Actian Zen でログ データをよりアクセスしやすく便利にする方法
フラット ファイルはすばやく簡単に設定できるため、開発者によって頻繁に使用されます。特に、フラット ファイルは多くの場合、ステータス メッセージやエラー メッセージがファイルに次々と書き込まれるアプリケーション ログやシステム ログで使用されます。
ログ データをファイルに書き込むことは簡単ですが、そのデータを共有する必要がある場合や、重要なログの詳細を見つけ出す必要がある場合にはどうなるでしょうか? これは、はるかに柔軟性が備わっている Actian Zen の使いどころです。
いくつかの一般的なシナリオとして、アプリケーション データの記録、ログ データの取得、およびログ内の重要な情報の検索のシナリオを見て、ログ ファイルを Zen データ ファイルに格納することが理にかなっている理由を確認しましょう。
右側の「このページの内容」では当ページで扱うトピックを示しています。
フラット ファイルへのログ記録
フラット ファイルへのログ データの書き込みは簡単で、一般的にファイルは移植可能であると考えられます。これが、アプリケーションが伝統的にそれらのファイルの使用をデフォルトとしてきた理由です。エントリの書き込みは単に、ファイルを開き、新しいエントリを追加し、ファイル ハンドルを閉じるなどの問題であるにすぎません。
void logEvent(string source, string event, int priority, string category)
{
ofstream logFile("application.log", ofstream::out | ofstream::app);
logFile << source << ", " << event << ", "
<< priority << ", " << category << endl;
logFile.close();
}
ログ ファイルを読み取ったり、ログ ファイルを処理するコードを書いたりする人は、各フィールドに何が格納されているかを知る必要があります。フラット テキスト ファイル内のフィールドはすべて、テキスト文字列として格納されています。文字列が表すデータが他のデータ型(数字など)として意図されたものである場合は、その値を解析する必要があります。
処理するファイルからの読み取りには、ファイルへの書き込みより多くのコードを必要とします。これには、ファイルの行を一度に 1 行取り込み、その行をフィールドに分割することが含まれます。各フィールドは異なるデータ型を表している場合があります。一部のデータ型については、値が正しく処理されるよう、それらの値を保持する分離フィールドの解析および変換が必要になる場合があります。
struct Date {
unsigned char month;
unsigned char day;
unsigned int year;
};
struct LogEntry {
string source;
string event;
int priority;
string category;
};
void logEvent(string source, string event, int priority, string category)
{
ofstream logFile("application.log", ofstream::out | ofstream::app);
logFile << source << ", " << event << ", " << priority << ", "
<< category << endl;
logFile.close();
}
bool readLogEntry(ifstream& inputStream, string& source, string& event,
int& priority, string& category)
{
string line;
vector<string> fieldList;
string token;
if (getline(inputStream, line))
{
istringstream fieldStream(line);
while (getline(fieldStream, token, ',')) {
fieldList.push_back(token);
}
source = fieldList[0];
event = fieldList[1];
priority = stoi(fieldList[2]);
category = fieldList[3];
return true;
}
return false;
}
bool readAllLogs(string sourceLogFile)
{
vector<LogEntry> logEntryList;
ifstream inputStream(sourceLogFile);
if (!inputStream.good())
return false;
while (inputStream.good())
{
LogEntry entry;
if (readLogEntry(inputStream, entry.source, entry.event,
entry.priority, entry.category))
logEntryList.push_back(entry);
}
}
フラット ファイル内の特定の属性を持つログ エントリのみに関心があるとします。それらを見つける唯一の方法は、ファイル全体をスキャンすることです。小さなログ ファイルの場合、これはそれほど問題ではありません。しかし、ログ ファイルが大きくなるにつれ、エントリを見つけるためにより多くのデータの処理が必要となり、より多くの時間を要します。たとえば、最大値または最小値を含んでいるレコードを見つけるには、レコードを並べ替える必要があり、それはつまり、すべてのレコードをメモリに読み取る必要があるということです。
セキュリティという別の問題があります。フラット ファイルを別のシステムにコピーするのはとても簡単ですが、ファイル内の情報は、必ずしもすべての人が読むためのものではありません。フラット ファイルが備えている唯一の保護は、オペレーティング システムによって提供されるものです。ファイルにアクセスできる人の制限は、アクセス制御リスト(ACL)で処理されます。ファイルは別のコンピューターにコピーされたら、ACL によってまったく制限されなくなります。
3 番目の問題はマルチソース アクセスです。複数のアプリケーション、または 1 つのアプリケーションの複数のインスタンスが 1 つのコンピューターで実行されているとします。フラット ファイルの場合は、通常、アプリケーションごとに個別のファイルを管理する必要があり、それが検索、並べ替え、分析をより複雑にしています。Zen データ ファイルの場合は、データを保護する Zen のすべての固有の ACID 機能により、複数のアプリケーション間で単一ファイルを簡単に共有できます。
Zen データ ファイルへのログ記録
次に、同じシナリオで、Zen データ ファイルを代わりに使用するシナリオを考えてみましょう。
Zen データ ファイルでは、ログに記録されたデータの構造体を定義することができます。テーブルに格納されたデータは厳密に型指定されており、簡単に分析および処理できる形式で格納されています。標準の SQL コマンドを使用して、ODBC ドライバーを介してデータにアクセスするか、または SQL を使用しないで、Btrieve 2 API 関数を使用してデータ ファイルへの書き込み/読み取りを迅速に行うことができます。データベースを構成する実際のファイルは、同じコンピューターまたはリモート コンピューターに保存できます。
また、ファイルのフィールドに一致する構造体をコードで定義することもできます。Btrieve 2 API は、ファイルから構造体のインスタンスへ直接読み取ることができます。フラット ファイルのコードとは異なり、値をメモリに読み込むための追加の解析は必要ありません。
いくつかのコンパイラ オプションを設定して、レコードの構造体が、Btrieve 2 が期待するメモリ レイアウトになるようにする必要があります。一部のコンパイラは、メモリ アドレスが 16 ビット境界または 32 ビット境界に整列されるよう、余分な使用されないフィールドを構造体に挿入します。この設定を無効にすると、構造体に余分なフィールドが挿入されず、メモリ レイアウトが一致するようになります。
実証するために、前の例と同じ情報を保持する Zen ベースのイベント ログを作成しましょう。それぞれに ID フィールドも追加します。Zen Control Center でテーブルは次のようになります。
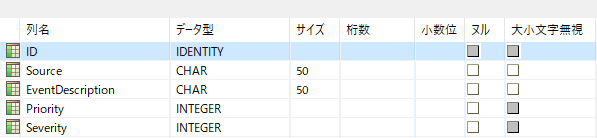
構造体内の ID、Priority、および Severity フィールドはすべて整数で、Source および EventDescription フィールドは文字の配列です。
次に、これらをメモリ内で保持するための構造体を定義しましょう。
struct Event {
int ID;
char source[51];
char eventDescription[51];
int priority;
int severity;
};
Source および EventDescription フィールドは、構造体では 51 文字ですが、上のスクリーンショットでは 50 文字を保持していることに注目してください。構造体で 51 文字を取る理由は、文字列のヌル終端文字用の領域を確保するためです。文字列の最後の文字はバイナリ 0 である必要があるため、フィールドのサイズが 50 に設定された場合、フィールドには 49 文字までしか保持されず、最後の文字はヌル終端文字の値になります。
Btrieve 2 を使用してこれらのイベントの 1 つをファイルに書き込むには、ファイルを開き、レコードを書き込んでから、ファイルを閉じます。
void writeEvent(Event* event)
{
BtrieveClient btrieveClient;
BtrieveFile btrieveFile;
btrieveClient.FileOpen(&btrieveFile, FILE_NAME, NULL, Btrieve::OPEN_MODE_NORMAL);
btrieveFile.RecordCreate((char*)&event, sizeof(event));
btrieveClient.FileClose(&btrieveFile);
btrieveClient.Reset();
}
フラット ファイルの例では、ファイルから単一レコードを読み取るカスタム関数を定義しました。しかし、Btrieve 2 API には、レコードを読み取るための関数が既に含まれています。フラット ファイルの例で整数値を解析するために必要とした関数呼び出しは、この例ではもう必要ないためなくなっていることに注目してください。次のコードは、ログ全体を読み取ります。
void readAllRecords(BtrieveFile& btrieveFile,vector<Event>& eventList )
{
Btrieve::StatusCode status;
Event event;
int bytesRead = btrieveFile.RecordRetrieveLast(Btrieve::INDEX_NONE,
(char*)&event, sizeof(Event));
while (status == Btrieve::STATUS_CODE_NO_ERROR )
{
eventList.push_back(event);
btrieveFile.RecordRetrievePrevious((char*)&event, sizeof(event));
status = btrieveFile.GetLastStatusCode();
}
}
void openAndReadLogFile()
{
BtrieveClient btrieveClient;
Btrieve::StatusCode status;
BtrieveFile btrieveFile;
Event event;
status = btrieveClient.FileOpen(&btrieveFile, FILE_NAME, NULL,
Btrieve::OPEN_MODE_NORMAL);
if (status != Btrieve::STATUS_CODE_NO_ERROR)
return;
vector<Event> eventList;
readAllRecords(btrieveFile, eventList);
btrieveClient.FileClose(&btrieveFile);
}
ログからの読み取りが簡単になっただけでなく、ログ内からレコードを見つけることも非常に簡単になりました。Btrieve 2 API には、ファイルのインデックスを作成する機能が含まれています。ファイルがインデックス付けされると、検索操作やフィルタリング操作を少ないコードでより効率的に実行できます。インデックスは、必要に応じてコードで作成することができます。
インデックスが役に立つシナリオを考えてみましょう。重要度が最も高いイベントの上位 20 を取得する必要があるとします。これを行う 1 つの方法は、重要度(severity)フィールドに基づいてインデックスを作成することです。2 つのイベントの重要度が同じである場合は、優先度(priority)の高い方が先に返されるようにします。これら 2 つのフィールドに基づいてインデックスを作成します。
インデックスには、インデックス番号を割り当てる必要があります。インデックスを使用する場合は、割り当てられている番号によってインデックスを選択します。INDEX_1 は、この例において ID フィールドで既に使用されているため、使用できる値は INDEX_2 から INDEX_119 までが残っています。次のコードは、severity フィールドと priority フィールドにインデックスを作成します。最も高い値が最初に返されるようにするため、インデックスで使用されるフィールドは降順を使用するように設定されています。
void createSeverityIndex(BtrieveFile& btrieveFile, Btrieve::Index indexNumber)
{
BtrieveIndexAttributes severityIndexAttributes;
BtrieveKeySegment severityKeySegment, priorityKeySegment;
Btrieve::StatusCode status;
severityKeySegment.SetField(108,4,Btrieve::DATA_TYPE_INTEGER);
severityKeySegment.SetDescendingSortOrder(true);
severityIndexAttributes.AddKeySegment(&severityKeySegment);
priorityKeySegment.SetField(104, 4, Btrieve::DATA_TYPE_INTEGER);
priorityKeySegment.SetDescendingSortOrder(true);
severityIndexAttributes.AddKeySegment(&priorityKeySegment);
btrieveFile.IndexCreate(&severityIndexAttributes);
}
わずかな変更だけで、データ ファイルからすべてのレコードを読み取るために使用したコードが、最も重要な 20 のイベントを取得するようになりました。変更されたバージョンでは、並べ替えで使用するインデックス番号は引数で渡されるようになりました。最初のレコードを読み取るために呼び出しが行われるときに、このインデックス番号が使用されます。
この関数の前のバージョンでは、インデックスは INDEX_NONE に設定されていたため、特定の順序で取得されませんでした。現在、レコードは定義された順序で取得されます。留意する点は、並べ替えコードを何も書く必要がなかったということです。
void readMostSevereRecords(BtrieveFile& btrieveFile, vector<Event> eventList, Btrieve::Index index)
{
Btrieve::StatusCode status;
Event event;
int bytesRead = btrieveFile.RecordRetrieveFirst(index, (char*)&event, sizeof(Event));
while (status == Btrieve::STATUS_CODE_NO_ERROR && eventList.size()<20)
{
eventList.push_back(event);
btrieveFile.RecordRetrieveNext((char*)&event, sizeof(event));
status = btrieveFile.GetLastStatusCode();
}
}
複数の並べ替え順を処理する必要がある場合は、ファイルに複数のインデックスを作成することができます。インデックスを使用して逆順でレコードを取得するには、RecordRetrieveFirst および RecordRetrieveNext 関数の代わりに RecordRetrieveLast および RecordRetrievePrevious 関数を使用します。
インデックスはもう必要ないと判断した場合、インデックスを削除するには、BtrieveFile::IndexDrop の関数呼び出し 1 つだけです。インデックスは、いつでも既存のデータ ファイルに作成したり、ファイルから削除したりすることができます。いったん作成されると、後続のすべての CRUD 操作で自動的に保持されます。
フラット ファイルと同様に、Zen データ ファイルへのアクセスは、オペレーティング システムのファイルのアクセス許可を使用して制限することができます。また、Zen データ ファイルではファイルの暗号化(SetOwner() を参照)を使用して、不正アクセスからの別の保護レイヤーをファイルに提供することができます。
まとめ
ログのソリューションに Zen データベースを使用することには、いくつかの利点があります。
- データ ファイルに記録される情報は、異なる解釈があるかもしれないテキストとして書き込まれるのではなく、厳密に型指定されます。
- データ ファイルからデータを読み取るときに、データを解析する必要はありません。
- プログラムは、Zen でサポートされる Btrieve 2 API、ODBC、または任意のアクセス方法を使用して、関心のある情報や注文した情報のエントリを迅速に見つけることができます。
- セキュリティ、暗号化、ACID、およびすべての標準のデータ管理機能をログに記録されたデータで利用できます。
Btrieve 2 クラスの詳細については、Btrieve 2 API ページを参照してください。Btrieve 2 SDK をダウンロードするには、Btrieve SDK ページをご覧ください。