データベースの設計
以下のトピックでは、データベースを設計するための形式とガイドラインを示します。
データ ファイルについて
MicroKernel エンジンは、情報をデータ ファイルに保存します。各データ ファイル内には、レコードとインデックスの集合があります。レコードにはデータのバイトが格納されています。そのデータは、社員の名前、ID、住所、電話番号、賃率などを表します。インデックスは、レコードの一部に特定の値を含むレコードをすばやく見つける働きがあります。
MicroKernel エンジンは、レコードを単なるバイトの集合と解釈します。これは、レコード内の情報で論理的に区別される部分、つまり、フィールドを認識しません。MicroKernel エンジンにおいては、ラスト ネーム、ファースト ネーム、社員 ID などはレコード内に存在しません。レコードは単にバイトの集合にすぎません。
MicroKernel エンジンはバイト指向であるため、たとえデータ型を宣言するキーに対してでも、レコード内のデータの変換、型検査、または妥当性検査を行いません。データ ファイルとインターフェイスをとるアプリケーションは、そのファイル内のデータの形式と型に関するすべての情報を処理する必要があります。たとえば、アプリケーションは以下の形式に基づいてデータ構造を使用します。
レコード内の情報 | 長さ(バイト単位) | データ型 |
|---|---|---|
ラスト ネーム | 25 | ヌル終了文字列 |
ファースト ネーム | 25 | ヌル終了文字列 |
ミドル イニシャル | 1 | Char(バイト) |
社員 ID | 4 | Long(4 バイト整数) |
電話番号 | 13 | ヌル終了文字列 |
月給 | 4 | Float |
合計レコード長 | 72 バイト | |
ファイル内では、社員のレコードがバイトの集合として格納されます。以下のダイアグラムは、Cliff Jones のレコードのデータがファイルに格納されるときの状態を示したものです。(このダイアグラムは、文字列の ASCII 値を対応する英字または数字に置き換えています。整数とほかの数値は、正規 16 進表現から変更されていません。)
バイト位置 | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 0A | 0B | 0C | 0D | 0E | 0F |
データ値 | J | o | n | e | s | 00 | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
バイト位置 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 1A | 1B | 1C | 1D | 1E | 1F |
データ値 | ? | ? | ? | ? | ? | ? | ? | ? | ? | C | l | i | f | f | 00 | ? |
バイト位置 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 2A | 2B | 2C | 2D | 2E | 2F |
データ値 | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
バイト位置 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 3A | 3B | 3C | 3D | 3E | 3F |
データ値 | ? | ? | D | 2 | 3 | 4 | 1 | 5 | 1 | 2 | 5 | 5 | 5 | 1 | 2 | 1 |
バイト位置 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | ||||||||
データ値 | 2 | ? | ? | ? | 3 | 5 | 0 | 0 |
MicroKernel エンジンがファイル内で認識する情報で区別する唯一の部分はキーです。アプリケーション(またはユーザー)はレコード内のバイトの 1 つまたは複数の集合をキーとして指定できますが、バイトと各キー セグメント内で連続していなければなりません。
MicroKernel エンジンは指定されたキーの値に基づいてレコードをソートし、特定の順序でデータを返すための直接アクセスを行います。MicroKernel エンジンは、指定されたキー値に基づいて特定のレコードも検索できます。前の例では、各レコード内のラスト ネームを含む 25 バイトをファイル内のキーとして指定できます。アプリケーションはラスト ネームのキーで Smith という名前の全社員のリストを取得したり、全社員のリストの取得後にラスト ネームでソートされたそのリストを表示したりすることができます。
キーを使用すると、MicroKernel エンジンは情報にすばやくアクセスできます。MicroKernel エンジンは、データ ファイルで定義されたキーごとにインデックスを作成します。インデックスはデータ ファイル自体の中に格納され、そのファイル内の実際のデータへのポインターの集合が含まれています。キーの値は各ポインターに関連付けられています。
前の例では、ラスト ネーム キーのインデックスがラスト ネーム値をソートし、レコードがデータ ファイル内のどこにあるかを示すポインターを持っています。 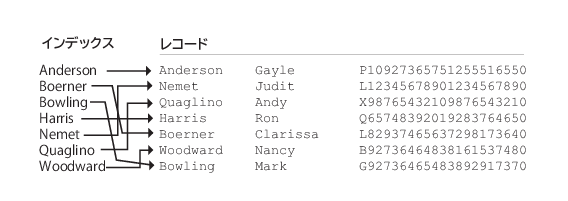
通常、アプリケーションが情報にアクセスしたり、情報をソートする場合、MicroKernel エンジンはデータ ファイル内のすべてのデータを検索するわけではありません。その代わり、インデックスを使用して検索を行い、アプリケーションの要求を満たすレコードだけを処理します。
データ ファイルの作成
MicroKernel エンジンは、データベース アプリケーションを最適化する際の大きな柔軟性を開発者に与えてくれます。そのような柔軟性を提供するため、MicroKernel エンジンは、MicroKernel エンジンの内部処理の多くを公開しています。MicroKernel エンジンを初めて使用する場合、Create(14)オペレーションは非常に複雑に見えるかも知れませんが、作業の開始にあたってはこのオペレーションのすべての機能を必要とするわけではありません。ここでは、簡単なトランザクション ベースのデータ ファイルの作成を段階的に行うことで、基本的な条件に焦点を当てます。ここでは、必要に応じて簡素化を図るために、C インターフェイスの用語を使用します。
メモ: 同じディレクトリに、ファイル名が同一で拡張子のみが異なるようなファイルを置かないでください。たとえば、同じディレクトリ内のデータ ファイルの 1 つに invoice.btr、もう 1 つに invoice.mkd という名前を付けてはいけません。このような制限が設けられているのは、データベース エンジンがさまざまな機能でファイル名のみを使用し、ファイルの拡張子を無視するためです。ファイルの識別にはファイル名のみが使用されるため、ファイルの拡張子だけが異なるファイルは、データベース エンジンでは同一のものであると認識されます。
データ レイアウト
ここでは、社員レコードを格納するデータ ファイルの例を使用します。アプリケーションは、一意の社員 IDまたは社員のラスト ネームを指定して社員情報を取得します。複数の社員が同じラスト ネームを持っている可能性があるので、データベースではラスト ネームの重複値を許します。これらの条件に基づくと、ファイルのデータ レイアウトは次の表のようになります。
レコード内の情報 | データ型 | キーまたはインデックスの特性 |
|---|---|---|
ラスト ネーム | 25 文字の文字列 | 重複可能 |
ファースト ネーム | 25 文字の文字列 | なし |
ミドル イニシャル | 1 文字の文字列 | なし |
社員 ID | 4 バイト整数 | 重複不可 |
電話番号 | 13 文字の文字列 | なし |
月給 | 4 バイト浮動小数 | なし |
基本的なデータ レイアウトを設定したので、MicroKernel エンジンの用語と条件の適用を開始できます。この場合、実際にファイルを作成する前にキー構造とファイル構造に関する情報を決定します。これらの詳細情報を事前に処理しておかなければならないのは、Create(14)オペレーションがファイル情報、インデックス情報、キー情報をすべて一度に作成するからです。以降では、これらの詳細情報を処理する際に考慮しなければならない問題について説明します。
キー属性
まず、キーの特別な機能を決定します。以下の表に示すように、MicroKernel エンジンにはさまざまなキー属性があり、必要に応じ割り当てることができます。
定数 | 説明 |
|---|---|
EXTTYPE_KEY | 拡張データ型。文字列または符号なしバイナリ以外の MicroKernel エンジン データ型を格納します。標準バイナリ データ型よりもこの属性を使用してください。このキー属性には、標準バイナリおよび文字列データ型のほかに多数の属性を収容できます。 |
BIN | 標準バイナリ データ型。今日までの経緯によりサポートされます。符号なし 2 進数を格納します。デフォルトのデータ型は文字列です。 |
DUP | リンク重複。ポインターでインデックス ページからデータ ページへリンクされる重複値を許します。詳細については、重複キーを参照してください。 |
REPEAT_DUPS_KEY | 繰り返し重複。インデックス ページとデータ ページの両方に格納される重複値を許します。詳細については、重複キーを参照してください。 |
MOD | 変更可能。レコードの挿入後にキー値の変更を行えます。 |
SEG | セグメント化。このキーが、現在のキー セグメントの後にセグメントを持つことを指定します。 |
NUL | ヌル キー(すべてのセグメント)。指定されたヌル値がキーのすべてのセグメントに含まれている場合は、インデックスからすべてのレコードを除外します(ファイルを作成するときにヌル値を指定します)。 |
MANUAL_KEY | ヌル キー(任意のセグメント)。指定されたヌル値がキーの任意のセグメントに含まれている場合は、インデックスからすべてのレコードを除外します(ファイルを作成するときにヌル値を指定します)。 |
DESC_KEY | 降順のソート順序。キー値を降順(最大から最小へ)に並べます。デフォルトは昇順(最小から最大へ)です。 |
NOCASE_KEY | 大文字と小文字の区別。大文字と小文字を区別せずに文字列値をソートします。キーにオルタネート コレーティング シーケンス(ACS)がある場合は使用しないでください。ヌル インジケーター セグメントの場合、この属性はオーバーロードされて、ゼロ以外のヌル値を明確に区別する必要があることを示します。 |
ALT | オルタネート コレーティング シーケンス。照合順序を使用して、標準の ASCII シーケンスとは異なる方法で文字列キーをソートします。キーごとに異なる照合順序を使用できます。デフォルト ACS(ファイル内で定義された最初の ACS)、ファイル内で定義された番号付き ACS、または、collate.cfg システム ファイルで定義された名前付き ACS を指定できます。 |
NUMBERED_ACS | |
NAMED_ACS | |
簡素化を図るために、これらの定数は btrconst.h で定義され、C インターフェイスに合致しています。インターフェイスの中には、ほかの名前を使用したり、定数をまったく使用しないものがあります。ビット マスク、キー属性の 16 進値および 10 進値については、『Btrieve API Guide』を参照してください。 | |
定義するキーごとに、これらのキー属性を指定します。各キーは独自のキー仕様を持ちます。キーに複数のセグメントがある場合は、セグメントごとに仕様を提供する必要があります。これらの属性のいくつかは、同じキー内の異なるセグメントに対して異なる値を持つことができます。前の例で、キーはラスト ネームおよび社員 ID です。どちらのキーも拡張型を使用します。つまり、ラスト ネームは文字列、社員 ID は整数です。両方とも変更可能ですが、ラスト ネームだけは重複可能です。また、ラスト ネームは大文字と小文字を区別します。
キーに割り当てるデータ型に関して、MicroKernel エンジンは、入力レコードがそのキーに対し定義されたデータ型に従っているかどうかを確認しません。たとえば、ファイルに TIMESTAMP キーを定義して、そこに文字列を格納したり、DATE キーを定義して 2 月 30 日という値を格納したりすることもあり得ます。お使いの MicroKernel エンジン アプリケーションは問題なく機能しますが、同じデータにアクセスしようとする ODBC アプリケーションではうまくいかない可能性があります。それは、バイト形式が異なり、タイムスタンプ値を生成するためのアルゴリズムが異なるためです。データ型の説明については、『SQL Engine Reference』を参照してください。
ファイル属性
次に、ファイルの特別な機能を決定します。
以下の表に示すように、MicroKernel エンジンではさまざまな種類のファイル属性が指定できます。
定数 | 説明 |
|---|---|
VAR_RECS | 可変長レコード。可変長レコードを含むファイルで使用します。 |
BLANK_TRUNC | ブランク トランケーション。レコードの可変長部分の末尾の空白を削除することによって、ディスク領域を節減します。可変長のレコードを許し、かつデータ圧縮機能を使用しないファイルにのみ適用できます。詳細については、ブランク トランケーションを参照してください。 |
PRE_ALLOC | ページ プリアロケーション。ファイルの作成時にファイルで使用される連続ディスク領域を予約します。ファイルがディスク上の連続する領域を占有する場合、ファイル操作を高速化することができます。速度の向上は、非常に大きなファイルで最も顕著です。詳細については、ページ プリアロケーションを参照してください。 |
DATA_COMP | データ圧縮。レコードを挿入または更新する前に圧縮し、レコードの取得時に解凍します。詳細については、レコード圧縮を参照してください。 |
KEY_ONLY | キーオンリー ファイル。キーを 1 つだけ含み、レコード全体がそのキーと共に格納されるため、データ ページは不要です。キーオンリー ファイルは、レコードに単一のキーが含まれており、かつそのキーが各レコードの大部分を占有している場合に有効です。詳細については、キーオンリー ファイルを参照してください。 |
BALANCED_KEYS | インデックス バランス。いっぱいになったインデックス ページから領域が空いているインデックス ページへ値を振り分けます。インデックス バランスは読み取り操作でのパフォーマンスを高めますが、書き込み操作では余計な時間がかかる場合があります。詳細については、インデックス バランスを参照してください。 |
FREE_10 FREE_20 FREE_30 | 空きスペース スレッショルド。可変長レコードを削除して空いたディスク領域を再利用するためのスレッショルド パーセンテージを設定することで、ファイルを認識する必要がなくなり、数ページにわたる可変長レコードの断片化を減らします。 空きスペース スレッショルドが大きいと、レコードの可変長部分の断片化が減少しパフォーマンスが向上します。ただし、ディスク領域がさらに必要になります。パフォーマンスを高くしたいときは、空きスペース スレッショルドを 30 パーセントに増やします。 |
DUP_PTRS | 重複ポインターを予約します。将来追加するリンク重複キーにポインター スペースをプリアロケートします。リンク重複キーを作成するための重複ポインターがない場合、MicroKernel エンジンは繰り返し重複キーを作成します。 |
INCLUDE_SYSTEM_DATA | システム データ。ファイル作成時にシステム データを取り込むことによって、MicroKernel エンジンがファイルにログオンして処理を行うことを許可します。これは、一意のキーを含まないファイルで有効です。 |
NO_INCLUDE_SYSTEM_DATA | |
SPECIFY_KEY_NUMS | キー番号。MicroKernel エンジンが番号を自動的に割り当てるのではなく、特定の番号をキーに割り当てることができます。アプリケーションによっては、特定のキー番号を必要とするものがあります。 |
VATS_SUPPORT | 可変長部割り当てテーブル(VAT)。VAT(レコードの可変長部分へのポインターの配列)を使用して、ランダム アクセスを加速化したり、データ圧縮時に使用される圧縮バッファーのサイズを制限します。詳細については、可変長部割り当てテーブルを参照してください。 |
簡素化を図るために、これらの定数は btrconst.h で定義され、C インターフェイスに合致しています。インターフェイスの中には、ほかの名前を使用したり、定数をまったく使用しないものがあります。ビット マスク、ファイル属性の 16 進値および 10 進値については、『Btrieve API Guide』を参照してください。 | |
データ ファイルの例でこれらのファイル属性を使用していないのは、レコードが小さなサイズの固定長レコードであるからです。
ファイル属性の定義については、ファイル タイプを参照してください。Create オペレーションにおけるファイル属性の指定方法の詳細については、『Btrieve API Guide』を参照してください。
ファイル仕様およびキー仕様の構造体の作成
Create オペレーションを使用する場合は、ファイルとキーの仕様情報をデータ バッファーに渡します。
BTRV エントリ ポイントを使用する、ファイル仕様およびキー仕様のサンプル データ バッファー
以下の構造体では、社員データ ファイルの例を使用します。
説明 | データ型1 | バイト番号 | 値の例2 | ||
|---|---|---|---|---|---|
ファイル仕様 | |||||
論理固定レコード長(結合されたすべてのフィールドのサイズ:25 + 25 + 1 + 4 + 13 + 4)。手順については、論理レコード長の計算を参照してください。3 | Short Int4 | 0 - 1 | 72 | ||
ページ サイズ。 | ファイル形式 | Short Int | 2 - 3 | ||
6.0-9.0 | 512 | ||||
6.0 以上 | 1024 | ||||
6.0-9.0 | 1536 | ||||
6.0 以上 | 2048 | ||||
6.0-9.0 | 3072 | ||||
3584 | |||||
6.0 以上 | 4096 | ||||
9.0 以上 | 8192 | ||||
9.5 以上 | 16384 | ||||
ほとんどのファイルでは最小サイズの 4096 バイトが最も効率的です。微調整を行う場合の詳細については、ページ サイズの選択を参照してください。 6.0 から 8.0 のファイル形式ではページ サイズ 512 の x 倍をサポートします。x は乗算の値が 4096 以下になる数字です。 9.0 ファイル形式ではページ サイズ 8192 もサポートすることを除けば、以前のバージョンと同じページ サイズをサポートします。 9.5 ファイル形式では、ページ サイズ 1024 の 20 倍から 24 倍をサポートします。 9.5 形式のファイルを作成する場合、指定された論理ページ サイズがそのファイル形式で有効ならば、MicroKernel は指定値の次に大きな有効値があるかどうかを調べ、存在する場合はその値に切り上げます。それ以外の値やファイル形式の場合、オペレーションはステータス 24 で失敗します。古いバージョンのファイル形式では、切り上げは行われません。 | |||||
キー数。(ファイル内のキー数:2) | Byte | 4 | 2 | ||
ファイル バージョン | Byte | 5 | 0x60 | バージョン 6.0 | |
0x70 | バージョン 7.0 | ||||
0x80 | バージョン 8.0 | ||||
0x90 | バージョン 9.0 | ||||
0x95 | バージョン 9.5 | ||||
0xD0 | バージョン 13.0 | ||||
0xD3 | バージョン 16.0 | ||||
0x00 | データベース エンジンのデフォルトを使用 | ||||
予約済み(Create オペレーションでは使用しません。) | 予約済み | 6 - 9 | 0 | ||
ファイル フラグ。ファイル属性を指定します。ファイルの例では、ファイル フラグを使用していません。 | Short Int | 10 - 11 | 0 | ||
追加ポインター数。将来のキーの追加のために予約する重複ポインター数を設定します。ファイル属性で予約重複ポインターを指定する場合に使用します。 | Byte | 12 | 0 | ||
物理ページ サイズ。圧縮フラグが設定されている場合に使用されます。値は、512 バイト ブロックの数です。 | Byte | 13 | 0 | ||
プリアロケート ページ数。事前に割り当てられるページ数を設定します。ファイル属性でページ プリアロケーションを指定する場合に使用します。 | Short Int | 14 - 15 | 0 | ||
キー 0(ラスト ネーム)のキー仕様 | |||||
キー ポジション。レコード内のキーの最初のバイトの位置を指定します。レコード内の最初のバイトは 1 です。 | Short Int | 16 - 17 | 1 | ||
キー長。バイト単位でキーの長さを指定します。 | Short Int | 18 - 19 | 25 | ||
キー フラグ。キー属性を指定します。 | Short Int | 20 - 21 | EXTTYPE_KEY + NOCASE_KEY + DUP + MOD | ||
Create には使用しません。 | Byte | 22 - 25 | 0 | ||
拡張キー タイプ。キー フラグで「拡張キー タイプを使用する」を指定する場合に使用します。拡張データ型のうちの 1 つを指定します。 | Byte | 26 | ZSTRING | ||
ヌル値(レガシー ヌルのみ)。キー フラグで「ヌルキー(全セグメント)」または「ヌルキー(一部セグメント)」を指定する場合に使用されます。キーの除外値を指定します。レガシー ヌルと真のヌルの概念については、ヌル値を参照してください。 | Byte | 27 | 0 | ||
Create には使用しません。 | Byte | 28 - 29 | 0 | ||
手動割り当てキー番号。ファイル属性で「キー番号」を指定する場合に使用します。キー番号を割り当てます。 | Byte | 30 | 0 | ||
ACS 番号。キー フラグで「デフォルトの ACS を使用する」、「ファイル内の番号付きの ACS を使用する」または「名前付きの ACS を使用する」を指定する場合に使用されます。使用する ACS 番号を指定します。 | Byte | 31 | 0 | ||
キー 1(社員 ID)のキー仕様 | |||||
キー ポジション。(社員 ID は、ミドル イニシャルの後の最初のバイトから始まります。) | Short Int | 32 - 33 | 52 | ||
キー長。 | Short Int | 34 - 35 | 4 | ||
キー フラグ。 | Short Int | 36 - 37 | EXTTYPE_KEY + MOD | ||
Create には使用しません。 | Byte | 38 - 41 | 0 | ||
拡張キー タイプ。 | Byte | 42 | INTEGER | ||
ヌル値。 | Byte | 43 | 0 | ||
Create には使用しません。 | Byte | 44 - 45 | 0 | ||
手動割り当てキー番号。 | Byte | 46 | 0 | ||
ACS 番号。 | Byte | 47 | 0 | ||
ページ圧縮のキー仕様 | |||||
物理ページ サイズ5 | Char | A | 512 (デフォルト値) | ||
1 特に指定がない場合、すべてのデータ型は符号なしです。 2 簡素化を図るため、数値以外の値の例は C アプリケーションの場合です。 3 可変長レコードを持つファイルの場合、論理レコード長はレコードの固定長部分のみを指します。 4 Short Integer(Short Int)は「リトル エンディアン」のバイト順、つまり、Intel 系のコンピューターが採用している下位バイトから上位バイトへ記録する方式で格納する必要があります。 | |||||
ページ レベル圧縮を用いたファイルの作成
PSQL 9.5 以上では、Create(14)を使用してページ レベルの圧縮を用いたデータ ファイルを作成することができます。古いバージョンのデータ ファイルの場合は、論理ページを物理ページに割り当て、この割り当てをページ アロケーション テーブル(PAT)に格納します。物理ページのサイズは論理ページのサイズと同一です。
ファイルが圧縮されると、各論理ページが 1 つ以上の物理ページ単位に圧縮され、そのサイズは 1 論理ページよりも小さくなります。物理ページのサイズは、ファイル仕様およびキー仕様の構造体の作成で説明されている「物理ページ サイズ」属性によって指定されます。
ページ圧縮ファイル フラグ(キー フラグの値を参照)は物理ページ サイズのキー仕様と組み合わせて使用され、ページ レベルの圧縮を適用したデータ ファイルを新規作成するよう MicroKernel へ通知します。論理ページ サイズと物理ページ サイズは次のように検証されます。
物理ページ サイズに指定された値は、論理ページ サイズに指定された値よりも大きくすることはできません。物理ページ サイズに指定された値の方が大きい場合、MicroKernel は論理ページ サイズと同じになるようその値を切り捨てます。論理ページ サイズは物理ページ サイズの倍数になっていなければなりません。倍数でない場合、その論理ページ サイズの値は物理ページ サイズの値のちょうど倍数になるよう切り捨てられます。このような操作の結果として、論理ページ サイズと物理ページ サイズの値が同じになった場合、ページ レベルの圧縮はこのファイルに適用されません。
Create オペレーションの呼び出し
Create(14)では、以下の値が必要です。
• オペレーション コード。Create の場合は 14 。
• ファイル仕様とキー仕様が含まれているデータ バッファー。
• データ バッファーの長さ。
• ファイルの絶対パスが含まれているキー バッファー。
• 同じ名前のファイルが既に存在する場合に、MicroKernel エンジンが警告を出すかどうか(-1 = 警告、0 = 警告なし)を決定するための値が含まれているキー番号。
C における API 呼び出しは次のようになります。
Create オペレーション
/* データ バッファー構造体の定義 */
/*以下の 3 つの構造体は、1 バイトのフィールドのアライメントを持っている必要があります。これは、コンパイラのプラグマを介して、またはコンパイラ オプションを介して行うことができます。*/
typedef struct
{
BTI_SINT recLength;
BTI_SINT pageSize;
BTI_SINT indexCount;
BTI_CHAR reserved[4];
BTI_SINT flags;
BTI_BYTE dupPointers;
BTI_BYTE notUsed;
BTI_SINT allocations;
} FILE_SPECS;
typedef struct
{
BTI_SINT position;
BTI_SINT length;
BTI_SINT flags;
BTI_CHAR reserved[4];
BTI_CHAR type;
BTI_CHAR null;
BTI_CHAR notUsed[2];
BTI_BYTE manualKeyNumber;
BTI_BYTE acsNumber;
} KEY_SPECS;
typedef struct
{
FILE_SPECS fileSpecs;
KEY_SPECS keySpecs[2];
} FILE_CREATE_BUF;
/* データ バッファーの作成 */
FILE_CREATE_BUF dataBuf;
memset (dataBuf, 0, size of (dataBuf)); /* dataBuf の初期化 */
dataBuf.recLength = 72;
dataBuf.pageSize = 4096;
dataBuf.indexCount = 2;
dataBuf.keySpecs[0].position = 1;
dataBuf.keySpecs[0].length = 25;
dataBuf.keySpecs[0].flags = EXTTYPE_KEY + NOCASE_KEY + DUP + MOD;
dataBuf.keySpecs[0].type = ZSTRING;
dataBuf.keySpecs[1].position = 52;
dataBuf.keySpecs[1].length = 4;
dataBuf.keySpecs[1].flags = EXTTYPE_KEY;
dataBuf.keySpecs[1].type = INTEGER;
/* ファイルの作成 */
strcpy((BTI_CHAR *)keyBuf, "c:\\sample\\sample2.mkd");
dataLen = sizeof(dataBuf);
status = BTRV(B_CREATE, posBlock, &dataBuf, &dataLen, keyBuf, 0);
Create Index オペレーション
あらかじめキーが定義されているファイルを作成すると、挿入、更新、または削除のたびにインデックスにデータが設定されます。これは、ほとんどのデータベース ファイルに必要です。しかし、読み取る前にデータが完全に取り込まれる類のデータベース ファイルがあります。これらには、テンポラリ ソート ファイルや、製品の一部として提供されるデータ実装済みのファイルが挙げられます。
このようなファイルの場合、レコードが書き込まれた後に Create Index(31)でキーを作成する方が処理が速くなる可能性があります。レコードの挿入をより速く実行できるように、インデックスを定義せずにファイルを作成する必要があります。その後、Create Index オペレーションによって、より効率的な方法でキーをソートし、インデックスを作成します。
このように作成されたインデックスは効率も良く、高速なアクセスができます。インデックス ページはキー順に読み込まれるので、Create Index(31)の実行時、MicroKernel エンジンは各ページの終わりに空き領域を残す必要がありません。各ページは、100% 近くまでレコードが書き込まれます。それに対して、Insert(2)または Update(3)オペレーションでインデックス ページにレコードを書き込む場合、インデックス ページは半分に分割され、レコードの半分は新しいページにコピーされます。このプロセスにより、平均的なインデックス ページは約 50~65% まで満たされます。インデックス バランスを使用すると、65 ~ 75% まで満たされる場合があります。
Create Index(31)のもう 1 つの利点として、作成された新しいインデックス ページはすべてファイルの終わりにまとめて書き込まれます。これは、大きなファイルの場合、読み取り処理間で読み取りヘッドの移動距離が短くなるということです。
この手法では、レコードが数千件しかない小さなファイルの場合、処理速度が上がらない可能性があります。このオペレーションの利点を生かすには、ファイルにさらに大きなインデックス フィールドが必要になります。さらに、すべてのインデックス ページを MicroKernel エンジン キャッシュに収容できる場合、この手法では速度は向上しません。しかし、常にインデックス ページのほんの一部しかキャッシュ内にないのであれば、多くの余分なインデックス ページの書き込みが省かれます。この技術により、多くのレコードを持つファイルの構築に必要となる時間を大幅に短縮することができます。Create Index(31)では、ファイル内のインデックス ページ数が多いほど、一度に 1 レコードずつ挿入する場合よりも高速にインデックスを作成できます。
つまり、Zen ファイルを最初から読み込む場合、すべてのインデックス ページを保持するためのキャッシュ メモリが不足することを避けることが重要です。その場合は、Create(14)を使用してインデックスを付けずにファイルを作成し、すべてのデータ レコードが挿入されたときに Create Index(31)を使用します。
これらのオペレーションの詳細については、『Btrieve API Guide』を参照してください。
論理レコード長の計算
Create(14)に論理レコード長を適用する必要があります。論理レコード長は、ファイル内の固定長データのバイト数です。この値を算出するには、各レコードの固定長部分に格納しなければならないデータのバイト数を計算します。
たとえば、以下の表は、社員ファイル例のデータ バイトをどのように合計して論理レコード長を算出するかを示しています。
フィールド | 長さ(バイト単位) |
|---|---|
ラスト ネーム | 25 |
ファースト ネーム | 25 |
ミドル イニシャル | 1 |
社員 ID | 4 |
電話番号 | 13 |
賃率 | 4 |
論理レコード長 | 72 |
論理レコード長を計算する際に、可変長データをカウントしないのは、可変長の情報がファイル内の固定長レコードから離れて(可変ページ上に)格納されるからです。
次の表に定義されているように、最大論理レコード長はファイル形式によって異なります。
Zen バージョン | 例 |
|---|---|
13.0、16.0 | ページ サイズ - 18 - 2(レコード オーバーヘッド) |
9.5 | ページ サイズ - 10 - 2(レコード オーバーヘッド) |
8.x から 9.x | ページ サイズ - 8 - 2(レコード オーバーヘッド) |
6.x から 7.x | ページ サイズ - 6 - 2(レコード オーバーヘッド) |
v6.x より前 | ページ サイズ - 6 - 2(レコード オーバーヘッド) |
メモ:上記の例に示したレコード オーバーヘッドは、圧縮を使用しない(可変長レコードでははく)固定長レコード用です。 | |
ページ サイズの選択
データ ファイル内のすべてのページは同じサイズです。したがって、ファイル内のページのサイズを決定するときは、以下の問題に答える必要があります。
• 無駄にされるバイトを減らすためにレコードの固定長部分を保持するデータ ページの最適なサイズはいくつでしょうか。
• インデックス ページに最長のキー定義を保持できる最小サイズはいくつでしょうか(たとえファイルにキーを定義しない場合でも、トランザクション一貫性保持機能を有効にした場合、MicroKernel エンジンはキーを追加します)。
以下のトピックでは、これらの問題の答えを導き出す方法を説明します。得られた解答で、ファイルに最も合うページ サイズを選択できます。
ディスク領域を最小限にするための最適なページ サイズ
ファイルの最適なページ サイズを決定する前に、まずファイルの物理レコード長を計算する必要があります。物理レコード長は、論理レコード長とファイルのデータ ページ上にレコードを格納するのに必要なオーバーヘッドとの合計です。ページ サイズの一般的な情報については、ページ サイズを参照してください。
MicroKernel エンジンは常に、すべてのレコードに最低 2 バイトのオーバーヘッド情報をそのレコードの使用量カウントとして格納しています。また、MicroKernel エンジンは、ファイル内でのレコードとキーの定義方法により、各レコード内に追加バイトを格納します。
レコードの圧縮を使用しない場合のレコード オーバーヘッドのバイト数
次の表は、レコードの圧縮を使用しない場合、ファイルの特性によってレコード オーバーヘッドが何バイト必要になるかを示します。
ファイルの特性 | ファイル形式 | |||
|---|---|---|---|---|
6.x | 7.x | 8.x | 9.0、9.5、13.0、16.0 | |
使用回数 | 2 | 2 | 2 | 2 |
重複キー(キーごとに) | 8 | 8 | 8 | 8 |
可変ポインター(可変長レコード) | 4 | 4 | 6 | 6 |
レコード長(VAT1 を使用する場合) | 4 | 4 | 4 | 4 |
ブランク トランケーションの使用(VAT 不使用/VAT 使用) | 2/4 | 2/4 | 2/4 | 2/4 |
システム データ | N/A2 | 8 | 8 | 8 |
1 VAT:可変長部割り当てテーブル 2 N/A:適用外 | ||||
レコードの圧縮を使用した場合のレコード オーバーヘッドのバイト数
次の表は、レコードの圧縮を使用する場合、ファイルの特性によってレコード オーバーヘッドが何バイト必要になるかを示します。
ファイルの特性 | ファイル形式 | |||
|---|---|---|---|---|
6.x | 7.x | 8.x | 9.0、9.5、13.0、16.0 | |
使用回数 | 2 | 2 | 2 | 2 |
重複キー(キーごとに) | 8 | 8 | 8 | 8 |
可変ポインター | 4 | 4 | 6 | 6 |
レコード長(VAT1 を使用する場合) | 4 | 4 | 4 | 4 |
レコード圧縮フラグ | 1 | 1 | 1 | 1 |
システム データ | N/A2 | 8 | 8 | 8 |
1 VAT:可変長部割り当てテーブル 2 N/A:適用外 | ||||
ページ オーバーヘッド(バイト数)
次の表は、ページのタイプに応じて必要となるページ オーバーヘッドのバイト数を示します。
ページのタイプ | ファイル形式 | |||||
|---|---|---|---|---|---|---|
6.x | 7.x | 8.x | 9.0 | 9.5 | 13.0、16.0 | |
データ | 6 | 6 | 8 | 8 | 10 | 18 |
インデックス | 12 | 12 | 14 | 14 | 16 | 24 |
可変 | 12 | 12 | 16 | 16 | 18 | 26 |
物理レコード長のワークシート
次の表は、ファイルのレコードおよびキーがどのように定義されているかに基づいて物理レコード長を算出するために、論理レコード長に追加しなければならないオーバーヘッドのバイト数を示しています。このレコード オーバーヘッド情報の概要については、このトピック内の他の表でも確認できます。
説明 | 例 | |
|---|---|---|
1 | 論理レコード長を算定します。手順については、論理レコード長の計算を参照してください。 このファイルの例では、72 バイトの論理レコードを使用します。可変長レコードを持つファイルの場合、この長さはレコードの固定長部分のみを指します。 | 72 |
2 | レコード使用カウントに 2 を加算します。 圧縮レコードのエントリでは、使用カウント、可変ポインター、レコード圧縮フラグを加算する必要があります。 6.x および 7.x:7 バイト(2 + 4 + 1) 8.x 以降:9 バイト(2 +6 + 1) | 72 + 2 = 74 |
3 | リンク重複キーごとに 8 を加算します。 重複キーのためのバイト数を算出する場合、MicroKernel エンジンは作成時に繰り返し重複として定義されているキーに対して重複ポインター スペースを割り当てません。デフォルトでは、ファイル作成時に作成された重複を許すキーがリンク重複キーです。圧縮レコードのエントリでは、重複キーのポインター用に 9 を加算します。 ファイルの例には、1 つのリンク重複キーがあります。 | 74 + 8 = 82 |
4 | 予約重複ポインターごとに 8 を加算します。ファイルの例には、予約重複ポインターはありません。 | 82 + 0 = 82 |
5 | ファイルが可変長レコードを許可している場合、8.x より前のファイルでは 4 を加算し、8.x 以降のファイルでは 6 を加算します。ファイルの例では、可変長レコードを許可していません。 | 82 + 0 = 82 |
6 | ファイルが VAT を使用している場合、4 を加算します。ファイルの例では、VAT を使用していません。 | 82 + 0 = 82 |
7 | ファイルがブランク トランケーションを使用する場合は、以下のいずれかを加算します。 • ファイルが VAT を使用しない場合、2 を加算します。 • ファイルが VAT を使用する場合、4 を加算します。 ファイルの例では、ブランク トランケーションを使用していません。 | 82 + 0 = 82 |
8 | ファイルがシステム データまたはシステム データ v2 を使用している場合: • システム データの場合は、8 を加算します。 • システム データ v2 の場合は、16 を加算します。 ファイルの例では、システム データを使用していません。 | 82 + 0 = 82 |
物理レコード長 | 82 | |
物理レコード長を使用して、データ ページに対するファイルの最適ページ サイズを決定できます。
MicroKernel エンジンはデータ レコードの固定長部分をデータ ページに格納しますが、固定長部分をページをまたいで分割することはしません。また、MicroKernel エンジンは、ディスク領域を最小限にするための最適なページ サイズで説明されているオーバーヘッド情報を各データ ページに格納します。ページ サイズを決定するときは、この追加のオーバーヘッドを計算する必要があります。
選択したページ サイズからオーバーヘッド情報のバイト数を差し引いたものが物理レコード長の正確な倍数にならない場合、ファイルには未使用領域が含まれています。次の式を使用して、効率のよいページ サイズを見つけることができます。
未使用バイト = (ページ サイズ - データ ページ オーバーヘッド) mod (物理レコード長)
ファイルによるディスク領域の使用量を最適化するには、未使用領域を最小にしてレコードをバッファーに格納できるページ サイズを選択します。サポートされるページ サイズはファイル形式により異なります。最適なページ サイズの例を参照してください。内部レコード長(ユーザー データ + レコード オーバーヘッド)が小さく、ページ サイズが大きいと、無駄な領域がかなりの量になる可能性があります。
最適なページ サイズの例
物理レコード長が 194 バイトの例を考えてみましょう。以下の表に、ページ サイズごとに、ページに格納できるレコード数とページに残る未使用領域のバイト数を示します。
適用可能なファイル形式 | ページ サイズ | 1 ページあたりのレコード数 | 未使用バイト | |
|---|---|---|---|---|
v8.x より前 | 512 | 2 | 118 | (512 - 6) mod 194 |
8.x から 9.0 | 116 | (512 - 8) mod 194 | ||
v8.x より前 | 1024 | 5 | 48 | (1024 - 6) mod 194 |
8.x から 9.0 | 46 | (1024 - 8) mod 194 | ||
9.5 | 44 | (1024 - 10) mod 194 | ||
v8.x より前 | 1536 | 7 | 172 | (1536 - 6) mod 194 |
8.x から 9.0 | 172 | (1536 - 6) mod 194 | ||
v8.x より前 | 2048 | 10 | 102 | (2048 - 6) mod 194 |
8.x から 9.0 | 100 | (2048 - 8) mod 194 | ||
9.5 | 98 | (2048 - 10) mod 194 | ||
v8.x より前 | 2560 | 13 | 32 | (2560 - 6) mod 194 |
8.x から 9.0 | (2560 - 6) mod 194 | |||
v8.x より前 | 3072 | 15 | (3072 - 6) mod 194 | |
8.x から 9.0 | (3072 - 6) mod 194 | |||
v8.x より前 | 3584 | 18 | (3584 - 6) mod 194 | |
8.x から 9.0 | 86 | (3584 - 6) mod 194 | ||
v8.x より前 | 4096 | 21 | 16 | (4096 - 6) mod 194 |
8.x から 9.0 | 32 | (4096 - 8) mod 194 | ||
9.5 | 156 | (4096 - 10) mod 194 | ||
13.0、16.0 | 156 | (4096 - 18) mod 194 | ||
9.0 | 8192 | 42 | 86 | (8192 - 8) mod 194 |
9.5 | 34 | (8192 - 10) mod 194 | ||
13.0、16.0 | 26 | (8192 - 18) mod 194 | ||
9.5 | 16384 | 84 | 78 | (16384 - 10) mod 194 |
13.0、16.0 | 70 | (16384 - 18) mod 194 | ||
計画として、ページおよびレコード オーバーヘッドの量は、今後のアップグレードによるファイル形式で増える可能性があることに注意してください。現在のファイル形式でページにきっちり収まるレコード サイズを考えると、将来にはもっと大きなページ サイズが必要になるかもしれません。また、レコードおよびオーバーヘッドが指定されたページ サイズ内に収まらない場合、データベース エンジンが自動的にページ サイズを更新します。たとえば、9.x のファイルに対しページ サイズ 4096 を指定したが、レコードおよびオーバーヘッドの要件が 4632 バイトであった場合、データベース エンジンはページ サイズ 8192 を使用します。
表に示すように、ページ サイズ 512 を選択すると 1 ページに 2 つのレコードしか格納できず、ファイル形式によって各ページの 114 ~ 118 バイトが未使用になります。しかし、ページ サイズ 4096 を選択すると、1 ページあたり 21 個のレコードを格納でき、各ページの 16 バイトだけが未使用になります。同じ 21 レコードでも、ページ サイズ 512 では 2 KB 以上の無駄な領域ができてしまいます。
物理レコード長が非常に小さい場合は、ほとんどのページ サイズで無駄になる領域は非常にわずかです。ただし、v8.x より前のファイルではページごとに最大 256 レコードという制限があります。この場合、物理レコード長が小さいのに大きなページ サイズ(たとえば、4096 バイト)を選択すると、無駄な領域が大きくなります。例として、次の表に 8.x より前のファイル バージョンに対して 14 バイトのレコード長を設定した場合の動作を示します。
ページ サイズ | 1 ページあたりのレコード数 | 未使用バイト | |
|---|---|---|---|
512 | 36 | 2 | (512 - 6) mod 14 |
1024 | 72 | 10 | (1024 - 6) mod 14 |
1536 | 109 | 4 | (1536 - 6) mod 14 |
2048 | 145 | 12 | (2048 - 6) mod 14 |
2560 | 182 | 6 | (2560 - 6) mod 14 |
3072 | 219 | 0 | (3072 - 6) mod 14 |
3584 | 255 | 8 | (3584 - 6) mod 14 |
4096 | 256 | 506 | (4096 - 6) mod 14 |
最小ページ サイズ
選択するページ サイズは、8 つのキー値にオーバーヘッドを加えた値を保持できるほどの大きさが必要です。ファイルに対して許容できる最小ページ サイズを見つけるには、次の最小ページ サイズ ワークシートで指定された値を追加します。このワークシートでは、例として 9.5 ファイル形式を使用します。
説明 | 例 | |
|---|---|---|
1 | バイト単位でファイル内の最大キーのサイズを決定します(社員ファイル例では、最大キーは 25 バイトです)。 一意のキーを定義していないファイルでは、システム定義のログ キー(システム データとも呼ばれる)が最大キーである場合があります。そのサイズは 8 バイトです。 | 25 |
2 | 以下のうちの 1 つを追加します。 • 重複を許さないキーまたは繰り返し重複を使用するキーの場合は、8 バイトを加算します。 • リンク重複を使用するキーには 12 バイトを加算します(この例ではリンク重複を使用します)。 | 25 + 12 = 37 |
3 | 結果に 8 を掛けます(MicroKernel エンジンでは、1 ページに 8 個以上のキーのスペースが必要です)。 | 37 * 8 = 296 |
4 | ファイル形式のインデックス ページ オーバーヘッドを追加します。 ページ サイズの選択で、インデックス ページのページ オーバーヘッド(バイト数)の表を参照してください。 | 296 + 16 = 312 |
最小ページ サイズ | 312 バイト | |
計算結果以上の有効なページ サイズを選択します。ここで、選択するページ サイズがファイル作成後に作成されたキーのサイズを収容できるサイズでなければならないことに注意してください。キー セグメントの総数は、最小ページ サイズを指示する場合があります。たとえば、ページ サイズ 512 を使用するファイルには、以下に示すように 8 個のキー セグメントしか定義できません。
ページ サイズ(バイト数) | ファイル バージョンによるキー セグメント数 | ||||
|---|---|---|---|---|---|
6.x および 7.x | 8.x | 9.0 | 9.5 | 13.0、16.0 | |
512 | 8 | 8 | 8 | 切り上げ2 | 切り上げ2 |
1024 | 23 | 23 | 23 | 97 | 切り上げ2 |
1536 | 24 | 24 | 24 | 切り上げ2 | 切り上げ2 |
2048 | 54 | 54 | 54 | 97 | 切り上げ2 |
2560 | 54 | 54 | 54 | 切り上げ2 | 切り上げ2 |
3072 | 54 | 54 | 54 | 切り上げ2 | 切り上げ2 |
3584 | 54 | 54 | 54 | 切り上げ2 | 切り上げ2 |
4096 | 119 | 119 | 119 | 2043 | 1833 |
8192 | N/A | N/A1 | 119 | 4203 | 3783 |
16384 | N/A | N/A1 | N/A1 | 4203 | 3783 |
1 "N/A" は「適用外」を意味します。 2 「切り上げ」は、ページ サイズを、ファイル バージョンでサポートされる次のサイズへ切り上げることを意味します。たとえば、512 は 1024 に切り上げられ、2560 は 4096 に切り上げるということです。 3 9.5 以降の形式のファイルでは 119 以上のセグメントを指定できますが、インデックスの数は 119 に制限されます。 | |||||
ファイル サイズの予測
ページ数を予測できることから、ファイルを格納するのに必要なバイト数を見積もることが可能です。ただし、MicroKernel エンジンは動的にページを操作するため、式を用いる場合、これらの式はファイル サイズを概算するだけであることを考慮してください。
メモ: 以下の説明とファイル サイズを決定するための式は、データ圧縮を使用するファイルには適用されません。このようなファイルのレコード長は、各レコードに含まれる繰り返し文字の数によって異なるからです。
これらの式は、必要な最大記憶域に基づいていますが、一度に 1 つのタスクでしか、ファイルに対してレコードの更新や挿入を行わないことを前提としています。同時並行トランザクション中に、複数のタスクでファイルに対してレコードを更新したり挿入したりする場合には、ファイル サイズが増加します。
またこれらの式は、ファイルからまだレコードが削除されていないことを前提としています。ファイル内のレコードをいくつ削除しても、ファイルのサイズは変わりません。MicroKernel エンジンは、削除されたレコードが占有していたページの割り当てを解除しません。むしろ、MicroKernel エンジンは新しいレコードがファイルに挿入されるたびにそれらのページを再利用し、その後で新しいページを割り当てます。
計算の最終結果に小数値が含まれている場合は、小数値を次に大きい整数に切り上げます。
式および派生手順
次の式は、ファイルの格納に必要な最大バイト数を算出するために使用します。[手順 x を参照]は、式の個々の要素を説明する手順への参照を示します。
ファイル サイズ(バイト単位) =
(ページ サイズ *
(データ ページ数 [手順 1 を参照]+
インデックス ページ数[手順 2 を参照]+
可変ページ数[手順 3 を参照]+
その他のページ数[手順 4 を参照]+
シャドウ プール ページ数[手順 5 を参照]))
(データ ページ数 [手順 1 を参照]+
インデックス ページ数[手順 2 を参照]+
可変ページ数[手順 3 を参照]+
その他のページ数[手順 4 を参照]+
シャドウ プール ページ数[手順 5 を参照]))
ファイル サイズの算出には 2 種類のページ カテゴリを含めることが必要です。標準ページ カテゴリには、データ ファイルが最初に作成されたときのページが含まれます(『Btrieve API Guide』の Create(14)も参照してください)。さらに、ファイル形式ごとの特殊ページのページ サイズの表に示される特殊(非標準)ページも式に含める必要があります。特殊ページはファイルのページ サイズの倍数になるとは限りません。
1. 以下の式を使用して、データ ページの数を算出します。
データ ページ数 =
#r /
( (PS - DPO) / PRL )
#r /
( (PS - DPO) / PRL )
各項目の説明は次のとおりです。
• #r:レコード数
• PS:ページ サイズ
• DPO:データ ページ オーバーヘッド(ページ サイズの選択を参照)
• PRL:物理レコード長(ページ サイズの選択を参照)
2. 以下の式のうちの 1 つを使用して、定義されたキーごとにインデックス ページ数を計算します。
重複を許さないインデックス、または繰り返し重複キーを許すキーごとに、
インデックス ページ数 =
( #r /
( (PS - IPO) / (KL + 8) ) ) * 2
( #r /
( (PS - IPO) / (KL + 8) ) ) * 2
各項目の説明は次のとおりです。
• #r:レコード数
• PS:ページ サイズ
• IPO:インデックス ページ オーバーヘッド(ページ サイズの選択を参照)
• KL:キー長
リンク重複キーを許すインデックスごとに、
インデックス ページ数 =
( #UKV /
( (PS - IPO) / (KL + 12) ) ) * 2
( #UKV /
( (PS - IPO) / (KL + 12) ) ) * 2
各項目の説明は次のとおりです。
• #UKV:一意のキー値の数
• PS:ページ サイズ
• IPO:インデックス ページ オーバーヘッド(ページ サイズの選択を参照)
• KL:キー長
B ツリー インデックス構造は、インデックス ページの使用率 50% 以上を保証します。したがって、インデックス ページの計算では、必要なインデックス ページの最小数に 2 をかけた値が最大サイズになります。
3. ファイルに可変長レコードが含まれている場合は、以下の式を使用して、可変ページの数を算出します。
可変ページ数 =
(AVL * #r) / (1 - (FST + (VPO/PS))
(AVL * #r) / (1 - (FST + (VPO/PS))
各項目の説明は次のとおりです。
• AVL:標準的なレコードの可変部分の平均の長さ
• #r:レコード数
• VPO:可変ページ オーバーヘッド(ページ サイズの選択を参照)
• PS:ページ サイズ
メモ: 可変長部分が同じページに収まるレコードの平均数を予測することは困難であるため、非常に大雑把な可変ページ数の予測しか得られません。
4. その他の標準ページ数を算出します。
•
•
最初の 4 つの手順の合計は、ファイル内の論理ページの概算総数を表します。
5. シャドウ ページ プールの概算ページ数を算出します。データベース エンジンは、シャドウ ページングにプールを使用します。以下の式を使用してページ数を見積もります。
シャドウ ページ プールのサイズ = (キー数 + 1) * (挿入、更新、および削除の数の平均数) * (並行トランザクション数)
この式は、タスクがトランザクションの外部で Insert、Update、および Delete オペレーションを実行する場合に適用されます。タスクがトランザクション内でこれらのオペレーションを実行している場合は、トランザクション内で予想される Insert、Update、および Delete オペレーションの平均数に、式で算定されたトランザクション外部の値をかけます。タスクが同時並行トランザクションを実行している場合は、未使用ページのプールの予測サイズをさらに大きくする必要があります。
6. これらの手順の最後にあるファイル形式ごとの特殊ページのページ サイズの表を使用して、ページ サイズを決定します。ファイル形式バージョンによって、FCR、予約済み、および PAT ページのページ サイズは、通常のデータ、インデックス、および可変ページ用のページ サイズとは異なっています。
7. ページ アロケーション テーブル(PAT)ページ数を算出します。
各ファイルには少なくとも 2 ページの PAT ページがあります。ファイル内の PAT ページ数を算出するには、以下の式のうちの 1 つを使用します。
8.x より前のファイル形式の場合:
8.x 以降のファイル形式の場合:
PAT エントリ数については、ファイル形式ごとの特殊ページのページ サイズの表を参照してください。
8. ファイル コントロール レコード(FCR)ページ用に 2 ページを含めます(ファイル コントロール レコード(FCR)も参照)。8.x 以降のファイル形式を使用している場合は、予約済みページ用の 2 ページも含めます。
ファイル形式ごとの特殊ページのページ サイズ
標準 ページ サイズ | ファイル形式 v6.x および 7.x | ファイル形式 8.x | ファイル形式 9.0 ~ 9.4 | ファイル形式 9.5、13.0、16.0 | ||||
|---|---|---|---|---|---|---|---|---|
特殊ページ サイズ | PAT ページ エントリ | 特殊ページ サイズ | PAT ページ エントリ | 特殊ページ サイズ | PAT ページ エントリ | 特殊ページ サイズ | PAT ページ エントリ | |
512 | 512 | N/A | 2048 | 320 | 2048 | 320 | N/A | N/A |
1024 | 1024 | N/A | 2048 | 320 | 2048 | 320 | 4096 | 480 |
1536 | 1536 | N/A | 3072 | 480 | 3072 | 480 | N/A | N/A |
2048 | 2048 | N/A | 4096 | 640 | 4096 | 640 | 4096 | 480 |
2560 | 2560 | N/A | 5120 | 800 | 5120 | 800 | N/A | N/A |
3072 | 3072 | N/A | 6144 | 960 | 6144 | 960 | N/A | N/A |
3584 | 3584 | N/A | 7168 | 1120 | 7168 | 1120 | N/A | N/A |
4096 | 4096 | N/A | 8192 | 1280 | 8192 | 1280 | 8192 | 1280 |
8192 | N/A | N/A | N/A | N/A | N/A | N/A | 16384 | 16000 |
16384 | N/A | N/A | N/A | N/A | N/A | N/A | 16384 | 16000 |
"N/A" は「適用外」(not applicable)を表します。 | ||||||||
データベースの最適化
MicroKernel エンジンには、ディスク領域の節約とシステム パフォーマンスの向上を実現するいくつかの機能があります。これらの機能は以下のとおりです。
• 重複キー
• レコード圧縮
重複キー
キーを重複可能と定義すれば、MicroKernel エンジンは複数のレコードにそのキーの同じ値を持たせることができます。それ以外は、各レコードにそのキーの一意の値がなければなりません。セグメント化されたキーの 1 つのセグメントが重複可能であれば、すべてのセグメントが重複可能でなければなりません。
リンク重複キー
デフォルトでは、MicroKernel エンジンは 7.0 以降のファイルに重複キーをリンク重複キーとして格納します。重複キー値を持つ最初のレコードがファイルに挿入されると、MicroKernel エンジンはインデックス ページにキー値を格納します。MicroKernel エンジンはまた、このキー値で最初のレコードと最後のレコードを識別するために 2 つのポインターを初期化します。さらに、MicroKernel エンジンはレコードの終わりにあるポインターのペアをデータ ページに格納します。これらのポインターは、同じキー値で前のレコードと次のレコードを識別します。ファイルを作成する場合、将来リンク重複キーを作成する際に使用するポインターを予約することができます。
データ ファイルを作成した後に重複キーの追加を予測し、リンク重複方法を使用するためのキーが必要であれば、ファイル内にポインターのための領域をプリアロケートすることができます。
繰り返し重複キー
リンク重複キーを作成するための領域がない場合、つまり、重複ポインターがない場合、MicroKernel エンジンは繰り返し重複キーを作成します。MicroKernel エンジンは、データ ページ上とインデックス ページ上に繰り返し重複キーのすべてのキー値を格納します。つまり、キーの値はデータ ページ上のレコード内に存在し、インデックス ページ上のキー エントリで反復されます。
メモ: 6.0 より前の Btrieve のユーザーの場合、リンク重複キーは永続インデックスに対応し、繰り返し重複キーは補足インデックスに対応します。
Create(14)オペレーションまたは Create Index(31)オペレーションのキー仕様ブロックにキー フラグのビット 7(0x80)を設定することによって、キーを繰り返し重複キーとして定義できます。6.10 より前には、キーを繰り返し重複キーと定義できず、キー フラグのビット 7 はユーザーが定義できませんでした。6.0 以降では、リンク重複キーを作成するための領域がない場合、したがって、MicroKernel エンジンが繰り返し重複キーとしてキーを作成しなければならない場合には、Stat(15)オペレーションがビット 7 を設定します。
5.x 形式を使用するファイルは、5.x では補足キー属性と呼ばれているこの同じキー フラグを使用して、キーが 5.x Create Supplemental Index(31)オペレーションで作成されたことを示します。
メモ: 6.0 より前のファイルでは、補足インデックスだけが削除できます。永続インデックスは、その名前の示すとおり削除できません。6.0 以降のファイルでは、すべてのインデックスを削除できます。
リンクと繰り返し
各方法にはパフォーマンスの利点があります。
• リンク重複キーの方が検索がより速いのは、MicroKernel エンジンで読み取るページが少ないからです。
• 繰り返し重複キーを使用する方が、複数のユーザーが並行して同じページにアクセスする場合のインデックス ページの競合は少なくなります。
リンク重複キーと繰り返し重複キーの間には、パフォーマンスのトレードオフがあります。一般に、キーの平均重複数が 2 つ以上であれば、リンク重複キーがディスク上で占有する領域は少なくなり、また、インデックス ページが少ないために一般には検索が高速になります。ただし、重複キーを持つレコードがほとんどファイルに格納されておらず、キー長が非常に短い場合は、その逆になります。それは、リンク重複ツリー内のエントリがポインターに 8 バイトを必要とするのに対して、繰り返し重複キー エントリは 4 バイトを必要とするからです。
重複を持つキーがわずかしかない場合は、繰り返し重複キーを使用して各データ レコードに 8 バイトを追加保存するのが有利です。キー重複の平均数が 2 未満である場合は、いずれを選択してもパフォーマンス上の利点はそれほどありません。
いくつかの並行トランザクションが同時に同じファイル上でアクティブになると予想する場合、繰り返し重複キーの方が、これらのトランザクションが同じページにアクセスしない確率は高くなります。並行トランザクションでの書き込みに関連するすべてのページには、それらのページに対する暗黙ロックがあります。ある並行トランザクションで変更を行うためにページが必要であり、そのページが別の並行トランザクションに関与している場合、MicroKernel エンジンは別のトランザクションが終了するまで待ちます。このような暗黙の待ち時間が頻繁に発生する場合、アプリケーションのパフォーマンスは低下します。
いずれのキー格納方法も、年代順をトラッキングするための簡便法としては推奨しません。リンク重複キーの場合、MicroKernel エンジンはキーを作成した後に挿入されるレコードの年代順を維持しますが、キーのインデックスを作成し直した場合、年代順は失われます。繰り返し重複キーについては、キーを作成してから新しいレコードを挿入するまでの間にレコードの削除がなかった場合のみ、MicroKernel エンジンはレコードの年代順を維持します。年代順をトラッキングするには、キー上で AUTOINCREMENT データ型を使用します。
ページ プリアロケーション
プリアロケーションは、MicroKernel エンジンがディスク領域を必要とするときに、その領域が利用可能であることを保証します。MicroKernel エンジンでは、データ ファイルを作成するときにファイルに最大 65535 ページをプリアロケートできます。次の表は、65535 全ページ分のディスク領域を割り当てるものと仮定して、MicroKernel エンジンが各ページ サイズのファイルに対して割り当てる最大バイト数を示したものです。
ページ サイズ | 割り当てられたディスク領域1 |
|---|---|
512 | 33553920 |
1024 | 67107840 |
1536 | 100661760 |
2048 | 134215680 |
2560 | 167769600 |
3072 | 201323520 |
3584 | 243877440 |
4096 | 268431360 |
8192 | 536862720 |
16384 | 1073725440 |
1 値は、ページ サイズに 65535 をかけたものです。 | |
指定したページ数をプリアロケートするだけの十分な領域がディスクにない場合、MicroKernel エンジンはステータス コード 18(ディスクがいっぱい)を返し、ファイルを作成しません。
データ ファイルがディスク上の連続する領域を占有する場合、ファイル操作を高速化することができます。速度の向上は、非常に大きなファイルで最も顕著です。ファイルに連続するディスク領域をプリアロケートする場合、ファイルを作成するためのデバイスには必要なバイト数の連続する使用可能空き領域が必要です。MicroKernel エンジンは、ディスク上の領域が連続であるかどうかにかかわらず、指定するページ数をプリアロケートします。
ファイルに必要なデータ ページ数とインデックス ページ数を決定するには、この章の前半で説明した式を使用します。この部分の計算から出た剰余を次に大きい整数に切上げます。
ファイルのページをプリアロケートすると、そのファイルは実際にディスクのその領域を占有します。ほかのデータ ファイルは、そのファイルを削除または交換するまで、プリアロケートされたディスク領域を使用できません。
レコードを挿入すると、MicroKernel エンジンはデータとインデックスのプリアロケートされた領域を使用します。ファイルにプリアロケートされたすべての領域が使用されている場合、MicroKernel エンジンは新しいレコードが挿入されるたびにファイルを拡張します。
Stat(15)を発行すると、MicroKernel エンジンはファイルの作成時に割り当てたページ数と MicroKernel エンジンが現在使用しているページ数との差を返します。この差が常に、プリアロケーションに指定したページ数より小さくなるのは、たとえレコードを何も挿入していなくても、ファイルの作成時に一定のページ数が使用されると MicroKernel エンジンが見なすからです。
ファイル ページは一度使用されたら、たとえそのページに格納されているすべてのレコードを削除しても、ページは使用中のままになります。Stat オペレーションが返す未使用ページ数は増えません。レコードを削除すると、MicroKernel エンジンはファイル内の空き領域のリストを保持し、新しいレコードを挿入したときに使用可能な領域を再利用します。
たとえ Stat オペレーションが返す未使用ページ数が 0 であっても、ファイルにはまだ使用可能な空き領域があります。以下のいずれかが真であれば、未使用ページ数が 0 である可能性があります。
• ファイルにはページをプリアロケートしなかった。
• プリアロケートしたすべてのページは、ある時点で使用中であった。
ブランク トランケーション
空白を切り捨てることにした場合、MicroKernel エンジンはファイルにレコードを書き込むときにレコードの可変長部分の末尾の空白(ASCII のスペース コード 32、つまり 16 進数の 0x20)を格納しません。ブランク トランケーションは、レコードの固定長部分に影響しません。MicroKernel エンジンは、データに埋め込まれている空白を削除しません。
切り捨てられた末尾の空白を含むレコードを読み取ると、MicroKernel エンジンはレコードを元の長さまで拡張します。MicroKernel エンジンがデータ バッファー長パラメーターで返す値には、拡張された空白が含まれています。ブランク トランケーションは、レコードの物理サイズに 2 バイトまたは 4 バイトのオーバーヘッドを追加し、固定長部分と一緒に格納します。ファイルが VAT を使用しない場合は 2、使用する場合は 4 です。
レコード圧縮
ファイルを作成する場合、MicroKernel エンジンがファイルにデータ レコードを格納するときにデータ レコードを圧縮するかどうかを指定できます。レコード圧縮により、多数の繰り返し文字を含むレコードの格納に必要なスペースを大幅に削減できます。MicroKernel エンジンは、5 つ以上の同じ連続文字を 5 バイトに圧縮します。
以下の環境におけるレコード圧縮の使用方法について考えてみましょう。
• 圧縮するレコードは、圧縮を使用することの利点が最大になるように構造化されます。
• ディスク利用度を高める必要性は、処理量の増大や圧縮されたファイルに必要なディスク アクセス時間より重要です。
• MicroKernel エンジンを実行しているコンピューターは、MicroKernel エンジンが圧縮バッファーに使用する追加メモリを提供できます。
メモ: データベース エンジンは、システム データを使用しており、レコード長が許容最大サイズを超えるファイルについては自動的にレコード圧縮を使用します。レコード長を参照してください。
圧縮されたファイルに対してレコード I/O を実行する場合、MicroKernel エンジンは圧縮バッファーを利用して、レコードの圧縮および拡張処理用のメモリ ブロックを提供します。レコードの圧縮や拡張を行うのに十分なメモリを確保するため、MicroKernel エンジンは、タスクが圧縮されたファイルに挿入する最長レコードの 2 倍の長さを格納できるだけのバッファー領域を必要とします。この要求は、MicroKernel エンジンがロードされた後にコンピューター内に残っている空きメモリ量に影響を与える可能性があります。たとえば、タスクが書き込むか取得する最長レコードが 64 KB の長さであれば、MicroKernel エンジンはそのレコードの圧縮および拡張に 128 KB のメモリを必要とします。
メモ: ファイルが VAT を使用している場合、MicroKernel エンジンが必要とするバッファー領域はファイルのページ サイズの 16 倍です。たとえば、4 KB のレコードでは、レコードの圧縮と拡張に 64 KB のメモリが必要になります。
圧縮されたレコードの最終の長さはそのレコードがファイルに書き込まれるまで決定できないので、MicroKernel エンジンは常に圧縮されたファイルを可変長レコード ファイルとして作成します。データ ページでは、MicroKernel エンジンは重複キー ポインターごとに、ファイルが VAT を使用しない場合は 7 バイト、使用する場合は 11 バイトを追加し、さらに、重複キー ポインターごとに 8 バイトを格納します。MicroKernel エンジンは次に、レコードを可変ページに格納します。レコードの圧縮されたイメージは可変長レコードとして格納されるので、タスクが頻繁な挿入、更新、および削除を行う場合は、個々のレコードがいくつかのファイル ページにわたって断片化される場合があります。この断片化により、MicroKernel エンジンは 1 つのレコードを取得するために複数のファイル ページの読み取りが必要になる可能性があることから、アクセス時間が遅くなるおそれがあります。
レコード圧縮オプションは、各レコードが多数の繰り返し文字を取り込む可能性がある場合に最も有効です。たとえば、レコードにいくつかのフィールドが含まれており、レコードをファイルに挿入するときにそれらのフィールドはすべてタスクによって空白に初期化される可能性があります。圧縮は、これらのフィールドがほかの値を含むフィールドによって分離される場合でなく、レコード内で 1 つにグループ化される場合に有効です。
レコード圧縮を使用するには、圧縮フラグを設定してファイルを作成しておく必要があります。キーオンリー ファイルでは圧縮を行えません。
インデックス バランス
MicroKernel エンジンでは、インデックス バランスを使用することによってディスクをさらに節約できます。MicroKernel エンジンは、デフォルトではインデックス バランスを使用しないので、現在のインデックス ページがいっぱいになるたびに、MicroKernel エンジンは新しいインデックス ページを作成する必要があります。インデックス バランスが有効であれば、MicroKernel エンジンは現在のインデックス ページがいっぱいになるたびに、新しいインデックス ページを頻繁に作成しないようにすることができます。インデックス バランスを使用すると、MicroKernel エンジンは隣接するインデックス ページで使用可能な領域を探します。これらのページのうちの 1 つに領域がある場合、MicroKernel エンジンはいっぱいのインデックス ページから空き領域を持つページへキーを移動します。
インデックス バランス処理を実行すると、インデックス ページ数が少なくなるだけでなく、より密度の高いインデックスが作成され、ディスクの総利用率も上がり、大半の読み取り操作に対する応答が速くなります。ソート順でファイルにキーを追加する場合、インデックス バランスを使用していると、インデックス ページの利用率が 50% から 100% 近くまで増加します。ランダムにキーを追加する場合、最小のインデックス ページの利用率が 50% から 66% に増加します。
Insert オペレーションと Update オペレーションでは、バランス ロジックはファイル内のより多くのページを調べるように MicroKernel エンジンに要求し、より多くのディスク I/O を要求する可能性があります。余分なディスク I/O はファイル更新速度を下げます。インデックス バランスの正確な影響は状況によって異なりますが、インデックス バランスを使用した場合、書き込み操作のパフォーマンスは概して約 5~10% 低下します。
MicroKernel エンジンは 2 つのレベル、つまり、エンジン レベルとファイル レベルのインデックス バランスを提供するので、MicroKernel エンジン環境を微調整することができます。セットアップ中にインデックス バランス設定オプションを指定すると、MicroKernel エンジンはすべてのファイルにインデックス バランスを適用します。インデックス バランス設定オプションの指定方法については、『Zen User's Guide』を参照してください。
特定のファイルだけにインデックス バランスを行うように指定することもできます。そうするには、ファイル作成時にファイル フラグのビット 5(0x20)を設定します。MicroKernel エンジンを起動したときにインデックス バランス設定オプションがオフであれば、MicroKernel エンジンはビット 5 のファイル フラグを設定したファイル上のインデックスだけにインデックス バランスを適用します。
MicroKernel エンジンを起動したときにインデックス バランス設定オプションがオンであった場合、MicroKernel エンジンはすべてのファイルのファイル フラグ内のビット 5 を無視します。この場合、MicroKernel エンジンはすべてのファイルにインデックス バランスを適用します。
ファイルは、インデックス バランスが有効であるかどうかに関係なく互換性があります。また、インデックス バランスが使用されたインデックス ページを含むファイルにアクセスするために、インデックス バランスを指定する必要はありません。MicroKernel エンジンのインデックス バランス オプションをオンにした場合、既存のファイル内のインデックス ページはいっぱいになるまで影響を受けません。MicroKernel エンジンは、このオプションを有効にした結果として、既存のファイルのインデックスを再バランスすることはありません。同様に、インデックス バランス オプションをオフにしても、既存のインデックスは影響を受けません。このオプションのオン、オフにより、MicroKernel エンジンがいっぱいになったインデックス ページを処理する方法が決まります。
可変長部割り当てテーブル
可変長部割り当てテーブルを使用すると、MicroKernel エンジンは非常に大きなレコード内に大きなオフセットで存在するデータに対してさらに高速にアクセスでき、データ圧縮を使用するファイル内のレコードを処理するときに MicroKernel エンジンが要求するバッファー サイズが大幅に削減されます。レコードの VAT を使用すると、MicroKernel エンジンはレコードの可変長部分をさらに小さな部分に分割し、次にこれらの部分をいくつもの可変長部に格納します。MicroKernel エンジンは、同量のレコード データを、レコードの可変長部に格納します。ただし、最後の可変長部は異なることがあります。MicroKernel エンジンは、ファイルのページ サイズに 8 をかけて、各可変長部に格納する量を計算します。最後の可変長部には、MicroKernel エンジンがほかの可変長部にデータを分割した後に残るデータが含まれています。
メモ: 可変長部の長さを算出する式(ページ サイズの 8 倍)は、MicroKernel エンジンの将来のバージョンでは変更される可能性があります。
VAT を使用し、4096 バイトのページ サイズを持つファイルでは、第 1 の可変長部にレコードの可変部分のオフセット 0~32767 のバイトが格納され、第 2 の可変長部にオフセット 32768~65535 が格納され、以降同様に格納されます。MicroKernel エンジンが VAT を使用してレコード内の大きなオフセットまでのシークを加速できるのは、VAT を使用すると、レコードの下位オフセットのバイトを含んでいる可変長部をスキップできるからです。
アプリケーションでは、ファイルの作成時に VAT を使用するようにするかどうかを指定します。アプリケーションが非常に大きな、物理ページ サイズの 8 倍を超えるレコードに対して Chunk オペレーションを使用し、順次でないランダムな方法でチャンクにアクセスする場合は、VAT によってアプリケーションのパフォーマンスが向上する可能性があります。アプリケーションがレコード全体に対する操作を行う場合は、VAT によってパフォーマンスは向上しません。この場合、MicroKernel エンジンはレコードを順次に読み書きし、MicroKernel エンジンはレコード内のどのバイトもスキップしないからです。
アプリケーションが Chunk オペレーションを使用するがレコードに順次アクセスする場合(たとえば、レコードの最初の 32 KB を読み、次の 32 KB を読み、という具合にレコードの最後まで読む)、VAT はパフォーマンスを向上させません。これは、MicroKernel エンジンがオペレーション間でレコード内の位置を保存することによって Chunk オペレーションが先頭からシークする必要性をなくしているためです。
VAT には別の利点もあります。MicroKernel エンジンが圧縮されたレコードを読み書きする場合、使用するバッファー サイズは、レコードの未圧縮サイズの最大 2 倍必要です。ファイルに VAT がある場合、そのバッファーは 2 つの可変長部と同じ大きさ、つまり、物理ページ サイズの 16 倍あれば済みます。
キーオンリー ファイル
キーオンリー ファイルでは、レコード全体がキーと共に格納されるため、データ ページは不要です。キーオンリー ファイルは、レコードに単一のキーが含まれており、かつそのキーがレコードの大部分を占有している場合に有効です。キーオンリー ファイルのもう 1 つの一般的な用途は、標準ファイルの外部インデックスとしての使用です。
キーオンリー ファイルには以下の制限が適用されます。
• 各ファイルには 1 つのキーしか含められません。
• 定義できる最大レコード長は 253 バイトです。
• キーオンリー ファイルではデータ圧縮を行えません。
• Step オペレーションは、キーオンリー ファイルでは機能しません。
• キーオンリー ファイルのレコードで Get Position を実行することはできますが、その位置は、レコードが更新されると変わります。
キーオンリー ファイルには、後ろに多数の PAT ページとインデックス ページが付いたファイル コントロール レコード ページしか含まれていません。キーオンリー ファイルに ACS がある場合、ACS ページもある可能性があります。ODBC を使用してファイルに参照整合性制約を定義した場合、ファイルには 1 つまたは複数の可変ページも含まれます。
セキュリティの設定
MicroKernel エンジンには、ファイル セキュリティの設定方法が 3 つあります。
• ファイルへのオーナー ネームの割り当て
• 排他モードでのファイルのオープン
• Zen Control Center(ZenCC)のセキュリティ設定を使用
また、MicroKernel エンジンはサーバー プラットフォーム上でネイティブ ファイル レベルのセキュリティが使用可能であればそれをサポートします。
メモ: Windows 開発者:NTFS ファイル システムをサーバーにインストールすると、サーバー上でファイル レベル セキュリティを使用できます。FAT ファイル システムをインストールした場合は、ファイル システム セキュリティは使用できません。
MicroKernel エンジンには、データ セキュリティを向上させる以下の機能があります。
オーナー ネーム
MicroKernel エンジンでは、Set Owner(29)オペレーションを使用してオーナー ネームを割り当てることにより、ファイルに対するアクセスを制限することができます(『Btrieve API Guide』の Set Owner(29)を参照してください)。ファイルにオーナー ネームを割り当てると、MicroKernel エンジンはそのファイルに対するアクセスについてオーナー ネームを要求します。このため、オーナー ネームを指定しないユーザーまたはアプリケーションがファイルの内容に対して無許可でアクセスしたり変更することはできません。
同様に、ファイルに割り当てられているオーナー ネームがわかれば、ファイルからオーナー ネームをクリアできます。
オーナー ネームでは大文字と小文字が区別されます。また、短いものと長いものがあります。短いオーナー ネームは半角 8 文字まで、長いオーナー ネームは半角 24 文字までの範囲で指定できます。詳細については、『Advanced Operations Guide』のオーナー ネームを参照してください。
以下の方法でファイルに対するアクセスを制限できます。
• ユーザーはオーナー ネームを指定せずに読み取り専用アクセスを行うことができます。ただし、ユーザーもタスクも、オーナー ネームを指定しないでファイルの内容を変更することはできません。そうしようとすると、MicroKernel エンジンはエラーを返します。
• すべてのアクセス モードでユーザーにオーナー ネームを指定するように要求することができます。正しいオーナー ネームを指定しないと、MicroKernel エンジンはファイルに対するすべてのアクセスを制限します。
オーナー ネームを割り当てる場合、データベース エンジンがオーナー ネームを暗号化キーとしてディスク ファイル内のデータを暗号化するように要求することもできます。ディスク上のデータを暗号化すると、無許可のユーザーはデバッガーまたはファイル ダンプ ユーティリティを使用してデータを調べることができません。Set Owner オペレーションを使用し、暗号化を選択すると、直ちに暗号化処理が開始されます。ファイル全体が暗号化されるまでは MicroKernel エンジンの制御下にあります。また、ファイル サイズが大きいほど、暗号化処理にかかる時間は長くなります。暗号化にはさらに処理時間が必要なため、データ セキュリティが重要である場合に限りこのオプションを選択する必要があります。
ファイルに割り当てられているオーナー ネームがわかれば、Clear Owner(30) オペレーションを使用してファイルから所有権の制限を削除できます。また、暗号化されたファイルで Clear Owner オペレーションを使用すると、データベース エンジンはそのファイルを復号化します。
メモ: Set Owner(29)および Clear Owner(30)は、16 進数の長いオーナー ネームを処理しません。これらの操作に送信されるオーナー ネームは ASCII 文字列として扱われます。
排他モード
ファイルへのアクセスを 1 クライアントに制限するために、MicroKernel エンジンが排他モードでファイルを開くように指定できます。クライアントが排他モードでファイルを開くと、排他モードでファイルを開いたクライアントがそのファイルを閉じるまでほかのクライアントはファイルを開けません。
SQL セキュリティ
データベース URI(Uniform Resource Indicator)文字列の詳細については、データベース URI を参照してください。ZenCC のセキュリティ設定へのアクセス方法は、『Zen User Guide』を参照してください。
最終更新日: 2024年07月10日