パスを使用できます。相対パスには、1 つのピリオド(現在のディレクトリ)、2 つのピリオド(親ディレクトリ)、円記号、あるいはこれら 3 つのあらゆる組み合わせを含めることができます。相対パスの円記号は、スラッシュ(/)と円記号(\)のどちらでも使用できます。同じパス内に円記号とスラッシュ文字を混在させることもできます。
• UNC(Universal Naming Convention)のパス名を使用できます。
ISR テーブル名の使用
ソート順パラメーターとして ISR テーブル名を指定した場合は、次のステートメントが適用されます。
• Zen は、本ドキュメントのインターナショナル ソート規則に挙げられているテーブル名をサポートしています。
• ISR テーブル名はファイルの名前ではなく、Zen でサポートする ISR の 1 つとして認識される文字列です。
• Zen は、ICU(International Components for Unicode)に基づいて、選択された Unicode 照合順序をサポートしています。単に、ISR テーブル名の代わりに ICU 照合順序名を使用するだけです。使用可能な照合順序は、ICU Unicode 照合順序を使用した照合順序のサポートに記載されています。
ACS、ISR、および ICU の例
この ACS の例では、Zen で提供される upper.alt ファイルを使用して照合順序を設定します。テーブル t1 は、3 つのテキスト列と 3 つのテキスト以外の列で作成されます。SELECT ステートメントを Zen のシステム テーブルに対して実行し、t1 内の列の ID、データ型、サイズ、および属性を返します。結果は、3 つのテキスト列が UPPER 属性を持っていることを示しています。
SET DEFAULTCOLLATE = 'C:\ProgramData\Actian\Zen\samples\upper.alt'
DROP TABLE t1
CREATE TABLE t1 (c1 INT, c2 CHAR(10), c3 BINARY(10), c4 VARCHAR(10), c5 LONGVARBINARY, c6 LONGVARCHAR)
SELECT * FROM x$attrib WHERE xa$id in (SELECT xe$id FROM x$field WHERE xe$file = (SELECT xf$id FROM x$file WHERE xf$name = 't1'))
Xa$Id Xa$Type Xa$ASize Xa$Attrs
===== ======= ======== ========
327 O 265 UPPER
329 O 265 UPPER
331 O 265 UPPER
3 行が影響を受けました。
————————
次の ACS の例でもテーブル t1 を引き続き使用します。ALTER TABLE ステートメントによって、テキスト列 c2 を CHAR から INTEGER に変更します。SELECT ステートメントの結果は、2 列だけがデフォルトの照合順序の影響を受けていることを示しています。
ALTER TABLE t1 ALTER c2 INT
SELECT * FROM x$attrib WHERE xa$id in (SELECT xe$id FROM x$field WHERE xe$file = (SELECT xf$id FROM x$file WHERE xf$name = 't1'))
Xa$Id Xa$Type Xa$ASize Xa$Attrs
===== ======= ======== ========
329 O 265 UPPER
331 O 265 UPPER
2 行が影響を受けました。
————————
次の ACS の例では、ALTER TABLE ステートメントを使用して、テーブル t1 の列 c1 を INTEGER から CHAR に変更します。SELECT ステートメントの結果は、3 列がデフォルトの照合順序の影響を受けていることを示しています。
ALTER TABLE t1 ALTER c1 CHAR(10)
SELECT * FROM x$attrib WHERE xa$id in (SELECT xe$id FROM x$field WHERE xe$file = (SELECT xf$id FROM x$file WHERE xf$name = 't1'))
Xa$Id Xa$Type Xa$ASize Xa$Attrs
===== ======= ======== ========
326 O 265 UPPER
329 O 265 UPPER
331 O 265 UPPER
3 行が影響を受けました。
————————
次の ISR の例では、VARCHAR 列を持つテーブルを作成し、デフォルトの Windows エンコード CP1252 であるとして、ISR 照合順序 MSFT_ENUS01252_0 を使用します。
CREATE TABLE isrtest (ord INT, value VARCHAR(19) COLLATE 'MSFT_ENUS01252_0' NOT NULL, PRIMARY KEY(value));
次の ICU の例では、VARCHAR 列を持つテーブルを作成し、デフォルトの Linux エンコード UTF-8 であるとして、ICU 照合順序 u54-msft_enus_0 を使用します。
CREATE TABLE isrtest (ord INT, value VARCHAR(19) COLLATE 'u54-msft_enus_0' NOT NULL, PRIMARY KEY(value));
次の ICU の例は、NVARCHAR 列を持ち、ICU 照合順序 u54-msft_enus_0 を使用するテーブルを作成します。
CREATE TABLE isrtest (ord INT, value NVARCHAR(19) COLLATE 'u54-msft_enus_0' NOT NULL, PRIMARY KEY(value));
関連項目
『Advanced Operations Guide』の照合順序と並べ替えのサポート
SET LEGACYTYPESALLOWED
SET LEGACYTYPESALLOWED ステートメントにより、本リリースの Zen ではサポートされなくなったデータ型との下位互換性を有効にすることができます。
構文
SET LEGACYTYPESALLOWED = < ON | OFF >
備考
SET LEGACYTYPESALLOWED ステートメントは SQL セッションで CREATE TABLE や ALTER TABLE ステートメントより先に実行され、以前のリリースの Zen でサポートされた旧データ型をこれらのステートメントで使用できるようにします。
デフォルト値は OFF です。これは、旧データ型がサポートされないことを意味します。
詳細については、旧データ型を参照してください。
例
次の例では、CREATE TABLE ステートメントの前に LEGACYTYPESALLOWED をオンにして旧データ型が機能するようにし、テーブルの作成後、再びオフに戻しています。
SET LEGACYTYPESALLOWED=ON;
CREATE TABLE notes (c1 INTEGER, c2 NOTE(20));
SET LEGACYTYPESALLOWED=OFF;
メモ: 設定をオフにしなかった場合は、すべての SET コマンドと同様、その適用は SQL セッションで終わります。
SET OWNER
SET OWNER ステートメントは、現在のデータベース セッションで SQL コマンドがアクセスするファイルのオーナー ネームをリストアップします。このファイル レベルのセキュリティ機能の詳細については、オーナー ネームを参照してください。
構文
SET OWNER = [']オーナー ネーム['] [ , [']オーナー ネーム['] ]...
備考
SET OWNER ステートメントでは、アルファベット以外の文字で始まるオーナー ネーム、およびスペースを含んでいる ASCII 形式のオーナー ネームは一重引用符で囲む必要があります。16 進数の長いオーナー ネームは 0x または 0X で始まるため、常に一重引用符が必要です。
SET OWNER ステートメントは、セッション内のデータ ファイルに必要とされるオーナー ネームの一覧を作成できます。リレーショナル エンジンは、オーナー ネームをキャッシュしておき、MicroKernel エンジンからのファイル アクセス要求の必要に応じて使用します。
SET OWNER ステートメントは、現在の接続セッションでのみ有効です。ユーザーは、SET OWNER を発行後にログアウトした場合、次回のログイン時にこのコマンドを再発行する必要があります。
SET OWNER ステートメントごとに、セッションの現在のオーナー ネーム リストはリセットされます。追加のステートメントにより、リストにオーナー ネームを追加することはできません。
セキュリティが無効になっているデータベースでは、SET OWNER ステートメントにより、このステートメントで指定したオーナー ネームと一致するオーナー ネームを持つすべてのデータ ファイルへのフル アクセスが許可されるようになります。
セキュリティが有効になっているデータベースでは、SET OWNER ステートメントは Master ユーザー以外のユーザーには何の影響もありません。Master ユーザーが自身に権限を付与していない場合は、SET OWNER を実行することにより、指定したオーナー ネームのいずれかを持つすべてのデータ ファイルへのフル アクセスが Master ユーザーに与えられます。Master ユーザーは、他のユーザーについて、次の 2 つの方法のいずれかでアクセス権限を付与することができます。
• SET OWNER でオーナー ネームを指定し、続けて GRANT をオーナー ネームを指定しないで実行します。
• GRANT をオーナー ネームを指定して実行します。
これら 2 つのオプションについて、以下の例で説明します。
例
次の例では、オーナー ネームは数字で始まっているため、一重引用符で囲まれています。
SET OWNER = '1@lphaOm3gA'
————————
次の例は、現在のセッションでアクセスするファイルによって使用されるオーナー ネームのリストを提供しています。
SET OWNER = 'serverl7 region5', '0x7374726f6e672050617373776f7264212425fe'
一重引用符が使用されている理由は、ASCII 文字列の場合はスペースが含まれているためであり、16 進数文字列の場合はプレフィックスの 0x が数字で始まっているためです。
————————
データベース セッション中、各 SET OWNER ステートメントは前の同ステートメントをオーバーライドします。次の例では、2 番目のコマンドを実行した後、最初の 3 つのオーナー ネームはファイル アクセスに使用できなくなります。
SET OWNER = judyann, krishna1, maxima
SET OWNER = d3ltagamm@, V3rs10nXIII, m@X1mumSp33d
————————
次の例は、Master ユーザーがセキュリティで保護されたデータベースで SET OWNER を使用する方法を示します。セキュリティは有効になっていますが、ユーザーには何の権限も付与されていません。inventory1 というデータ ファイルはオーナー ネーム admin を持ちます。
Master ユーザーが自身に権限を付与する場合には、2 つのオプションがあります。1 つ目のオプションでは、SET OWNER を発行した後、GRANT をオーナー ネームなしで発行できます。
SET OWNER = admin
GRANT ALL ON inventory1 TO MASTER
2 つ目のオプションでは、Master ユーザーは SET OWNER ステートメントを省略し、オーナー ネームを指定した GRANT を発行できます。
GRANT ALL ON inventory1 admin TO MASTER
どちらの方法も同じ結果になります。
関連項目
SET PASSWORD
SET PASSWORD ステートメントは、セキュリティで保護されたデータベースに対して次の機能を提供します。
• Master ユーザーは、Master ユーザーまたはそれ以外のユーザーのパスワードを変更できます。
• 通常のユーザー(Master 以外のユーザー)は、データベースへのログオン パスワードを変更できます。
構文
SET PASSWORD [ FOR 'ユーザー名' ] = パスワード
ユーザー名 ::= データベースにログオンしているか、またはデータベースへのログオンを許可されているユーザーの名前
パスワード ::= パスワード文字列
備考
SET PASSWORD は、データベースでリレーショナル セキュリティが有効になっていることを必要とし、いつ発行してもかまいません対照的に、SET SECURITY は、Master ユーザーのセッションが現在の唯一のデータベース接続である場合にのみ発行されます。SET SECURITY を参照してください。
SET PASSWORD は、Master ユーザーでも Master 以外の通常のユーザーでも発行できます。Master ユーザーは、データベースへのログインを許可されているすべてのユーザーのパスワードを変更できます。通常のユーザーは自身のパスワードしか変更できません。パスワードの変更は、ユーザーが次回ログインしたときに有効になります。
SET PASSWORD ステートメントを発行するユーザー | FOR 句付き | FOR 句なし |
|---|---|---|
Master | Master は、Master またはデータベースへのログオンを許可されているすべてのユーザーのユーザー名を指定できます。1 ユーザー名のパスワードが変更されます。 | データベース全体のパスワードが変更されます(つまり、データベース全体に影響を与える、Master ユーザーのパスワードが変更されます)。 |
通常 | 通常のユーザーは、ユーザー名を指定できます。ユーザーはデータベースにログインしている必要があります。 当該ユーザーのパスワードのみ変更されます。 | SET PASSWORD ステートメントを発行したユーザーのパスワードのみが変更されます。ユーザーはデータベースにログオンしている必要があります。 |
1ユーザー名は、Zen データベースにログオン可能なユーザーです。オペレーティング システムのユーザー名とは異なる場合があります。たとえば、ユーザー名 Yogine はオペレーティング システムにログオンできます。データベース Demodata でセキュリティが有効になっており、Yogine がユーザー名 DeptMgr(Demodata にログオンするユーザー名)として追加されています。 | ||
パスワードの特性
• パスワードでは大文字小文字が区別されます。パスワードがアルファベット以外の文字で始まる場合は、パスワードを一重引用符で囲む必要があります。
• 先頭文字以外であれば、空白文字をパスワードで使用することができます。パスワードに空白文字が含まれる場合は、パスワードを一重引用符で囲む必要があります。原則として、パスワードに空白文字を使用することは避けてください。
• "Password" は予約語ではありません。これは、テーブルまたは列の名前として使用することができます。ただし、SQL ステートメント内でテーブル名または列名として使用する場合は、"password" はキーワードであるため、二重引用符で囲む必要があります。
• リテラルの "null" をパスワードとして使用する場合は、単語を一重引用符で囲む必要があります('null')。文字列を引用符で囲むことによって、データベースのセキュリティを無効にするための SET SECURITY = NULL ステートメントとの混乱を防ぎます。
例
次の例では以下のことを示します。Master ユーザーは、パスワード bluesky を使ってデータベースのセキュリティを有効にします。次に、Master ユーザーは user45 というユーザーにログオン権限を与えてパスワードを tmppword と指定し、そのユーザーにテーブル person の SELECT 権限を与えます。その後で、Master ユーザーは Master のパスワードを reddawn に変更することで、データベース全体に対するパスワードを変更します。最後に、user45 のパスワードを newuser に変更します。
SET SECURITY = bluesky
GRANT LOGIN TO user45:tmppword
GRANT SELECT ON person TO user45
SET PASSWORD = reddawn
SET PASSWORD FOR user45 = newuser
次の例では、user45 はパスワード newuser でデータベースにログオンしているものとします。user45 は自分のパスワードを tomato に変更し、その後、person テーブル内のすべてのレコードを選択しています。
SET PASSWORD FOR user45 = tomato
SELECT * FROM person
関連項目
SET PROCEDURES_CACHE
SET PROCEDURES_CACHE ステートメントは、データベースエンジンがストアド プロシージャのキャッシュとして予約する SQL セッションのメモリ量を指定します。
構文
SET PROCEDURES_CACHE = メモリ量(メガバイト)
備考
メモリ量(メガバイト)の値は、ゼロからおよそ 20 億までの整数です。データベース エンジンは、デフォルトで 5 MB に設定します。各セッションは、この SET ステートメントを発行することにより、そのセッションのキャッシュ メモリ量を変更できます。
SET PROCEDURES_CACHE の対となるステートメントは SET CACHED_PROCEDURES です。
• これら両方の SET ステートメントをゼロに設定すると、データベース エンジンはストアド プロシージャをキャッシュしません。さらに、エンジンはストアド プロシージャに使用される既存のキャッシュを削除します。つまり、エンジンは、両方のステートメントをゼロに設定する前にキャッシュされたすべてのストアド プロシージャをキャッシュから消去します。
• 一方のステートメントだけをゼロまたはゼロ以外の値に設定した場合、もう一方のステートメントは暗黙的にゼロに設定されます。暗黙的にゼロに設定されたステートメントは無視されます。たとえば、キャッシュ メモリとして 30 MB を使用することのみに関心があり、キャッシュされるプロシージャ数に関心がなければ、PROCEDURES_CACHE を 30 に設定します。データベース エンジンは暗黙的に CACHED_PROCEDURES をゼロに設定します。つまり、設定を無視します。
PROCEDURES_CACHE をゼロ以外の値に設定すると、以下の条件が適用されます。プロシージャの実行によって割り当てられたメモリが PROCEDURES_CACHE 値を超える場合、データベース エンジンは最近最も使用頻度の低いプロシージャをキャッシュから削除します。
メモリ キャッシュを使用している場合、プロシージャの実行後もコンパイルしたストアド プロシージャを保持しています。一般的に、キャッシングによって、キャッシュされたプロシージャへの以降の呼び出しのパフォーマンスが向上します。キャッシュの設定やアプリケーションで実行される SQL ステートメントによっては、過度のメモリ スワッピングやスラッシングが発生する可能性があるので注意してください。スラッシングはパフォーマンスを低下させる可能性があります。
レジストリ設定
キャッシュ用の予約メモリ量は、SET ステートメントのほかにレジストリ設定でも指定できます。レジストリ設定はすべてのセッションに適用され、初期値を設定する便利な方法です。各セッションは SET ステートメントを使用して、そのセッション固有の値を指定できます。この値はレジストリ設定より優先されます。
レジストリ設定は、Zen Enterprise Server または Cloud Server がサポートされるすべてのサーバー プラットフォームに適用されます。レジストリ設定は手作業で変更する必要があります。Windows では、オペレーティング システムで提供されているレジストリ エディターを使用します。Linux では、psregedit ユーティリティを使用することができます。
レジストリ設定が指定されていない場合、データベース エンジンはデフォルトを自動的に 5 MB とします。
Windows のレジストリ設定でキャッシュ メモリ量を指定するには
1. 以下のキーを見つけます。
HKEY_LOCAL_MACHINE\SOFTWARE\Actian\Zen\SQL Relational Engine
メモ:ほとんどの Windows システムで、このキーの場所は HKEY_LOCAL_MACHINE\SOFTWARE\Actian\Zen です。ただし、HKEY_LOCAL_MACHINE\SOFTWARE の下位以降の場所はオペレーティング システムによって異なる可能性があります。
2. このキーに、ProceduresCache という新しい文字列値を作成します。
3. ProceduresCache にキャッシュに使用したいメモリ量を設定します。
Linux の Zen レジストリでキャッシュ メモリの量を設定するには
1. 以下のキーを見つけます。
PS_HKEY_CONFIG\SOFTWARE\Actian\Zen\SQL Relational Engine
2. このキーに、ProceduresCache という新しい文字列値を作成します。
3. ProceduresCache にキャッシュに使用したいメモリ量を設定します。
キャッシングの除外
ストアド プロシージャは、以下の条件に当てはまる場合、キャッシュ設定にかかわらず、キャッシュされません。
• ストアド プロシージャが、ローカルまたはグローバル テンポラリ テーブルを参照する。ローカル テンポラリ テーブルはポンド記号(#)で始まる名前を持ちます。グローバル テンポラリ テーブルは 2 つのポンド記号(##)で始まる名前を持ちます。CREATE (テンポラリ) TABLE を参照してください。
• ストアド プロシージャにデータ定義言語(DDL)ステートメントが含まれている。データ定義ステートメントを参照してください。
• ストアド プロシージャに、文字列または文字列を返す式を実行するための EXEC[UTE] ステートメントが含まれている。たとえば、次のような例です。EXEC ('SELECT Student_ID FROM ' + :myinputvar)
例
次の例は、最大 20 のストアド プロシージャを格納する 2 MB のキャッシュ メモリを設定します。
SET CACHED_PROCEDURES = 20
SET PROCEDURES_CACHE = 2
————————
次の例は、最大 500 のストアド プロシージャを格納する 1,000 MB のキャッシュ メモリを設定します。
SET CACHED_PROCEDURES = 500
SET PROCEDURES_CACHE = 1000
————————
次の例は、ストアド プロシージャをキャッシュせず、既にキャッシュされているプロシージャを削除する指定をします。
SET CACHED_PROCEDURES = 0
SET PROCEDURES_CACHE = 0
————————
次の例では、キャッシュ メモリを 80 MB に設定し、キャッシュされるプロシージャ数は設定しない指定をします。
SET PROCEDURES_CACHE = 80
データベース エンジンは暗黙的に CACHED_PROCEDURES をゼロに設定します。
関連項目
SET ROWCOUNT
SET ROWCOUNT キーワードを使用することによって、現在のセッション内にある後続のすべての SELECT ステートメントから返される行数を制限することができます。
SET ROWCOUNT と TOP または LIMIT の主な違いは、TOP が現在のステートメントにのみ作用するのに対し、SET ROWCOUNT は(次の SET ROWCOUNT またはセッションが終了するまでの)現在のデータベース セッション中に発行される後続のステートメントすべてに作用する点です。
構文
SET ROWCOUNT = 行数
備考
SET ROWCOUNT を条件とする SELECT ステートメントに ORDER BY キーワードが含まれており、その ORDER BY 句での最適化にインデックスを使用できない場合、Zen はテンポラリ テーブルを生成します。テンポラリ テーブルにはクエリの結果セット全体が置かれます。テンポラリ テーブル内の行は ORDER BY 値で指定した順序で並べられ、その順序付けされた結果セットから ROWCOUNT の n 行を返します。
ROWCOUNT をゼロに設定して ROWCOUNT 機能を無効にすることができます。
SET ROWCOUNT = 0
SET ROWCOUNT は動的カーソルを使用するときには無視されます。
SET ROWCOUNT と TOP の両方をクエリに適用した場合、2 つの値のうち小さい方の値に等しい行数を返します。
例
TOP または LIMIT の例も参照してください。
SET ROWCOUNT = 10;
SELECT * FROM person;
-- 10 行を返します
関連項目
SET SECURITY
SET SECURITY ステートメントを使用すると、Master ユーザーはログオンしているデータベースのセキュリティを有効または無効にできます。
構文
SET SECURITY [ USING 認証の種類 ] = < 'パスワード' | NULL >
備考
セキュリティを設定するには、まず Master としてログオンする必要があります。その後、SET SECURITY ステートメントを使用してパスワードを割り当てることができます。セキュリティで保護されていないデータベースにログオンする場合、Master はパスワードを要求されません。しかし、データベースにセキュリティを設定する場合は、Master ユーザーは割り当てられたパスワードが必要になります。
SET SECURITY は、Master ユーザーのセッションが現在の唯一のデータベース接続である場合のみ発行できます。セキュリティは Zen Control Center(ZenCC)から設定することもできます。『Zen User's Guide』の Zen エクスプローラーを使用してセキュリティを有効にするにはを参照してください。
認証の種類の文字列は、local_db または domain です。USING 句が含まれていない場合、認証の種類は local_db に設定されます。
認証の種類が domain の場合に、ユーザーに関する SQL スクリプトを実行すると、エラー メッセージ(ステートメントがドメイン認証でサポートされていない)を返します。サポートされないステートメントは、ユーザー関連の ALTER USER、CREATE USER、DROP USER、GRANT や、非 Master ユーザー向けの SET PASSWORD、および REVOKE などです。
パスワード要件については、パスワードの特性を参照してください。
ユーザー権限
オブジェクト(テーブル、ビュー、およびストアド プロシージャなど)の権限は、SET SECURITY が NULL に設定された後もシステム テーブルに保持されます。次のシナリオを考えてみましょう。
• データベース mydbase のセキュリティを有効にし、ユーザー Master がログインします。
• Master が、ユーザー user1 と user2、およびデータベース mydbase のテーブル t1 を作成します。
• Master が user2 に t1 の SELECT 権限を付与します。
• mydbase のセキュリティを無効にします。
• テーブル t1 を削除します。
テーブル t1 が存在しなくなっても、t1 の権限はシステム テーブル内に残っています(t1 の ID は X$Rights 内にまだあります)。以下について考えてみましょう。
• データベース mydbase のセキュリティを再び有効にします。
• user1 がデータベースにログインします。
• user1 が mydbase の新しいテーブル tbl1 を作成します。tbl1 には、t1 に割り当てられたオブジェクト ID と同じ ID を割り当てることができます。このシナリオでは、t1 と tbl1 に割り当てられるオブジェクト ID を同じにします。
• t1 の以前の権限が tbl1 に復元されます。つまり、user1 は、新しいテーブルに対する権限を明示的に付与されていなくても、tbl1 の SELECT 権限を持っているということです。
メモ: オブジェクトに対する権限を削除したい場合は、明示的にその権限を取り消す必要があります。このことは、テーブル、ビュー、およびストアド プロシージャに当てはまります。権限はオブジェクト ID と関連付けられており、データベースは新しいオブジェクトに対し、削除されたオブジェクトのオブジェクト ID を再使用するからです。
例
次の例では、データベースのセキュリティを有効にし、Master パスワードを "mypasswd" と設定しています。
SET SECURITY = 'mypasswd'
次の例では、データベースのドメイン認証を有効にし、Master パスワードを "123456" と設定しています。
SET SECURITY USING domain = '123456'
————————
次の例ではセキュリティが無効になります。
SET SECURITY = NULL
関連項目
SET TIME ZONE
SET TIME ZONE キーワードを使用すると、ロケールの世界協定時刻(Coordinated Universal Time:UTC)を基に現在時刻のオフセットを指定することができ、これによって、データベース エンジンが配置されているオペレーティング システムのタイム ゾーンの設定を無効にできます。
SET TIME ZONE ステートメントの効果は現在のデータベース セッションの間中、または別の SET TIME ZONE ステートメントが実行されるまで適用されます。
注意! お使いのオペレーティング システムのタイム ゾーンの設定を特に無効にする必要がなければ、常にデフォルトの動作を使用してください。DataExchange レプリケーションを使用している場合、またはアプリケーションに各レコードが挿入される時刻順序との依存関係がある場合は、SET TIME ZONE を使ってタイム ゾーンのオフセットを変更することはお勧めしません。
構文
SET TIME ZONE < オフセット | LOCAL >
オフセット ::= <+|->hh:mm
hh の有効な範囲は 00 ~ 12 です。
mm の有効な範囲は 00 ~ 59 です。
プラス記号(+)またはマイナス記号(-)は、オフセット値の一部として必要です。
備考
デフォルトの動作 - SET TIME ZONE LOCAL がデフォルトの動作で、これは SET TIME ZONE コマンドをまったく使用しないのと同じです。デフォルトの動作の場合、データベース エンジンは実行しているオペレーティング システムに基づいてそのタイム ゾーンを設定します。たとえば、SELECT CURTIME() では現在の現地時刻を返しますが、SELECT CURRENT_TIME() では、オペレーティング システムの地域のシステム時刻とタイム ゾーンの設定の両方に基づいて現在の世界協定時刻(UTC)を返します。
LOCAL キーワードを使用すると、オフセット値を指定した後、データベース セッションを終了して再度開かなくても、デフォルトの動作に戻すことができます。
デフォルトの動作の場合、1996-03-28 や 17:40:46 などの日付/時刻のリテラル値は、現在の現地日付/時刻として解釈されます。また、挿入中には、タイムスタンプ リテラル値は指定した現在の現地時刻として解釈されます。タイムスタンプ値は常に UTC 時刻を使って調整されてから内部的に保存され、取得時に現地時刻に変換されます。詳細については、タイムスタンプ値を参照してください。
タイム ゾーンが指定されていない場合、または TIME ZONE LOCAL が指定されている場合 | |
|---|---|
CURDATE()、CURTIME()、NOW()、SYSDATETIME() | システム時計に基づいて現在の現地日付/時刻を返します。 |
CURRENT_DATE()、CURRENT_TIME()、CURRENT_TIMESTAMP()、SYSUTCDATETIME() | システム時計とオペレーティング システムの地域の設定に基づいて、現在の UTC 日付/時刻を返します。 |
オフセットを指定した場合の動作 有効なオフセット値が指定されると、CURDATE()、CURTIME()、NOW()、または SYSDATETIME() の値を生成する場合に、オペレーティング システムのタイム ゾーンのオフセットではなくその値を使用します。たとえば、オフセットに -02:00 を指定した場合、CURDATE() の現地時刻の値はオペレーティング システムから返される UTC 時刻に -02:00 が加算された値になります。
この動作の場合、日付と時刻のリテラルはそのままの値で現地時刻として解釈されます。タイムスタンプ リテラルでは、オフセット値を減算した場合に結果が UTC となるような時刻を指定しているものと解釈されます。夏時刻はオフセットで明示的に設定するので、考慮しません。タイムスタンプ値は常に UTC 時刻を使って内部的に保存されます。
有効なオフセット値が指定された場合 | |
|---|---|
CURDATE()、CURTIME()、NOW()、SYSDATETIME() | これらの関数は、現在の UTC 日付/時刻値にオフセットを加算して現在の現地日付/時刻値を返します。 |
CURRENT_DATE()、CURRENT_TIME()、CURRENT_TIMESTAMP()、SYSUTCDATETIME() | これらの関数は、常にシステム時計とオペレーティング システムの地域の設定に基づいて現在の UTC 日付/時刻を返します。 |
指定した現地時刻値を UTC に変換するには、その現地時刻の値からタイム ゾーンのオフセット値を減算する必要があります。つまり次のようになります。
UTC 時刻 = 現地時刻 - タイム ゾーンのオフセット
この表は、変換の例を示しています。
現地時刻 | オフセット | UTC |
|---|---|---|
10:10:15 オースチン | US 中部標準時 -06:00 | 10:10:15-(-06:00)=16:10:15 UTC |
16:10:15 ロンドン | グリニッジ標準時 +00:00 | 16:10:15-(+00:00)=16:10:15 UTC |
22:10:15 ダッカ | +06:00 | 22:10:15-(+06:00)=16:10:15 UTC |
タイムスタンプ データ型に関する注記
タイムスタンプ データは常に UTC として保存され、リテラル タイムスタンプ値はディスクに保存されている値も含め、取得するときに常に現地時刻へ変換されるため、NOW() 値と CURRENT_TIMESTAMP() 値の動作は混乱を招く可能性があります。たとえば、次の表ではデータベース エンジンが U.S. 中部標準時に設定されているとします。
ステートメント | 値 |
|---|---|
SELECT NOW() | 2001-10-01 12:05:00.123 が表示されます。 |
INSERT INTO t1 (c1) SELECT NOW() | 2001-10-01 18:05:00.1234567 がディスクに保存されます。 |
SELECT * from t1 | 2001-10-01 12:05:00.123 が表示されます。 |
SELECT CURRENT_TIMESTAMP() | 2001-10-01 18:05:00.123 が表示されます。 |
INSERT INTO t2 (c1) SELECT CURRENT_TIMESTAMP() | 2001-10-01 18:05:00.1234567 がディスクに保存されます。 |
SELECT * from t2 | 2001-10-01 12:05:00.123 が表示されます。 |
直接の SELECT NOW() で表示される値は、INSERT SELECT NOW() 構文によってディスクに保存される値とは異なることに注意することが重要です。また、SELECT CURRENT_TIMESTAMP() の表示値も、CURRENT_TIMESTAMP() の値を INSERT した後でそれを SELECT した場合(INSERT SELECT CURRENT_TIMESTAMP() 構文)に表示される値とは異なることに注意してください。これは、データ ファイルに保存したリテラル値を取得するときに値が調整されるからです。
例
次の例では、SET TIME ZONE ステートメントがまだ発行されておらず、データベース エンジンが起動しているシステムのシステム時計は January 9, 2002, 16:35:03 CST(US)に設定されています。CURRENT_TIMESTAMP() およびその他の CURRENT_ 関数では、常にデータベース エンジンが起動しているシステムのシステム時計と地域の設定に基づく UTC 日付/時刻を返すことを思い出してください。
SELECT CURRENT_TIMESTAMP(), NOW(),
CURRENT_TIME(), CURTIME(),
CURRENT_DATE(), CURDATE()
結果:
2002-01-09 22:35:03.000 2002-01-09 16:35:03.000
22:35:03 16:35:03
01/09/2002 01/09/2002
CST は UTC の 6 時間前であることに注意してください。
SET TIME ZONE -10:00
これによって、上記の同じ SELECT ステートメントでは次の値を返します。
2002-01-09 22:35:03.000 2002-01-09 12:35:03.000
22:35:03 12:35:03
2002-01-09 2002-01-09
SET TIME ZONE ステートメントを発行後 NOW() の値は変わりましたが、CURRENT_TIMESTAMP() の値は変わらなかったことに注目してください。
————————
次の例では、UTC 値として保存され取得時に現地時刻の値に変換されるタイムスタンプ値と、そのままの値で保存および取得される TIME または DATE 値との違いを示します。現在、システム時計は January 9, 2002, 16:35:03 CST(U.S.)を示しているものとします。また、SET TIME ZONE ステートメントはまだ発行されていないことを前提とします。
CREATE TABLE t1 (c1 TIMESTAMP, c2 TIMESTAMP, c3 TIME, c4 TIME, c5 DATE, c6 DATE)
INSERT INTO t1 SELECT CURRENT_TIMESTAMP(), NOW(), CURRENT_TIME(), CURTIME(), CURRENT_DATE(), CURDATE()
SELECT * FROM t1
結果:
c1 c2
----------------------- -----------------------
2002-01-09 16:35:03.000 2002-01-09 16:35:03.000
c3 c4 c5 c6
-------- -------- ---------- ----------
22:35:03 16:35:03 01/09/2002 01/09/2002
NOW() と CURRENT_TIMESTAMP() は、SELECT NOW()、CURRENT_TIMESTAMP() で画面に表示される場合には異なる値になりますが、いったんリテラル値をディスクに保存すると、両方の値に UTC 時刻が格納されることに注意してください。取得時に、両方の値が現地時刻に変換されます。
タイム ゾーン オフセットをゼロに設定すると、取得時に +00:00 によって調整されるので、ファイルに保存された実際のデータを見ることができます。
SET TIME ZONE +00:00
SELECT * FROM t1
結果:
c1 c2
----------------------- -----------------------
2002-01-09 22:35:03.000 2002-01-09 22:35:03.000
c3 c4 c5 c6
-------- -------- ---------- ----------
22:35:03 16:35:03 01/09/2002 01/09/2002
————————
次の例では、現地日付が UTC 日付と異なる場合に予期される動作を示します(たとえば、UTC は午前 0 時を過ぎているが、現地時刻ではまだ午前 0 時前の場合。またはその逆の場合)。現在、システム時計は January 9, 2002, 16:35:03 CST(U.S.)を示しているものとします。
SET TIME ZONE +10:00
SELECT CURRENT_TIMESTAMP(), NOW(),
CURRENT_TIME(), CURTIME(),
CURRENT_DATE(), CURDATE()
結果:
2002-01-09 22:35:03.000 2002-01-10 08:35:03.000
22:35:03 08:35:03
01/09/2002 01/10/2002
INSERT INTO t1 SELECT CURRENT_TIMESTAMP(), NOW(), CURRENT_TIME(), CURTIME(), CURRENT_DATE(), CURDATE()
SELECT * FROM t1
結果:
c1 c2
----------------------- -----------------------
2002-01-10 08:35:03.000 2002-01-10 08:35:03.000
c3 c4 c5 c6
-------- -------- ---------- ----------
22:59:55 08:59:55 01/09/2002 01/10/2002
ご覧のとおり、CURRENT_DATE() および CURRENT_TIME() で返される UTC 時刻と日付はリテラル値として保存されます。これらはタイムスタンプ値ではないので、データベースから取得するときに調整が行われません。
関連項目
TIMESTAMP データ型
SET TRUEBITCREATE
SET TRUEBITCREATE ステートメントを使用すると、BIT データ型にインデックスを付けたり、LOGICAL トランザクショナル データ型にマップすることができます。
構文
SET TRUEBITCREATE = < ON | OFF >
備考
デフォルトは on です。これは、BIT データ型が 1 ビットで、インデックスを付けることができず、Zen 型コード 16 に割り当てられることを意味します。型コード 16 の場合、BIT をマップできる同等のトランザクショナル データ型はありません。
ほかの DBMS アプリケーションとの互換性などの一定の状況では、BIT を LOGICAL データ型にマップして BIT データ型にインデックスを付けたい場合があります。これを行うには、TRUEBITCREATE を off にします。これにより BIT は LOGICAL にマップされ、型コード 7 の 1 バイト データ型になります。
作成モードは、ステートメントを発行して変更されるか、データベース接続が切断されるまでは有効なままです。この設定は接続ごとに保持されるため、同一アプリケーション内であっても、個々のデータベース接続がそれぞれ異なる作成モードを保持することができます。どの接続も、BIT が Zen 型コード 16 で作成されるデフォルト モードの設定で開始されます。
この機能は既存の BIT には影響せず、SET ステートメントがアプリケーション適用された後に作成されたもののみに有効になります。
この設定は SQL ステートメントでのみ切り替えることができます。Zen Control Center では設定できません。Table Editor は列のリレーショナル データ型を表示することに留意してください(したがって、"BIT" 型と表示されます)。TRUEBITCREATE を off にすると、Table Editor で BIT 列にインデックスを付けることができます。
例
次のステートメントは、設定を切り替えて、新しい BIT を作成する必要があることを指定します。新しい BIT は、インデックス付けが可能で、LOGICAL トランザクショナル データ型にマップされ、型コード 7 を持ちます。
SET TRUEBITCREATE=OFF
SET TRUENULLCREATE
SET TRUENULLCREATE ステートメントにより、新規テーブルの作成時に真のヌルのオン/オフを切り替えます。
構文
SET TRUENULLCREATE = < ON | OFF >
備考
この設定が初めて登場したのは Pervasive.SQL 2000 (7.5) でした。デフォルトはオンで、これは、空のフィールドの先頭にヌル インジケーター バイトを付けてテーブルが作成されるようにします。SQL ステートメントによってこれをオフに設定すると、それ以降は、Pervasive.SQL 7 以前のリリースのレガシー ヌルを使用してテーブルが作成されます。レガシー ヌルの動作は、セッションが切断されるまで持続します。新しいセッションでは、設定は再びオンになります。
接続ごとに TRUENULLCREATE 設定を持つため、同一のアプリケーション内で他の接続と異なる設定にすることができます。
レガシー ヌルは真のヌルではありませんが、ヌル許容として動作するため、あらゆる列の型に INSERT NULL を実行できます。しかし、値を照会すると、次に示す非ヌルのバイナリ同値のいずれかが返されます。
• 0 - Binary 型の場合
• 空文字列 - STRING 型および BLOB 型(LVAR、LSTRING などのレガシー型を含む)の場合
したがって、このバイナリ同値を WHERE 句で使用して、特定の値を取得する必要があります。
次の表は、デフォルト値とヌル値を許可する列との相互作用を示しています。
列のタイプ | 列にリテラルのデフォルト値が定義されていない場合に使用するデフォルト値 | リテラル値が定義されている場合のデフォルト値 |
|---|---|---|
ヌル値を許可 | NULL | 定義どおり |
NOT NULL | エラー-"列にデフォルト値が割り当てられていません。" | 定義どおり |
v7.5 以前のヌル許容 | 列のレガシー ヌル | 定義どおり |
ステートメントで、デフォルト値が定義されている NOT NULL 列に明示的なヌルを挿入しようとすると、エラーが発生して失敗します。挿入を試みた場所でデフォルト値は使用されません。
デフォルト値が定義されている列については、INSERT ステートメントの中で、挿入する列リストからこの列を省略するか、または挿入値の場所に DEFAULT キーワードを使用することで、その値を呼び出すことができます。
テーブル内の列がすべて、ヌル値を許可するかデフォルト値が定義されているかのいずれかである場合は、values 句に DEFAULT VALUES を使用することで、すべてのデフォルト値を含むレコードを挿入できます。一部の列がヌル値を許可していないかデフォルト値が定義されていない場合、または列リストを指定しない場合には、この種の句は使用できません。
BLOB、CLOB、または BINARY データ型に対する DEFAULT VALUES の使用は、現在のところサポートされていません。
例
設定を切り替えて、現在のセッションではレガシー ヌル サポートを使って新規テーブルが作成されるようにするには、次のステートメントを使用します。
SET TRUENULLCREATE=OFF
エンジンをデフォルト設定に戻して、現在のセッションでは真のヌル サポートを使ってテーブルが作成されるようにするには、次のステートメントを使用します。
SET TRUENULLCREATE=ON
SIGNAL
備考
SIGNAL ステートメントを使って、例外状態や正常終了以外の終了状態を通知することができます。
SQLSTATE 値を通知すると、SQLSTATE が特定の値に設定されます。その後、この値はユーザーに返されるか、呼び出し元プロシージャで SQLSTATE 値を介して使用できるようになります。この値は、プロシージャを呼び出しているアプリケーションで使用できます。
SQLSTATE 値と一緒にエラー メッセージを指定することもできます。
メモ: SIGNAL はストアド プロシージャまたはユーザー定義関数の内部でのみ使用できます。
構文
SIGNAL SQLSTATE値 [ , エラー メッセージ ]
SQLSTATE値 ::= ユーザー定義値
エラー メッセージ ::= ユーザー定義メッセージ
例
次の例では、SQLSTATE の初期値 00000 を出力し、通知された後に "SQLSTATE 例外が見つかりました" を出力します。最後に出力される SQLSTATE は W9001 になります。
CREATE PROCEDURE GenerateSignal();
BEGIN
SIGNAL 'W9001';
END;
CREATE PROCEDURE TestSignal() WITH DEFAULT HANDLER;
BEGIN
PRINT SQLSTATE;
CALL GenerateSignal();
IF SQLSTATE <> '00000' THEN
PRINT 'SQLSTATE 例外が見つかりました';
END IF;
PRINT SQLSTATE;
END;
————————
CREATE PROCEDURE GenerateSignalWithErrorMsg();
BEGIN
SIGNAL 'W9001', '構文が無効です;
END;
CALL GenerateSignalWithErrorMsg()
関連項目
SQLSTATE
備考
SQLSTATE 値は、正常終了、警告、または例外の状態を表します。ODBC で定義される SQLSTATE 値の完全な一覧は、Microsoft ODBC のドキュメントに記載されています。
ハンドラーが実行されるとき、そのハンドラー内のステートメントは、複合ステートメントの本体内のステートメントと同じように SQLSTATE 値に影響します。ただし、特定の状態に対して特定の動作を行うハンドラーは、完了時にその状態を再割り当てして、状態に影響を与えないようにすることもできます。このとき、ハンドラーは再呼び出しされません。再呼び出しはループの原因となります。その代わりに Zen では、例外状態が未処理の例外として扱われ、実行が停止します。
関連項目
START TRANSACTION
START TRANSACTION は、論理トランザクションの開始を知らせるものであり、常に、COMMIT または ROLLBACK と組み合わせて使用する必要があります。
構文
START TRANSACTION
SQL ステートメント
COMMIT | ROLLBACK [WORK]
備考
START TRANSACTION はストアド プロシージャ内でのみサポートされます。SQL Editor では START TRANSACTION を使用できません。SQL Editor は AUTOCOMMIT をオンに設定します。
例
次の例では、ストアド プロシージャの中で、Billing テーブル内の Amount_Owed 列を更新するトランザクションが開始されます。この作業がコミットされると、別のトランザクションによって Amount_Paid 列が更新されてゼロに設定されます。最後の COMMIT WORK ステートメントにより、2 番目のトランザクションが終了します。
START TRANSACTION;
UPDATE Billing B
SET Amount_Owed = Amount_Owed - Amount_Paid
WHERE Student_ID IN (SELECT DISTINCT E.Student_ID
FROM Enrolls E, Billing B WHERE E.Student_ID = B.Student_ID);
COMMIT WORK;
START TRANSACTION;
UPDATE Billing B
SET Amount_Paid = 0
WHERE Student_ID IN (SELECT DISTINCT E.Student_ID
FROM Enrolls E, Billing B WHERE E.Student_ID = B.Student_ID);
COMMIT WORK;
関連項目
UNION
備考
UNION または UNION ALL を使用する SELECT ステートメントを使って、複数の SELECT クエリから 1 つの結果テーブルを取得できます。UNION クエリは、2 つ以上のデータ ソースに含まれる類似した情報を結合して 1 つにするのに適しています。
UNION を使用すると、重複行が削除されます。UNION ALL を使用すると、重複行が保持されます。重複行を削除する必要がない限り、UNION ALL オプションの使用をお勧めします。
UNION では、Zen データベース エンジンは結果セット全体を整列させるため、テーブルが大きいと処理に数分かかることがあります。UNION ALL では、ソートは不要になります。
Zen データベースは、UNION ステートメントでの LONGVARBINARY 列の使用をサポートしていません。UNION ステートメントでは、LONGVARCHAR および NLONGVARCHAR は 65500 バイトまでに制限されています。演算子 UNION は、1 つ以上のビューを参照する SQL ステートメントに適用することはできません。
UNION に含まれる 2 つのクエリ スペックは互換性がなければなりません。それぞれのクエリは同数の列を持ち、それらの列は互換性のあるデータ型である必要があります。
UNION キーワードの後にくる SELECT ステートメントの ORDER BY 句で、最初の SELECT リストにある列名を使用できます。また、序数を使って目的の列を示すこともできます。たとえば、次のステートメントは有効です。
SELECT c1, c2, c3 FROM t1 UNION SELECT c4, c5, c6 FROM t2 ORDER BY t1.c1, t1.c2, t1.c3
SELECT c1, c2, c3 FROM t1 UNION SELECT c4, c5, c6 FROM t2 ORDER BY 1, 2, 3
また、列名のエイリアスも使用できます。
SELECT c1 x, c2 y, c3 z FROM t1 UNION SELECT c1, c2, c3 FROM t2 ORDER BY x, y, z
SELECT c1 x, c2 y, c3 z FROM t1 a UNION SELECT c1, c2, c3 FROM t1 b ORDER BY a.x, a.y, a.z
エイリアスは、クエリ内のどのテーブル名、列名とも異なっている必要があります。
例
次の例では、名字が "M" で始まるか、成績評価点平均が 4.0 の生徒の ID 番号の一覧が示されます。結果テーブルに重複する行は含まれません。
SELECT Person.ID FROM Person WHERE Last_name LIKE 'M%' UNION SELECT Student.ID FROM Student WHERE Cumulative_GPA = 4.0
次の例では、重複行を含めた person テーブルおよび faculty テーブルの列 ID が抽出されます。
SELECT person.id FROM person UNION ALL SELECT faculty.id from faculty
次の例では、名字が "M" で始まるか、成績評価点平均が 4.0 の生徒の ID 番号の一覧が示されます。結果テーブルには重複行が含まれず、最初の列に従って結果セットが並べられます。
SELECT Person.ID FROM Person WHERE Last_name LIKE 'M%' UNION SELECT Student.ID FROM Student WHERE Cumulative_GPA = 4.0 ORDER BY 1
NULL スカラー関数を使用すると、UNION 選択リストに親選択リストとは異なる数のエントリを持たせることができます。これを行うには、CONVERT 関数を使用して NULL を強制的に正しい型に変換する必要があります。
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 VALUES (1,1)
CREATE TABLE t2 (c1 INTEGER)
INSERT INTO t2 VALUES (2)
SELECT c1, c2 FROM t1
UNION SELECT c1, CONVERT(NULL(),sql_integer)FROM t2
UNION SELECT c1, CONVERT(NULL(),sql_integer)FROM t2
関連項目
UNIQUE
備考
インデックスに重複する値を許可しないことを指定するには、UNIQUE キーワードを使用します。UNIQUE キーワードを使用して CREATE INDEX ステートメントを実行したときにインデックスを構成する 1 つまたは複数の列に重複する値があった場合、Zen はステータス コード 5 を返し、インデックスを作成しません。
メモ: UNIQUE キーワードは、インデックスの属性リストの中で、指定する列名の後に置かないでください。推奨される構文は CREATE UNIQUE INDEX です。
関連項目
UPDATE
UPDATE ステートメントを使用することにより、データベース内の列の値を変更することができます。
構文
UPDATE < テーブル名 | ビュー名 > [ エイリアス名 ]
SET 列名 = < NULL | DEFAULT | 式 | サブクエリ式 > [ , 列名 = ... ]
[ FROM テーブル参照 [ , テーブル参照 ]...
[ WHERE 検索条件 ]
テーブル名 ::= ユーザー定義名
ビュー名 ::= ユーザー定義名
テーブル参照 ::= { OJ 外部結合定義 }
| 結合定義
| ( 結合定義 )
外部結合定義 ::= テーブル参照 外部結合タイプ JOIN テーブル参照 ON 検索条件
外部結合タイプ ::= LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
検索条件 ::= 検索条件 AND 検索条件
| 検索条件 OR 検索条件
| NOT 検索条件
| ( 検索条件 )
| 述部
データベース名 ::= ユーザー定義名
ビュー名 ::= ユーザー定義名
結合定義 ::= テーブル参照 [ 結合タイプ ] JOIN テーブル参照 ON 検索条件
| テーブル参照 CROSS JOIN テーブル参照
| 外部結合定義
結合タイプ ::= INNER | LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
サブクエリ式 ::= ( クエリ スペック )
備考
UPDATE ステートメントは、DELETE および INSERT と同様にアトミックな方法で動作します。つまり、複数の行の更新に失敗した場合、同じステートメントによって実行された前の行の更新がすべてロール バックされます。
UPDATE ステートメントの SET 句にはサブクエリを指定できます。この機能を使用すると、テーブル内の情報を、別のテーブル内のデータまたは同じテーブル内の別の部分を基に更新することができます。
キーワード DEFAULT を使用すると、その値を、指定の列に定義されているデフォルト値に設定することができます。デフォルト値が定義されていないとき、その列がヌル値を許可する場合はヌルを用し、ヌル値を許可しない場合はエラーを返します。デフォルト値と、真のヌルおよび古いリリースのレガシー ヌルの詳細については、SET TRUENULLCREATEを参照してください。
UPDATE ステートメントは一度に 1 つのテーブルしか更新できません。UPDATE は、SET 句内のサブクエリを使ってほかのテーブルと関連付けることができます。これは、更新するテーブルの内容の一部に依存する相関サブクエリか、または別のテーブルにのみ依存する非相関サブクエリにすることができます。
たとえば、次は相関サブクエリです。
UPDATE t1 SET t1.c2 = (SELECT t2.c2 FROM t2 WHERE t2.c1 = t1.c1)
非相関サブクエリと比較してみましょう。
UPDATE t1 SET t1.c2 = (SELECT SUM(t2.c2) FROM t2 WHERE t2.c1 = 10)
純粋な SELECT ステートメントとサブクエリは同じロジックを使って処理されるため、サブクエリを有効な SELECT ステートメントで構成することができます。サブクエリには特別な規則はありません。
UPDATE 内の SELECT が行を返さない場合、UPDATE はヌルを挿入します。指定した列がヌル値を許可しない場合、UPDATE は失敗します。また、SELECT が複数行を返した場合、UPDATE は失敗します。
UPDATE ステートメントは、ステートメント内でのテーブル結合の使用を許可しません。その代わりに、上の例で示したように SET 句で相関サブクエリを使用します。
真のヌルとレガシー ヌルの詳細については、SET TRUENULLCREATEを参照してください。
リテラル文字列の最大長より長いデータの更新
Zen でサポートされるリテラル文字列の最大長は 15,000 バイトです。これよりも長いデータを処理するには、直接の SQL ステートメントを使用し、更新を複数の呼び出しに分割します。次のようなステートメントで開始します。
UPDATE table1 SET longfield = '15000 バイトのテキスト' WHERE 制限
次に、それ以上のデータを追加する次のステートメントを発行します。
UPDATE table1 SET longfield = notefield + '15000 バイトを超えるテキスト' WHERE 制限
FROM 句
オプションの FROM 句と、更新されるテーブル(「更新テーブル」と呼びます)への参照に関して混乱が生じる可能性があります。FROM 句に更新テーブルが現れる場合、その出現のうちの 1 つは更新されるテーブルと同じインスタンスになります。
たとえば、ステートメント UPDATE t1 SET c1 = 1 FROM t1, t2 WHERE t1.c2 = t2.c2 の場合、UPDATE の直後の t1 と FROM の後の t1 は、テーブル t1 の同じインスタンスです。したがって、このステートメントは UPDATE t1 SET c1 = 1 FROM t2 WHERE t1.c2 = t2.c2 と同じことになります。
FROM 句に更新テーブルが複数回現れる場合、その出現のうちの 1 つは更新テーブルと同じインスタンスであると識別される必要があります。FROM 句の参照のうち、更新テーブルと同じインスタンスであると見なされるのは、エイリアスが指定されていない参照です。
したがって、ステートメント UPDATE t1 SET t1.c1 = 1 FROM t1 a, t1 b WHERE a.c2 = b.c2 の場合、FROM 句の t1 のインスタンスはどちらもエイリアスを持っているため、これは正しくありません。次であれば有効です。UPDATE t1 SET t1.c1 = 1 FROM t1, t1 b WHERE t1.c2 = b.c2
FROM 句には次の条件が適用されます。
• UPDATE ステートメントにオプションの FROM 句を含める場合、FROM 句の前にあるテーブル参照にエイリアスを指定することはできません。たとえば、UPDATE t1 a SET a.c1 = 1 FROM t2 WHERE a.c2 = t2.c2 とすると、次のエラーが返されます。
SQL_ERROR (-1)
SQLSTATE "37000"
"オプションの FROM を伴う UPDATE/DELETE ステートメントでは、テーブル エイリアスは使用できません。"
ステートメントの有効なバージョンは、UPDATE t1 SET t1.c1 = 1 FROM t2 WHERE t1.c2 = t2.c2 または UPDATE t1 SET t1.c1 = 1 FROM t1 a, t2 WHERE a.c2 = t2.c2 です。
• FROM 句に更新テーブルへの参照を 2 つ以上含める場合、それらの参照のうちの 1 つにだけエイリアスを指定できます。たとえば、UPDATE t1 SET t1.c1 = 1 FROM t1 a, t1 b WHERE a.c2 = b.c2 とすると、次のエラーが返されます。
SQL_ERROR (-1)
SQLSTATE "37000"
"テーブル t1 があいまいです。"
誤りのあるステートメントでは、エイリアスを "a" とするテーブル t1 が更新テーブルと同じインスタンスであると仮定しています。正しいステートメントは、UPDATE t1 SET t1.c1 = 1 FROM t1, t1 b WHERE t1.c2 = b.c2 です。
• UPDATE ステートメントにおける FROM 句はセッション レベルでのみサポートされます。UPDATE ステートメントがストアド プロシージャ内で発生する場合は、FROM 句はサポートされません。
例
次の例では、Faculty テーブルの ID 103657107 に給与として 95000 を設定し、レコードを更新します。
UPDATE Faculty SET salary = 95000.00 WHERE ID = 103657107
————————
次の例では、DEFAULT キーワードの使い方を示します。
UPDATE t1 SET c2 = DEFAULT WHERE c2 = 'bcd'
UPDATE t1 SET c1 = DEFAULT, c2 = DEFAULT
————————
次の例では、Course テーブルの ECO 305 の履修単位時間を 4 に変更します。
UPDATE Course SET Credit_Hours = 4 WHERE Name = 'ECO 305'
————————
次の例は、Person テーブル中のある人物の住所を変更します。
UPDATE Person p
SET p.Street = '123 Lamar',
p.zip = '78758',
p.phone = 5123334444
WHERE p.ID = 131542520
————————
サブクエリ例 A
2 つのテーブルが作成され、行が挿入されます。最初のテーブル t5 は、列 c1 に値 2 を持つ各行が、2 番目のテーブル t6 の列の値で更新されます。テーブル t6 には列 c2 に値 3 を含む行が 2 行以上あるために、サブクエリから複数行が返されることから、最初の UPDATE は失敗します。たとえ結果値がどちらの場合も同じになるとしても、このような結果になります。2 番目の UPDATE で示されるように、サブクエリ内で DISTINCT キーワードを使用すると、重複する結果が取り除かれ、ステートメントは成功します。
CREATE TABLE t5 (c1 INT, c2 INT)
CREATE TABLE t6 (c1 INT, c2 INT)
INSERT INTO t5(c1, c2) VALUES (1,3)
INSERT INTO t5(c1, c2) VALUES (2,4)
INSERT INTO t6(c1, c2) VALUES (2,3)
INSERT INTO t6(c1, c2) VALUES (1,2)
INSERT INTO t6(c1, c2) VALUES (3,3)
SELECT * FROM t5
結果:
c1 c2
---------- -----
1 3
2 4
UPDATE t5 SET t5.c1=(SELECT c2 FROM t6 WHERE c2=3) WHERE t5.c1=2 — 注意:クエリは失敗します
UPDATE t5 SET t5.c1=(SELECT DISTINCT c2 FROM t6 WHERE c2=3) WHERE t5.c1=2 — 注意:クエリは成功します
SELECT * FROM t5
結果:
c1 c2
---------- -----
1 3
3 4
————————
サブクエリ例 B
2 つのテーブルが作成され、有効な構文のさまざまな例が示されます。サブクエリが複数行を返すことにより UPDATE が失敗する事例に注目してください。また、サブクエリが行を返さない場合に(そこでヌル値が許可される場合)、ヌルが挿入されて UPDATE は成功する点にも注目してください。
CREATE TABLE t1 (c1 INT, c2 INT)
CREATE TABLE t2 (c1 INT, c2 INT)
INSERT INTO t1 VALUES (1, 0)
INSERT INTO t1 VALUES (2, 0)
INSERT INTO t1 VALUES (3, 0)
INSERT INTO t2 VALUES (1, 100)
INSERT INTO t2 VALUES (2, 200)
UPDATE t1 SET t1.c2 = (SELECT SUM(t2.c2) FROM t2)
UPDATE t1 SET t1.c2 = 0
UPDATE t1 SET t1.c2 = (SELECT t2.c2 FROM t2 WHERE t2.c1 = t1.c1)
UPDATE t1 SET t1.c2 = @@IDENTITY
UPDATE t1 SET t1.c2 = @@ROWCOUNT
UPDATE t1 SET t1.c2 = (SELECT @@IDENTITY)
UPDATE t1 SET t1.c2 = (SELECT @@ROWCOUNT)
UPDATE t1 SET t1.c2 = (SELECT t2.c2 FROM t2) -- 更新は失敗します
INSERT INTO t2 VALUES (1, 150)
INSERT INTO t2 VALUES (2, 250)
UPDATE t1 SET t1.c2 = (SELECT t2.c2 FROM t2 WHERE t2.c1 = t1.c1) -- 更新は失敗します
UPDATE t1 SET t1.c2 = (SELECT t2.c2 FROM t2 WHERE t2.c1 = 5) — 更新は成功し、t1.c2 の全行にヌルが挿入されます
UPDATE t1 SET t1.c2 = (SELECT SUM(t2.c2) FROM t2 WHERE t2.c1 = t1.c1)
————————
次の例では、テーブル t1 と t2 を作成し、それらにデータを設定します。UPDATE ステートメントで FROM 句を使用して、新しい値を取得するための別のテーブルを指定します。
DROP table t1
CREATE table t1 (c1 integer, c2 integer)
INSERT INTO t1 VALUES (0, 10)
INSERT INTO t1 VALUES (0, 10)
INSERT INTO t1 VALUES (2, 20)
INSERT INTO t1 VALUES (2, 20)
DROP table t2
CREATE table t2 (c1 integer, c2 integer)
INSERT INTO t2 VALUES (2, 20)
INSERT INTO t2 VALUES (2, 20)
INSERT INTO t2 VALUES (3, 30)
INSERT INTO t2 VALUES (3, 30)
UPDATE t1 SET t1.c1 = t2.c1 FROM t2 WHERE t1.c2 = t2.c2
SELECT * FROM t1
関連項目
UPDATE(位置付け)
UPDATE(位置付け)ステートメントにより、SQL カーソルに関連付けられた行セットの現在の行を更新します。
構文
UPDATE [ テーブル名 ] SET 列名 = プロシージャ式 [ , 列名 = プロシージャ式 ]...
WHERE CURRENT OF カーソル名
テーブル名 ::= ユーザー定義名
カーソル名 ::= ユーザー定義名
備考
このステートメントは、ストアド プロシージャ、トリガー、およびセッション レベルでのみ使用できます。
メモ: セッション レベルでは位置付け UPDATE は使用できますが、DECLARE CURSOR ステートメントは使用できません。アクティブな結果セットのカーソル名を取得する方法は、アプリケーションが使用している Zen のアクセス方法によって決まります。アクセス方法については、Zen のドキュメントを参照してください。
位置付け UPDATE ステートメントをセッション レベルで使用する場合のみ、ステートメントにテーブル名を指定できます。テーブル名をストアド プロシージャやトリガーを使って指定することはできません。
位置付け UPDATE ステートメントをセッション レベルで使用する場合のみ、ステートメントにテーブル名を指定できます。テーブル名をストアド プロシージャやトリガーを使って指定することはできません。
例
次の一連のステートメントは、位置付け UPDATE ステートメントの設定を示します。位置付け UPDATE に必要なステートメントは、DECLARE CURSOR、OPEN CURSOR、および FETCH FROM カーソル名です。
この例の位置付け UPDATE は、HIS 305 という講座名を HIS 306 に変更します。
CREATE PROCEDURE UpdateClass();
BEGIN
DECLARE :CourseName CHAR(7);
DECLARE :OldName CHAR(7);
DECLARE c1 CURSOR FOR SELECT name FROM course WHERE name = :CourseName FOR UPDATE;
SET :CourseName = 'HIS 305';
OPEN c1;
FETCH NEXT FROM c1 INTO :OldName;
UPDATE SET name = 'HIS 306' WHERE CURRENT OF c1;
END;
関連項目
USER
備考
USER キーワードは、SELECT 制限によって返される各行の現在のユーザー名(Master など)を返します。
例
次の例では、course テーブルからユーザー名が返されます。
SELECT USER FROM course
-- Master のインスタンスを 145 返します(テーブルには 145 行含まれます)
SELECT DISTINCT USER FROM course
-- Master のインスタンスを 1 つ返します
関連項目
WHILE
WHILE ステートメントを使用してフローを制御することができます。これによって、WHILE 条件が真である限りステータスを繰り返し実行することができます。オプションで、DO および END WHILE を付けて WHILE ステートメントを使用することができます。
メモ: WHILE ステートメントの構文を混合して使用することはできません。DO および END WHILE 付きの WHILE 構文または WHILE のみの構文のいずれかを使用できます。WHILE 条件で複合ステートメントを使用する場合は、BEGIN と END を使ってステートメント ブロックの始まりと終わりを示す必要があります。
構文
[ ラベル名 : ] WHILE プロシージャ検索条件 [ DO ] [プロシージャ ステートメント [ ; プロシージャ ステートメント ] ]...
[ END WHILE ] [ ラベル名 ]
[ END WHILE ] [ ラベル名 ]
備考
WHILE ステートメントは開始ラベルを持つことができ、そのような場合は、ラベル付き WHILE ステートメントと呼ばれます。
例
次の例では、変数 vInteger の値が 10 になってループが終了するまで、変数の値が 1 ずつ増加します。
WHILE (:vInteger < 10) DO
SET :vInteger = :vInteger + 1;
END WHILE
関連項目
文法要素の定義
以下は、文法構文で使用される要素定義のアルファベット順一覧です。
変更オプション ::= 変更オプション-リスト1 | 変更オプション-リスト2
変更オプション-リスト1 ::= 変更オプション | (変更オプション [ , 変更オプション ]... )
| ADD テーブル制約定義
| ALTER [ COLUMN ] 列定義
| DROP [ COLUMN ] 列名
| DROP CONSTRAINT 制約名
| DROP PRIMARY KEY
| MODIFY [ COLUMN ] 列定義
変更オプション-リスト2 ::= PSQL_MOVE [ COLUMN ] 列名 TO [ [ PSQL_PHYSICAL ] PSQL_POSITION ] 新しい列位置 | RENAME COLUMN 列名 TO 新しい列名
as またはセミコロン ::= AS | ;
before/after ::= BEFORE | AFTER
呼び出し引数 ::= 位置引数 [ , 位置引数 ]...
列制約 ::= NOT NULL
| NOT MODIFIABLE
| UNIQUE
| PRIMARY KEY
| REFERENCES テーブル名 [ ( 列名 ) ] [ 参照アクション ]
照合順序名 ::= '文字列'
列制約定義 ::= [ CONSTRAINT 制約名 ] 列制約
列名 ::= ユーザー定義名
コミット ステートメント ::= COMMIT ステートメント参照
比較演算子 ::= < | > | <= | >= | = | <> | !=
制約名 ::= ユーザー定義名
相関名 ::= ユーザー定義名
カーソル名 ::= ユーザー定義名
データベース名 ::= ユーザー定義名
式 ::= 式 - 式
| 式 + 式
| 式 * 式
| 式 / 式
| 式 & 式
| 式 | 式
| 式 ^ 式
| ( 式 )
| -式
| +式
| ~式
| ?
| リテラル
| スカラー関数
| { fn スカラー関数 }
| USER
リテラル ::= '文字列' | N'文字列'
| 数字
| { d '日付リテラル' }
| { t '時刻リテラル' }
| { ts 'タイムスタンプ リテラル' }
スカラー関数 :: = スカラー関数を参照
式またはサブクエリ ::= 式 | ( クエリ スペック )
フェッチ方向 ::= NEXT
グループ名 ::= ユーザー定義名
インデックス定義 ::= ( インデックス セグメント定義 [ , インデックス セグメント定義 ]... )
インデックス名 ::= ユーザー定義名
インデックス番号 ::= ユーザー定義値 -- 0 から 118 までの整数
インデックス セグメント定義 ::= 列名 [ ASC | DESC ]
挿入/更新/削除 ::= INSERT | UPDATE | DELETE
挿入値 ::= values句
| クエリ スペック
結合定義 ::= テーブル参照 [ INNER ] JOIN テーブル参照 ON 検索条件
| テーブル参照 CROSS JOIN テーブル参照
| 外部結合定義
ラベル名 ::= ユーザー定義名
リテラル ::= '文字列' | N'文字列'
| 数字
| { d '日付リテラル' }
| { t '時刻リテラル' }
| { ts 'タイムスタンプ リテラル' }
order-by式 ::= 式 [ CASE | COLLATE 照合順序名 ] [ ASC | DESC ]
外部結合定義 ::= テーブル参照 外部結合タイプ JOIN テーブル参照 ON 検索条件
外部結合タイプ ::= LEFT [ OUTER ] | RIGHT [ OUTER ] | FULL [ OUTER ]
| SQLSTATE
パラメーター タイプ名 ::= パラメーター名
| パラメーター タイプ パラメーター名
| パラメーター名 パラメーター タイプ
パラメーター タイプ ::= IN | OUT | INOUT | IN_OUT
パラメーター名 ::= [ : ] ユーザー定義名
パスワード ::= ユーザー定義名 | '文字列'
位置引数 ::= 式
桁数 ::= 整数
述部 ::= 式 [ NOT ] BETWEEN 式 AND 式
| 式 比較演算子 式またはサブクエリ
| 式 [ NOT ] IN ( クエリ スペック )
| 式 [ NOT ] IN ( 値 [ , 値 ]... )
| 式 [ NOT ] LIKE 値
| 式 IS [ NOT ] NULL
| 式 比較演算子 ANY ( クエリ スペック )
| 式 比較演算子 ALL ( クエリ スペック )
| EXISTS ( クエリ スペック )
プロシージャ式 ::= 通常の式と同様。ただし、IF 式とスカラー関数は使用できない
プロシージャ検索条件 ::= 通常の検索条件と同様。ただし、サブクエリを含む式は使用できない
プロシージャ ステートメント ::= [ ラベル名 : ] BEGIN [ ATOMIC ] [ プロシージャ ステートメント [ ; プロシージャ ステートメント ]... ] END [ ラベル名 ]
| CALL プロシージャ名 ( プロシージャ式 [ , プロシージャ式 ]... )
| CLOSE カーソル名
| DECLARE カーソル名 CURSOR FOR 選択ステートメント [ FOR UPDATE | FOR READ ONLY ]
| DELETE WHERE CURRENT OF カーソル名
| 削除ステートメント
| FETCH [ フェッチ方向 [ FROM ] ] カーソル名 [ INTO 変数名 [ , 変数名 ] ]
| IF プロシージャ検索条件 THEN プロシージャ ステートメント [ ; プロシージャ ステートメント ]... [ ELSE プロシージャ ステートメント [ ; プロシージャ ステートメント ]... ] END IF
| IF プロシージャ検索条件 プロシージャ ステートメント [ ELSE プロシージャ ステートメント ]
| 挿入ステートメント
| LEAVE ラベル名
| [ ラベル名 : ] LOOP プロシージャ ステートメント [ ; プロシージャ ステートメント ]... END LOOP [ ラベル名 ]
| OPEN カーソル名
| PRINT プロシージャ式 [ , '文字列' ]
| RETURN [ プロシージャ式 ]
| トランザクション ステートメント
| into 付き選択ステートメント
| 選択ステートメント
| SET 変数名 = プロシージャ式
| SIGNAL [ ABORT ] sqlstate 値
| START TRANSACTION [ トランザクション名 ]
| 更新ステートメント
| UPDATE SET 列名 = プロシージャ式 [ , 列名 = プロシージャ式 ]... WHERE CURRENT OF カーソル名
| [ ラベル名 : ] WHILE プロシージャ検索条件 DO [ プロシージャ ステートメント [ ; プロシージャ ステートメント ] ]... END WHILE [ ラベル名 ]
| [ ラベル名 : ] WHILE プロシージャ検索条件 プロシージャ ステートメント
| テーブル変更ステートメント
| インデックス作成ステートメント
| テーブル作成ステートメント
| ビュー作成ステートメント
| インデックス削除ステートメント
| テーブル削除ステートメント
| ビュー削除ステートメント
| 権限付与ステートメント
| 権限取消ステートメント
| 設定ステートメント
プロシージャ名 ::= ユーザー定義名
public またはユーザー/グループ名 ::= PUBLIC | ユーザー/グループ名
クエリ スペック ::= ( クエリ スペック )
FROM テーブル参照 [ , テーブル参照 ]...
[ WHERE 検索条件 ]
[ HAVING 検索条件 ] ]
参照エイリアス ::= OLD [ AS ] 相関名 [ NEW [ AS ] 相関名 ]
| NEW [AS] 相関名 [ OLD [ AS ] 相関名 ]
参照アクション ::= 参照更新アクション [ 参照削除アクション ]
| 参照削除アクション [ 参照更新アクション ]
参照更新アクション ::= ON UPDATE RESTRICT
参照削除アクション ::= ON DELETE CASCADE
| ON DELETE RESTRICT
リリース ステートメント ::= RELEASE ステートメントを参照
結果 ::= ユーザー定義名 データ型
ロールバック ステートメント ::= ROLLBACK WORK ステートメントを参照
セーブポイント名 ::= ユーザー定義名
スカラー関数 ::= スカラー関数の一覧を参照
小数位 ::= 整数
検索条件 ::= 検索条件 AND 検索条件
| 検索条件 OR 検索条件
| NOT 検索条件
| ( 検索条件 )
| 述部
選択項目 ::= 式 [ [ AS ] エイリアス名 ] | テーブル名.*
選択リスト ::= * | 選択項目 [ , 選択項目 ]...
sqlstate値 ::= '文字列'
テーブル制約定義 ::= [ CONSTRAINT 制約名 ] テーブル制約
テーブル制約 ::= UNIQUE ( 列名 [ , 列名 ]... )
| PRIMARY KEY ( 列名 [ , 列名 ]... )
| FOREIGN KEY ( 列名 [ , 列名 ] )
REFERENCES テーブル名
[ ( 列名 [ , 列名 ]... ) ]
[ 参照アクション ]
テーブル要素 ::= 列定義
| テーブル制約定義
テーブル式 ::=
FROM テーブル参照 [ , テーブル参照 ]...
[ WHERE 検索条件 ]
[ GROUP BY 式 [ , 式 ]...
[ HAVING 検索条件 ]
テーブル名 ::= ユーザー定義名
テーブル権限 ::= ALL
| SELECT [ ( 列名 [ , 列名 ]... ) ]
| UPDATE [ ( 列名 [ , 列名 ]... ) ]
| INSERT [ ( 列名 [ , 列名 ]... ) ]
| DELETE
| ALTER
| REFERENCES
テーブル参照 ::= { OJ 外部結合定義 }
| [データベース名.]テーブル名 [ [ AS ] エイリアス名 ]
| 結合定義
| ( 結合定義 )
テーブル サブクエリ ::= クエリ スペック [ [ UNION [ ALL ]
クエリ スペック ]... ] [ limit句 ] [ ORDER BY order-by式 [ , order-by式 ]... ]
クエリ スペック ]... ] [ limit句 ] [ ORDER BY order-by式 [ , order-by式 ]... ]
limit句 ::= [ LIMIT [オフセット,] 行数 | 行数 OFFSET オフセット | ALL [ OFFSET オフセット ] ]
オフセット ::= 数値 | ?
行数 ::= 数値 | ?
トランザクション ステートメント ::= コミット ステートメント
| ロールバック ステートメント
| リリース ステートメント
トリガー名 ::= ユーザー定義名
ユーザーおよびパスワード ::= ユーザー名 [ : ] パスワード
ユーザー/グループ名 ::= ユーザー名 | グループ名
ユーザー名 ::= ユーザー定義名
値 ::= リテラル | USER | NULL | ?
値リスト ::= ( 値 [ , 値 ]... )
values句 ::= DEFAULT VALUES | VALUES ( 式 [ , 式 ]... )
変数名 ::= ユーザー定義名
ビュー名 ::= ユーザー定義名
SQL ステートメント リスト
SqlStatementList は次のように定義されます。
SqlStatementList
ステートメント ';' | SqlStatementList ';'
ステートメント ::= ステートメント ラベル ':' ステートメント
| BEGIN ... END ブロック
| CALL ステートメント
| CLOSE CURSOR ステートメント
| COMMIT ステートメント
| DECLARE CURSOR ステートメント
| DECLARE 変数ステートメント
| DELETE ステートメント
| FETCH ステートメント
| IF ステートメント
| INSERT ステートメント
| LEAVE ステートメント
| LOOP ステートメント
| OPEN ステートメント
| PRINT ステートメント
| RELEASE SAVEPOINT ステートメント
| RETURN ステートメント
| ROLLBACK ステートメント
| SAVEPOINT ステートメント
| SELECT ステートメント
| SET ステートメント
| SIGNAL ステートメント
| START TRANSACTION ステートメント
| UPDATE ステートメント
| WHILE ステートメント
述部
述部は次のように定義されます。
式 比較演算子 式
| 式 [ NOT ] BETWEEN 式 AND 式
| 式 [ NOT ] LIKE 文字列リテラル
| 式 IS [ NOT ] NULL
| NOT 述部
| 述部 AND 述部
| 述部 OR 述部
| '(' 述部 ')' 比較演算子 ::= '=' | '>=' | '>' | '<=' | '<' | '<>' | '!='
| [ NOT ] IN 値リスト
式
式は次のように定義されます。
数字
| 文字列リテラル
| 列名
| 変数名
| NULL
| CONVERT '(' 式 ',' データ型 ')'
| '-' 式
| 式 '+' 式
| 式 '-' 式
| 式 '*' 式
| 式 '/' 式
| 式 '&' 式
| '~' 式
| 式 '|' 式
| 式 '^' 式
| 関数名 '(' [ 式リスト ] ')'
| '(' 式 ')'
| '{' D 文字列リテラル '}'
| '{' T 文字列リテラル '}'
| '{' TS 文字列リテラル '}'
| @:IDENTITY
| @:ROWCOUNT
| @@BIGIDENTITY
| @@IDENTITY
| @@ROWCOUNT
| @@VERSION
式リストは次のように定義されます。
式リスト ::= 式 [ , 式 ... ]
グローバル変数
Zen は次のグローバル変数をサポートしています。
• @@SPID
グローバル変数は 2 つの @ マーク(@@)で始まります。すべてのグローバル変数は、接続ごとの変数です。データベース接続ごとにそれぞれ固有の @@IDENTITY、@@BIGIDENTITY、@@ROWCOUNT、および @@SPID 値を持ちます。@@VERSION の値は、この変数が使用されているステートメントを実行するエンジンのバージョンに関する情報です。
@@IDENTITY および @@BIGIDENTITY
これらの変数は、一番最後に挿入された列値を返します。値は符号付き整数値になります。初期値はヌルです。
変数は単一列のみ参照することができます。ターゲット テーブルに 2 つ以上の IDENTITY 列が含まれている場合、この変数の値は、テーブルの主キーとなる IDENTITY 列を参照します。このような列が存在しない場合には、この変数の値はテーブル内の最初の IDENTITY 列を参照します。
一番最後の挿入が IDENTITY 列を含まないテーブルに対して行われたものであった場合、@@IDENTITY の値はヌルに設定されます。
BIGIDENTITY 値の場合は、@@BIGIDENTITY を使用します。SMALLIDENTITY 値の場合は、@@IDENTITY を使用します。
例
SELECT @@IDENTITY
現在の接続でレコードが挿入されていない場合はヌルを返し、そうでない場合は、一番最後に挿入された行の IDENTITY 列の値を返します。
SELECT * FROM t1 WHERE @@IDENTITY = 12
一番最後に挿入された行の IDENTITY 列の値が 12 の場合はその行を返し、そうでない場合は行を返しません。
INSERT INTO t1(c2) VALUES (@@IDENTITY)
最後に挿入された行の IDENTITY 値を新しい行の C2 列に挿入します。
UPDATE t1 SET t1.c1 = (SELECT @@IDENTITY) WHERE t1.c1 = @@IDENTITY + 10
C1 列の値が最後に挿入された行の IDENTITY 列の値より 10 大きい場合は、C1 列をこの IDENTITY 値で更新します。
UPDATE t1 SET t1.c1 = (SELECT NULL FROM t2 WHERE t2.c1 = @@IDENTITY)
C1 列の値が最後に挿入された行の IDENTITY 列の値と等しい場合は、C1 列をヌル値で更新します。
以下の例では、ストアド プロシージャを作成し、それを呼び出します。プロシージャは、最後に更新された行の IDENTITY 列の値と入力値の合計を変数 V1 に設定します。プロシージャは次に、C1 列が V1 と等しい行をテーブルから削除し、その後で何行削除されたかを示すメッセージを出力します。
CREATE PROCEDURE TEST (IN :P1 INTEGER);
BEGIN
DECLARE :V1 INTERGER;
SET :V1 = :P1 + @@IDENTITY;
DELETE FROM t1 WHERE t1.c1 = :V1;
IF (@@ROWCOUNT = 0) THEN
PRINT '行は削除されませんでした';
ELSE
PRINT CONVERT(@@ROWCOUNT, SQL_CHAR) + ' 行が削除されました';
END IF;
END;
CALL TEST (@@IDENTITY)
@@ROWCOUNT
この変数は、現在の接続で一番最後に行った操作により影響を受けた行の数を返します。値は符号なし整数になります。初期値はゼロです。
@@ROWCOUNT 変数は、INSERT、UPDATE、または DELETE ステートメント後に使用した場合にのみ有効になります。
例
SELECT @@ROWCOUNT
現在の接続で直前に行った操作により影響を受けたレコードがない場合はゼロを返し、そうでない場合は、直前の操作により影響を受けた行数を返します。
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 (c1, c2) VALUES (100,200)
INSERT INTO t1(c1, c2) VALUES (300, @@ROWCOUNT)
SELECT @@ROWCOUNT
結果:
1(@@ROWCOUNT 変数の値)
4 番目の行で、@@ROWCOUNT 変数の値は 1 になります。これは、直前の INSERT 操作が影響を与えたのは 1 行だからです。
@@IDENTITY の例も参照してください。
@@SESSIONID
この変数は、Zen サーバー エンジン、レポート エンジン、またはワークグループ エンジンへの接続を識別する 8 バイトの整数値を返します。この整数は時刻の値と増分カウンターの組み合わせです。この変数は Zen 接続をそれぞれ一意に識別するために使用できます。
@@SESSIONID が値を返すには、データベース エンジンに接続されていることが必要です。データベース エンジンへの接続が失われた場合、変数は ID を返すことができません。
例
SELECT @@SESSIONID
この例は、26552653137523 などの整数の ID を返します。
@@SPID
この変数、サーバー プロセス ID は、Zen 接続のシステム スレッドの ID を示す整数値を返します。
データベース エンジンへの接続が失われた場合、SPID 変数は ID を返すことができません。代わりに、ステートメントが SqlState 08S01 を示すエラーを返します。
例
SELECT @@SPID
この例は、402 などの整数の ID を返します。
@@VERSION
この変数を使用する SQL ステートメントは、セッションが接続されている Zen サーバー エンジン、レポート エンジン、またはワークグループ エンジンに基づいて値を返します。
• Zen サーバーの場合、この値はローカル エンジンのバージョン、およびローカル オペレーティング システムのビット数、名前、およびバージョンになります。
• Zen Client Reporting Engine の場合は、ローカル レポート エンジンのバージョン、およびローカル オペレーティング システムのビット数、名前、およびバージョンになります。
• Zen Client の場合は、クライアントの接続先であるリモート Zen サーバー上のエンジンのバージョン、およびそのサーバーが実行されているオペレーティング システムのビット数、名前、およびバージョンになります。
• Zen Workgroup Engine の場合、この値はローカル エンジンのバージョン、およびローカル オペレーティング システムのビット数、名前、およびバージョンになります。
例
SELECT @@version
この例は、次のようなテキスト情報を返します。
Actian Zen - 14.10.020.000 (x86_64) Server Engine - Copyright (C) Actian Corporation 2019 on (64-bit) Windows NT 6.2 7d
ほかの特性
このトピックでは、SQL 文法のその他の特性について説明します。この章は、以下のセクションに分かれています。
テンポラリ ファイル
Zen は、指定されたクエリを処理するためにテンポラリ テーブルを生成する必要がある場合は、次のいずれかの方法で決定された場所にそのファイルを作成します。
• 文字列キー値の PervasiveEngineOptions\TempFileDirectory を ODBC.INI に手動で追加した場合、Zen は TempFileDirectory に設定されたパスを使用します。Windows における 32 ビットおよび 64 ビット Zen インストレーションに対するレジストリの場所は、どちらも HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC.INI です。Linux および Raspbian の場合、ODBC.INI ファイルは /usr/local/actianzen/etc にあります。
• ZenCC または bcfg を使用して Zen エンジンのテンポラリ ファイル ディレクトリのプロパティを設定した場合、Zen はこの場所を使用します。詳細については、『Advanced Operations Guide』のテンポラリ ファイルを参照してください。
• ここに挙げた最初の 2 つのオプションのいずれも使用していない場合、Zen は Windows プラットフォームでは以下の順序でファイルの場所を調べます。
1. TMP 環境変数で指定されたパス
2. TEMP 環境変数で指定されたパス
3. USERPROFILE 環境変数で指定されたパス
4. Windows ディレクトリ
たとえば、TMP 環境変数が定義されていない場合、Zen は TEMP 環境変数、その次の環境変数という順に指定されているパスを使用します。
Linux ディストリビューションでは、Zen はサーバー プロセスの現在のディレクトリを使用します。TMP の使用を試みることはありません。
Zen はクエリが完了すると、そのクエリの処理に使用されたすべてのテンポラリ ファイルを削除します。クエリが SELECT ステートメントの場合には、テンポラリ ファイルは結果セットがアクティブである間、つまり、結果セットが呼び出し元のアプリケーションによって解放されるまでは存在します。
テンポラリ ファイルはどのような場合に作成されるか
Zen は、メモリ内、ディスク上、および Btrieve(MicroKernel エンジン)の 3 種類のテンポラリ ファイルを使用します。
メモリ内のテンポラリ ファイル
メモリ内のテンポラリ ファイルは以下の状況で使用されます。
• 前方のみのカーソル
• テンポラリ ファイル内のバイト数は 250,000 未満
• インデックスを使用しない ORDER BY、GROUP BY、DISTINCT を伴う SELECT ステートメントで、ORDER BY、GROUP BY、DISTINCT 内に BLOB または CLOB を含まない。また、UNION を伴う選択リストに BLOB または CLOB を含まない。
ディスク上のテンポラリ ファイル
ディスク上のテンポラリ ファイルは以下の状況で使用されます。
• 前方のみのカーソル
• テンポラリ ファイル内のバイト数は 250,000 より大きい
• インデックスを使用しない ORDER BY、GROUP BY、DISTINCT を伴う SELECT ステートメントで、ORDER BY、GROUP BY、DISTINCT 内に BLOB または CLOB を含まない。また、UNION を伴う選択リストに BLOB または CLOB を含まない。
Btrieve テンポラリ ファイル
Btrieve テンポラリ ファイルは以下の状況で使用されます。
• ORDER BY、GROUP BY、DISTINCT 内に BLOB または CLOB を使用する前方のみカーソルがあるか、UNION を使用する選択リストで BLOB または CLOB を使用。
• UNION クエリを伴う動的または静的カーソル、または、インデックスを使用しない ORDER BY、GROUP BY、DISTINCT を伴う SELECT ステートメント
Zen は、静的カーソル SELECT クエリで各ベース テーブルに Btrieve テンポラリ ファイルを作成しません。その代わり、各ベース テーブルを MicroKernel を使用して開き、ファイルの静的な表現としてファイル内にページを予約します。静的カーソルを介して行われた変更は、そのカーソルからは見えません。
NULL 値を使った作業
Zen は NULL を未知の値として解釈します。したがって、2 つの NULL 値を比較すると、等価とは見なされません。
WHERE NULL=NULL という評価式は False を返します。
バイナリ データを使った作業
次のシナリオについて考えてみましょう。t1 テーブルで c1 という名前が付けられた BINARY(4)列にリテラル値 '1' を挿入します。次に、SELECT * FROM t1 WHERE c1='1' というステートメントを入力します。
データベース エンジンは、データ入力に使用したものと同じバイナリ形式を用いてデータを取得できます。つまり、上記の SELECT の例は、リテラルの一致がなくても正しく動作し、値 0x01000000 を返します。
メモ: データベース エンジンは、挿入する奇数桁のバイナリ値の前に必ずゼロ('0')を追加します。たとえば、値 '010' を挿入すると、値 '0x00100000' がデータ ファイルに保存されます。
現在、Zen はバイナリ定数を示す接尾辞 0x をサポートしていません。バイナリ定数は、一重引用符で囲んだ 16 進数の文字列になります。
現在、Zen はバイナリ定数を示す接尾辞 0x をサポートしていません。バイナリ定数は、一重引用符で囲んだ 16 進数の文字列になります。
この動作は、Microsoft SQL Server の動作と同じです。
インデックスの作成
インデックス可能な VARCHAR 型の列の最大サイズは、ヌル値が許可されない列では 254 バイト、ヌル値が許可される列では 253 バイトです。
CHAR 型の列の最大サイズは、ヌル値が許可されない列では 255 バイト、ヌル値が許可される列では 254 バイトです。16.0 形式ファイルの場合、この制限は 1024 と 1023 です。
インデックス可能な NVARCHAR 型の列の最大サイズは NVARCHAR(126) です。この制限は、ヌル値が許可される列とヌルでない列の両方に適用されます。NVARCHAR のサイズは UCS-2 文字単位で指定されます。
NCHAR 型の列の最大サイズは NCHAR(127) です。この制限は、ヌル値が許可される列とヌルでない列の両方に適用されます。NCHAR のサイズは UCS-2 文字単位で指定されます。
Btrieve の最大キーサイズは、Btrieve ファイル形式に応じて 255 または 1024 です。列でヌル値が許可され、インデックスが作成されている場合、セグメント キーは、ヌル インジケーターの 1 バイトと、インデックス列の最大 254 バイトまたは 1023 バイトを使って作成されます。VARCHAR 型の列が CHAR 型の列と異なるのは、長さバイト(Btrieve lstring)またはゼロ終端バイト(Btrieve zstring)のいずれかが予約されており、そのため有効な記憶域が 1 バイト増える点です。NVARCHAR(Btrieve wzstring)型の列が NCHAR 型の列と異なるのは、ゼロ終端文字が予約されており、そのため有効な記憶域が 2 バイト増える点です。
小数点の記号のカンマ
多くの地域では、浮動小数点数フィールド内で整数部と小数部を区切るのにカンマを使用します。たとえば、1 と 2 分の 1 を数字で表すのに 1.5 ではなく 1,5 を使用します。
Zen は、ピリオドとカンマの両方を小数点の記号としてサポートしています。Zen はオペレーティング システムの地域の設定に基づいて、ピリオドまたはカンマを使用する入力値を受け入れます。デフォルトでは、データベース エンジンはピリオドを使って値を表示します。
メモ: 小数点の記号がピリオドでない場合、SQL ステートメントでは数値を引用符で囲む必要があります。
出力と表示のみについては、セッション レベルのコマンド SET DECIMALSEPARATORCOMMA を使用すれば、出力(たとえば、SELECT の結果)でカンマを小数点の記号として使用するように指定できます。このコマンドは、データの入力や保存には影響しません。
クライアント/サーバーの考慮
小数点の記号としてカンマをサポートするかは、オペレーティング システムの地域の設定によります。クライアント オペレーティング システムとサーバー オペレーティング システムのどちらにも地域の設定があります。期待される動作は両方の設定に応じて変わります。
• サーバーとクライアントどちらか一方の地域設定で小数点の記号にカンマが使用されている場合、Zen はピリオド区切りの値と引用符で囲まれたカンマ区切りの値の両方を受け入れます。
• サーバーとクライアントどちらの地域設定でも小数点の記号にカンマが使用されていない場合、Zen はカンマ区切りの値を受け入れません。
地域の設定の変更
小数点の記号の情報は、Windows オペレーション システムが動作しているマシンでのみ取得または変更できます。Linux の場合、小数点の記号はピリオドに設定されており、設定を修正することはできません。Linux サーバー エンジンをお持ちで、小数点の記号にカンマを使用したい場合は、必ずすべてのクライアント コンピューターが小数点にカンマを使用する地域に設定されていなければなりません。
Windows オペレーティング システムの地域の設定を変更するには、コントロール パネルからこの設定にアクセスします。変更したら、Zen サービスを停止して再起動し、データベース エンジンが変更された設定を使用できるようにします。
例
例 A – サーバーの地域が小数点の記号にカンマを使用する
クライアントの地域が小数点の記号にカンマを使用する場合:
CREATE TABLE t1 (c1 DECIMAL(10,3), c2 DOUBLE)
INSERT INTO t1 VALUES (10.123, 1.232)
INSERT INTO t1 VALUES ('10,123', '1.232')
SELECT * FROM t1 WHERE c1 = 10.123
SELECT * FROM t1 FROM c1 = '10,123'
上記の 2 つの SELECT ステートメントがクライアントから実行された場合、次の値が返されます。
10.123、1.232
10.123、1.232
SET DECIMALSEPARATORCOMMA=ON
SELECT * FROM t1 FROM c1 = '10,123'
上記の SELECT ステートメントが、小数点の記号を設定した後でクライアントから実行された場合は、次の値が返されます。
10,123、1,232
クライアントの地域が小数点の記号にピリオドを使用しており、次のステートメントが新しい接続から発行される場合(SET DECIMALSEPARATORCOMMA のデフォルトの動作):
CREATE TABLE t1 (c1 DECIMAL(10,3), c2 DOUBLE)
INSERT INTO t1 VALUES (10.123, 1.232)
INSERT INTO t1 VALUES ('10,123', '1.232')
SELECT * FROM t1 WHERE c1 = 10.123
SELECT * FROM t1 WHERE c1 = '10,123'
上記の 2 つの SELECT ステートメントがクライアントから実行された場合、次の値が返されます。
10.123、1.232
10.123、1.232
例 B – サーバーの地域が小数点の記号にピリオドを使用する
クライアントの地域が小数点(DECIMAL)の記号にカンマを使用する場合:
例 A のクライアントがカンマを使用する場合と同様です。
クライアントの地域が小数点(DECIMAL)の記号にピリオドを使用する場合:
CREATE TABLE t1 (c1 DECIMAL(10,3), c2 DOUBLE)
INSERT INTO t1 VALUES (10.123, 1.232)
INSERT INTO t1 VALUES ('10,123', '1,232') -- 割り当てエラー
SELECT * FROM t1 WHERE c1 = 10.123
SELECT * FROM t1 WHERE c1 = '10,123' -- 割り当てエラー
上記の最初の SELECT ステートメントがクライアントから実行された場合、次の値が返されます。
10.123、1.232
SET DECIMALSEPARATORCOMMA=ON
SELECT * FROM t1 FROM c1 = 10.123
上記の SELECT ステートメントが、表示用の小数点の記号を設定した後で実行された場合は、次の値が返されます。
10,123、1,232
最終更新日: 2024年07月09日