SELECT
指定された情報をデータベースから取り出します。SELECT ステートメントにより、テンポラリ ビューを作成します。
構文
[
ORDER BY order-by式[,
order-by式]...] [
limit句] [
FOR UPDATE]
クエリ スペック ::= (クエリ スペック)
FROM テーブル参照[, テーブル参照]...
[WHERE 検索条件]
式またはサブクエリ ::= 式 | (クエリ スペック) [ORDER BY order-by式
[, order-by式]...] [limit句]
サブクエリ式 ::= (クエリ スペック) [ORDER BY order-by式
[, order-by式]...] [limit句]
order-by式 ::=
式 [
CASE(文字列) |
COLLATE 照合順序名] [
ASC |
DESC]
limit句 ::= [LIMIT [オフセット,] 行数 | 行数 OFFSET オフセット | ALL [OFFSET オフセット]]
オフセット ::= 数値 | ?
行数 ::= 数値 | ?
選択リスト ::= * | 選択項目[, 選択項目]...
選択項目 ::=
式 [[
AS]
エイリアス名] |
テーブル名.*
テーブル参照 ::= {OJ 外部結合の定義}
| [
データベース名.]
テーブル名 [[
AS]
エイリアス名] [
WITH (
テーブル ヒント)]
| [
データベース名.]
ビュー名 [[
AS]
エイリアス名]
| dbo.f
システム カタログ関数名 [[
AS]
エイリアス名]
| 結合定義
| (結合定義)
| (
テーブルサブクエリ) [
AS]
エイリアス名 [(
列名[,
列名]...)]
外部結合の定義 ::= テーブル参照 外部結合タイプ JOIN テーブル参照
ON 検索条件
外部結合タイプ ::= LEFT [OUTER] | RIGHT [OUTER] | FULL [OUTER]
テーブル ヒント ::= INDEX (インデックス値[, インデックス値]...)
インデックス値 ::= 0 | インデックス名
インデックス名 ::= ユーザー定義名
結合定義 ::= テーブル参照 [結合タイプ] JOIN テーブル参照 ON 検索条件
| テーブル参照 CROSS JOIN テーブル参照
| 外部結合の定義
結合タイプ ::= INNER | LEFT [OUTER ] | RIGHT [OUTER] | FULL [OUTER]
テーブル サブクエリ ::=
クエリ スペック [[
UNION [
ALL]
クエリ スペック]...] [
ORDER BY order-by式[,
order-by式]...]
検索条件 ::= 検索条件 AND 検索条件
| 検索条件 OR 検索条件
| (検索条件)
| 述部
述部 ::=
式 [
NOT]
BETWEEN 式 AND 式 | 式またはサブクエリ 比較演算子 式またはサブクエリ
比較演算子 ::= < | > | <= | >= | = | <> | !=
式またはサブクエリ ::= 式 | (クエリ スペック)
式 ::= 式 - 式
| 式 + 式
| 式 * 式
| 式 / 式
| 式 & 式
| 式 | 式
| 式 ^ 式
| (式)
| -式
| +式
| 列名
| ?
| リテラル
| セット関数
| スカラー関数
| {fn スカラー関数}
| ウィンドウ関数
|
CASE case値式 WHEN when式 THEN then式[...] [
ELSE else式]
END| SQLSTATE
| サブクエリ式
| NULL
| : ユーザー定義名
| グローバル変数
| 仮想列
サブクエリ式 ::= (クエリ スペック)
セット関数 ::=
AVG ([
DISTINCT |
ALL]
式)
|
COUNT (<* | [
DISTINCT |
ALL]
式>)
|
COUNT_BIG (<* | [
DISTINCT |
ALL]
式>)
| LAG (式[, 式[, 式]] over句)
|
MAX ([
DISTINCT |
ALL]
式)
|
MIN ([
DISTINCT |
ALL]
式)
|
STDEV ([
DISTINCT |
ALL]
式)
|
STDEVP ([
DISTINCT |
ALL]
式)
|
SUM ([
DISTINCT |
ALL]
式)
|
VAR ([
DISTINCT |
ALL]
式)
|
VARP ([
DISTINCT |
ALL]
式)
グローバル変数 ::= @:IDENTITY
| @:ROWCOUNT
| @@BIGIDENTITY
| @@IDENTITY
| @@ROWCOUNT
| @@SPID
| @@VERSION
仮想列 ::= SYS$CREATE
| SYS$UPDATE
ウィンドウ関数 ::= セット関数 over句
over句 ::= OVER ([partition-by句] order-by-in-over句 [row句])
partition-by句 ::= PARTITION BY 式[, 式]...
order-by-in-over句 ::= ORDER BY 式 [ASC | DESC][, 式 [ASC | DESC]]...
row句 ::= ROWS ウィンドウ フレームの範囲
ウィンドウ フレームの範囲 ::= {UNBOUNDED PRECEDING
| 符号なし整数リテラル PRECEDING
| CURRENT ROW}
メモ:OVER 句での ORDER BY の使用は、Zen SQL の他の場所での ORDER BY とは異なります。本リリースに適用される詳細および関連情報については、
SQL ウィンドウ関数を参照してください。
備考
ここでは、SELECT の使用に関連する次のトピックについて説明します。
FOR UPDATE
SELECT FOR UPDATE は、クエリで選択されたテーブル内の 1 つまたは複数の行をロックします。レコード ロックは、次の COMMIT または ROLLBACK ステートメントが発行されたときに解放されます。
この競合を避けるため、SELECT FOR UPDATE は行を取得しているときロックします。
ステートメント レベル SQL_ATTR_CONCURRENCY が SQL_CONCUR_LOCK に設定されている場合、SELECT FOR UPDATE はトランザクション内で優先されます。SQL_ATTR_CONCURRENCY が SQL_CONCUR_READ_ONLY に設定されている場合、データベース エンジンはエラーを返しません。
SELECT FOR UPDATE は WAIT および NOWAIT キーワードをサポートしません。SELECT FOR UPDATE は、短時間で行をロックできない場合(20 回再試行)、ステータス コード
84:レコードまたはページはロックされています。を返します。
制約
SELECT FOR UPDATE ステートメントには以下の制約があります。
•トランザクション内のみで有効です。トランザクション外で使用された場合、そのステートメントは無視されます。
•単一のテーブルのみでサポートされます。SELECT FOR UPDATE は、JOIN や単純でないビュー、また、GROUP BY、DISTINCT、UNION キーワードと共には使用できません。
•CREATE VIEW ステートメント内では使用できません。
GROUP BY
Zen では、列リストの GROUP BY がサポートされているほか、式リストや、GROUP BY 式リスト内のあらゆる式に対する GROUP BY がサポートされています。GROUP BY 拡張の詳細については、
GROUP BY を参照してください。GROUP BY のない HAVING はサポートされていません。
次の特性のいずれかを備えた SELECT ステートメントを実行することによって生成される結果セットおよびストアド ビューは、読み取り専用になります(更新できません)。つまり、位置付け UPDATE や位置付け DELETE、および SQLSetPos 呼び出しを使用して、結果セットあるいはストアド プロシージャでデータを追加、変更、削除することは許可されません。
•選択リストに集計を含んでいる
SELECT SUM(c1) FROM t1
•選択リストに DISTINCT を指定している
SELECT DISTINCT c1 FROM t1
•ビューに GROUP BY を使用している
SELECT SUM(c1), c2 FROM t1 GROUP BY c2
•ビューは結合である(複数のテーブルを参照する)
SELECT * FROM t1, t2
•ビューに UNION 演算子を使用しており、UNION ALL が指定されていないか、もしくはすべての SELECT ステートメントが同じテーブルを参照していない
SELECT c1 FROM t1 UNION SELECT c1 FROM t1
SELECT c1 FROM t1 UNION ALL SELECT c1 FROM t2
ストアド ビューでは UNION 演算子を使用できないので注意してください。
•ビューに、外部クエリ内のテーブル以外のテーブルを参照するサブクエリを含んでいる
SELECT c1 FROM t1 WHERE c1 IN (SELECT c1 FROM t2)
SQL ウィンドウ関数
Zen は、ANSI 標準の SQL ウィンドウ使用のサブセットを提供します。本リリースにおけるこの初期導入には、一定の制限事項および考慮事項があります。
制限事項
OVER 句には次の制限があります。
•SELECT ステートメント内のすべての OVER 句は、それらの PARTITION BY、ORDER BY、および ROWS 句と一致している必要があります。PARTITION BY の式は同一かつ同順である必要があり、ORDER BY の式も同一かつ同順、ROWS 句は同一である必要があります。これらのうち OVER 句に存在しない句は、他の句にも存在しない必要があります。
•OVER 句には ORDER BY 句を含める必要があります。PARTITION BY 句は省略可能です。PARTITION BY が存在する場合、この句で ORDER BY 句と同じ列を使用してはいけません。PARTITION BY がない場合は、結果セット全体が 1 つのパーティションとして扱われます。
•PARTITION BY 句の ROWS の指定では、次のキーワードがサポートされています。
•UNBOUNDED
•n PRECEDING
•CURRENT ROW
•PARTITION BY 句の ROWS の指定では、次のキーワードはサポートされていません。
•BETWEEN
•FOLLOWING
•RANGE キーワードはサポートされていません。
•DISTINCT キーワードは、セット関数ではサポートされていません。
•OVER 句の ORDER BY 句では、COLLATE の指定はサポートされていません。
•ウィンドウ関数は、前方のみのカーソルでしか使用できません。
考慮事項
ANSI SQL 標準では、特定の構文の組み合わせはデフォルトの RANGE セマンティクスを意味しますが、現在の Zen リリースでは RANGE はサポートされていません。したがって、現在の Zen リリースでは、デフォルトの RANGE 指定が RANGE UNBOUNDED PRECEDING である場合には、このデフォルトは ROWS UNBOUNDED PRECEDING として実装されます。
通常、これら 2 つのデフォルトの違いが結果セットに影響するのは、PARTITION BY 句と ORDER BY 句で返される列の値の組み合わせが行ごとに一意でない場合だけです。そのため、現在の Zen リリースでは、そのような列の値の組み合わせが行ごとに一意でない場合は、ROWS UNBOUNDED PRECEDING を明示的に指定することをお勧めします。これにより期待される結果が返ります。
動的パラメーター
動的パラメーター(疑問符(?)で表されます)は、SELECT 項目としてはサポートされていません。動的パラメーターが述部の一部であれば、SELECT ステートメント内で使用することができます。たとえば、SELECT * FROM faculty WHERE id = ? は、動的パラメーターが述部の一部なので有効です。
Zen Control Center の SQL Editor では、述部に動的パラメーターを含む SQL ステートメントを実行できないことに留意してください。
変数は、ストアド プロシージャ内でのみ SELECT 項目として使用することができます。
CREATE PROCEDURE を参照してください。
エイリアス
WHERE、HAVING、ORDER BY、または GROUP BY 句にエイリアスを含めることができます。エイリアス名はテーブル内のどの列名とも異なっていなければなりません。次のステートメントは、WHERE 句と GROUP BY 句でエイリアス a および b を使用する例を示しています。
SELECT Student_ID a, Transaction_Number b, SUM (Amount_Owed) FROM Billing WHERE a < 120492810 GROUP BY a, b UNION SELECT Student_ID a, Transaction_Number b, SUM (Amount_Paid) FROM Billing WHERE a > 888888888 GROUP BY a, b
SUM と DECIMAL の精度
DECIMAL 型のフィールドで SUM 集計関数を使用する場合は、次の規則が適用されます。
•結果の有効桁数は 74 ですが、小数部桁数は列定義に依存します。
•74 を超える桁数の数値(本当に、非常に大きな数値です)が計算された場合、結果でオーバーフロー エラーが発生することがあります。オーバーフローが発生した場合、値は返らず、SQLSTATE に数値が範囲外であることを示す 22003 が設定されます。
サブクエリ
サブクエリは一種の SELECT ステートメントで、ステートメント内に 1 つ以上の SELECT ステートメントを含んでいます。サブクエリは、ステートメントの処理を進めるために値を生成します。一番上の SELECT ステートメントでサブクエリをネストできる最大数は 16 です。
サポートされるサブクエリのタイプは次のとおりです。
•comparison
•quantified
•in
•exists
•correlated
•expression
•table
相関サブクエリ述部は、グループ化された列を参照する HAVING 句ではサポートされていません。
expression サブクエリは、SELECT リストの中でサブクエリを使用できます。たとえば、SELECT (SELECT SUM(c1) FROM t1 WHERE t1.c2 = t1.(c2) FROM t2 のように記述できます。サブクエリの SELECT リストに指定できる項目は 1 つのみです。たとえば、次のステートメントは、サブクエリの SELECT リストに 2 つ以上の項目が含まれているため、エラーが返ります。
SELECT p.id, (SELECT SUM(b.amount_owed), SUM(b.amount_paid) FROM billing b) FROM person p
式としてのサブクエリは相関でも非相関でもかまいません。相関サブクエリは、一番上のステートメントに指定されているテーブル内の 1 つ以上の列を参照します。非相関サブクエリは、一番上のステートメントに指定されているテーブル内の列を参照しません。次の例は、WHERE 句の相関サブクエリを示しています。
SELECT * FROM student s WHERE s.Tuition_id IN
(SELECT t.ID FROM tuition t WHERE t.ID = s.Tuition_ID);
メモ:テーブル サブクエリでは、非相関サブクエリはサポートされますが、相関サブクエリはサポートされません。
演算子
IN、
EXISTS、
ALL、または
ANY と関連付けられているサブクエリは式と見なされません。
相関および非相関のサブクエリは、どちらも単一の値のみ返すことができます。このため、相関サブクエリおよび非相関サブクエリはスカラー サブクエリとも呼ばれます。
スカラー サブクエリは、DISTINCT、GROUP BY、および ORDER BY 句に含むことができます。
サブクエリは式の左辺で使用することができます。
式またはサブクエリ 比較演算子 式またはサブクエリ
ここで、式は 1 つの式、比較演算子は次のうちのいずれかです。
<
(より小さい) | >
(より大きい) | <=
(小さいかまたは等しい) | >=
(大きいかまたは等しい) | =
(等しい) |
<>
(等しくない) | !=
(等しくない) | LIKE | IN | NOT IN |
このセクションの残り部分では、以下の項目について説明します。
サブクエリの最適化
左辺のサブクエリの動作は、サブクエリが相関サブクエリでなく、すべての結合条件が 1 つの外部結合である場合の、IN、NOT IN、および =ANY について最適化されています。それ以外の条件は最適化されないことがあります。次は、これらの条件を満たすクエリの例です。
SELECT count(*) FROM person WHERE id IN (SELECT faculty_id FROM class)
Zen はインデックスに基づいてサブクエリを最適化するため、サブクエリでインデックスを使用するとパフォーマンスが向上します。たとえば、次のステートメント内のサブクエリは、student_id が Billing テーブルのインデックスであるため、この列によって最適化されます。
SELECT (SELECT SUM(b.amount_owed) FROM billing b WHERE b.student_id = p.id) FROM person p
サブクエリ内の UNION
1 つのサブクエリの中で、複数の異なる UNION グループをかっこで囲むことは許可されていません。かっこは各 SELECT ステートメントの中で使用できます。
たとえば、次のステートメントで、IN の後のかっこと最後のかっこは許可されません。
SELECT c1 FROM t5 WHERE c1 IN ( (SELECT c1 FROM t1 UNION SELECT c1 FROM t2) UNION ALL (SELECT c1 FROM t3 UNION SELECT c1 from t4) )
テーブル サブクエリ
テーブル サブクエリを使用すると、複数のクエリを組み合わせて 1 つの詳細なクエリにすることができます。テーブル サブクエリは、データベースに残らない動的ビューです。一番上の SELECT クエリが完了したら、テーブル サブクエリに関連付けられたすべてのリソースが解放されます。
メモ:テーブル サブクエリでは、非相関サブクエリのみが使用できます。相関サブクエリは使用できません。
次の改ページ調整の例(1 ページあたり 100 行ずつの 1500 行)は、ORDER BY キーワードを使用したテーブル サブクエリの使用方法を示しています。
最初の 100 行
SELECT * FROM ( SELECT TOP 100 * FROM ( SELECT TOP 100 * FROM person ORDER BY last_name asc ) AS foo ORDER BY last_name desc ) AS bar ORDER BY last_name ASC
2 番目の 100 行
SELECT * FROM ( SELECT TOP 100 * FROM ( SELECT TOP 200 * FROM person ORDER BY last_name asc ) AS foo ORDER BY last_name DESC ) AS bar ORDER BY last_name ASC
...
15 番目の 100 行
SELECT * FROM ( SELECT TOP 100 * FROM ( SELECT TOP 1500 * FROM person ORDER BY last_name ASC ) AS foo ORDER BY last_name DESC ) AS bar ORDER BY last_name ASC
テーブル ヒントの使用
テーブル ヒント機能を使用すると、クエリの最適化のために、どのインデックスを使用するかを指定することができます。テーブル ヒントは、データベース エンジンが使用するデフォルトのクエリ オプティマイザーより優先されます。
テーブル ヒントで INDEX(0) が指定されていると、エンジンは関連するテーブルのテーブル スキャンを実行します。テーブル スキャンは、インデックスを使用して特定のデータ要素を見つけるのではなく、テーブル内の各行を読み取ります。
テーブル ヒントに INDEX(インデックス名) が指定されている場合、エンジンはインデックス名を使用し、JOIN 条件の制約や、DISTINCT、GROUP BY、ORDER BY の使用に基づいてテーブルを最適化します。指定されたインデックスでテーブルが最適化できない場合、エンジンは既存のインデックスに基づいて最適化を試みます。
複数のインデックス名を指定した場合、エンジンは最適なパフォーマンスを得られるインデックスを選択するか、OR 最適化のために複数のインデックスを使用します。わかりやすくするために例を示します。以下を想定します。
CREATE INDEX ndx1 on t1(c1)
CREATE INDEX ndx2 on t1(c2)
CREATE INDEX ndx3 on t1(c3)
SELECT * FROM t1 WITH (INDEX (ndx1, ndx2)) WHERE c1 = 1 AND c2 > 1 AND c3 = 1
データベース エンジンは、ndx2 を使用するのではなく ndx1 を使用して、c1 = 1 を最適化します。ndx3 は、テーブル ヒントに含まれていないため、考慮に入れません。
以下について考えてみましょう。
SELECT * FROM t1 WITH (INDEX (ndx1, ndx2)) WHERE (c1 = 1 OR c2 > 1) AND c3 = 1
エンジンは ndx1 と ndx2 の両方を使用して(c1 = 1 OR c2 > 1)を最適化します。
テーブル ヒントの中で複数のインデックス名が表れる順序は重要ではありません。データベース エンジンは、指定されたインデックスから最も優れた最適化を行えるインデックスを選択します。
テーブル ヒント内で重複するインデックス名は無視されます。
結合されたビューでは、FROM 句の最後ではなく、適切なテーブル名の後にテーブル ヒントを指定します。たとえば、次は正しいステートメントです。
SELECT * FROM person WITH (INDEX(Names)), student WHERE student.id = person.id AND last_name LIKE 'S%'
これに対し、次のステートメントは正しくありません。
SELECT * FROM person, student WITH (INDEX(Names)) WHERE student.id = person.id AND last_name LIKE 'S%'
メモ:テーブル ヒント機能は上級ユーザー向けです。一般的に、データベース クエリ オプティマイザーが最も優れた最適化方法を選択するので、テーブルヒントは必要ではありません。
テーブル ヒントの制限事項
•テーブル ヒントで使用できるインデックス名の最大数は、SQL ステートメントの最大長(64 KB)によってのみ制限されます。
•テーブル ヒント内のインデックス名は、テーブル名で完全に修飾されていてはなりません。
不正な SQL: | SELECT * FROM t1 WITH (INDEX(t1.ndx1)) WHERE t1.c1 = 1 |
戻り値: | SQL_ERROR |
szSqlState: | 37000 |
メッセージ: | 構文エラー:SELECT * FROM t1 WITH (INDEX(t1.<< ??? >>ndx1)) WHERE t1.c1 = 1 |
•テーブル ヒントは、SELECT ステートメント内でビューと共に使用された場合は無視されます。
不正な SQL: | SELECT * FROM myt1view WITH (INDEX(ndx1)) |
戻り値: | SQL_SUCCESS_WITH_INFO |
szSqlState: | 01000 |
メッセージ: | ビューと共に指定されたインデックス ヒントは無視されます。 |
•インデックス名以外ではゼロが唯一の有効なヒントです。
不正な SQL: | SELECT * FROM t1 WITH (INDEX(85)) |
戻り値: | SQL_ERROR |
szSqlState: | S1000 |
メッセージ: | インデックス ヒントが不正です。 |
•テーブル ヒント内のインデックス名には既存のインデックスを指定する必要があります。
不正な SQL: | SELECT * FROM t1 WITH (INDEX(ndx4)) |
戻り値: | SQL_ERROR |
szSqlState: | S0012 |
メッセージ: | インデックス名が不正です。インデックスが見つかりません。 |
•テーブル ヒントは、サブクエリ AS テーブルには指定できません。
不正な SQL: | SELECT * FROM (SELECT c1, c2 FROM t1 WHERE c1 = 1) AS a WITH (INDEX(ndx2)) WHERE a.c2 = 10 |
戻り値: | SQL_ERROR |
szSqlState: | 37000 |
メッセージ: | 構文エラー:SELECT * FROM (SELECT c1, c2 FROM t1 WHERE c1 = 1) AS a WITH<< ??? >>(INDEX(ndx2)) WHERE a.c2 = 10 |
システム データ v2 のアクセス
13.0 形式を使用するデータ ファイルでは、システム データ v2 により、レコード作成およびレコード更新のタイム スタンプに基づく Btrieve キーが有効になります。これらの作成キーおよび更新キーには以下の特性があります。
•作成キーは既存の Btrieve システム キー 125 に取って代わり、トランザクション ログで使用されます。
•更新キーによって、キー 125 の作成時刻のタイム スタンプなど、特定の時点以降に変更された行を特定することができます。更新キーは Btrieve システム キー 124 です。
•どちらのキーも、セプタ秒精度を持つ TIMESTAMP(7) 形式、YYYY-MM-DD HH:MM:SS.sssssss です。
例
この単純な SELECT ステートメントによって、Faculty テーブルの全データが取り出されます。
SELECT * FROM Faculty
このステートメントによって、person および faculty テーブルから、person テーブル内の id 列と faculty テーブル内の id 列が同じデータが取り出されます。
SELECT Person.id, Faculty.salary FROM Person, Faculty WHERE Person.id = Faculty.id
このセクションの残り部分では、SELECT ステートメントのさまざまな例を示します。次の見出しのうちのいくつかは、SELECT の構文定義に示される変数に基づいています。
FOR UPDATE
次の例ではテーブル t1 を使用して FOR UPDATE の使用法を示します。t1 は Demodata サンプル データベースの一部であるとします。ストアド プロシージャは SELECT FOR UPDATE ステートメントのためのカーソルを作成します。ループで t1 から c1=2 の行の各レコードをフェッチし、c1 の値を 4 に設定します。
プロシージャは、IN パラメーターとして値 2 を渡して呼び出されます。
この例は、2 人のユーザー A と B は Demodata にログインしているものとします。ユーザー A が以下の処理を行います。
DROP TABLE t1
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
CREATE PROCEDURE p1 (IN :a INTEGER)
AS
BEGIN
DECLARE :b INTEGER;
DECLARE :i INTEGER;
DECLARE c1Bulk CURSOR FOR SELECT * FROM t1 WHERE c1 = :a FOR UPDATE;
START TRANSACTION;
OPEN c1Bulk;
BulkLinesLoop:
LOOP
FETCH NEXT FROM c1Bulk INTO :i;
IF SQLSTATE = '02000' THEN
LEAVE BulkLinesLoop;
END IF;
UPDATE SET c1 = 4 WHERE CURRENT OF c1Bulk;
END LOOP;
CLOSE c1Bulk;
SET :b = 0;
WHILE (:b < 100000) DO
BEGIN
SET :b = :b + 1;
END;
END WHILE;
COMMIT WORK;
END;
CALL p1(2)
WHILE ループがトランザクションの COMMIT を遅延させることに注意してください。この遅延の間、ユーザー B は t1 の更新を試みるとします。これらの行はユーザー A が SELECT FOR UPDATE ステートメントでロックしているため、ユーザー B にはステータス コード 84 が返されます。
============
次の例ではテーブル t1 を使用して、SELECT FOR UPDATE がストアド プロシージャの外部で使用された場合のレコードのロック方法を示します。t1 は Demodata サンプル データベースの一部であるとします。
この例は、2 人のユーザー A と B は Demodata にログインしているものとします。ユーザー A が以下の処理を行います。
DROP TABLE t1
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
INSERT INTO t1 VALUES (1,1)
INSERT INTO t1 VALUES (2,1)
(AUTOCOMMIT をオフにする)
(実行して取り出す):"SELECT * FROM t1 WHERE c1 = 2 FOR UPDATE"
c1 = 2 である 2 つのレコードは、ユーザー A が COMMIT WORK または ROLLBACK WORK ステートメントを発行するまでロックされます。
(ユーザー B が t1 の更新を試みる):"UPDATE t1 SET c1=3 WHERE c1=2" これらの行はユーザー A が SELECT FOR UPDATE ステートメントでロックしているため、ユーザー B にはステータス コード 84 が返されます。
(ここで、ユーザー A がトランザクションをコミットしたとします。)c1 = 2 である 2 つのレコードのロックは解除されます。
これで、ユーザー B は "UPDATE t1 SET c1=3 WHERE c1=2" を実行して、c1 の値を変更できます。
概算数値リテラル
SELECT * FROM results WHERE quotient =-4.5E-2
INSERT INTO results (quotient) VALUES (+5E7)
BETWEEN 述語
式1 BETWEEN 式2 and 式3 という構文では、式1 >= 式2 かつ、式1 <= 式3 の場合に True が返されます。式1 >= 式3 または式1 <= 式2 の場合は、False が返されます。
式2 と式3 は動的パラメーター(たとえば、SELECT * FROM emp WHERE emp_id BETWEEN ? AND ?)にすることができます。
次の例では、ID が 10000 と 20000 の間にある名が Person テーブルから取り出されます。
SELECT First_name FROM Person WHERE ID BETWEEN 10000 AND 20000
相関名
テーブルと列の相関名はどちらもサポートされています。
次の例では、person テーブルと faculty テーブルからデータが選択されます。2 つのテーブルを区別するためにエイリアスの T1 と T2 を使用しています。
SELECT * FROM Person t1, Faculty t2 WHERE t1.id = t2.id
また、テーブルの相関名は、次の例のように FROM 句を使って指定することもできます。
SELECT a.Name, b.Capacity FROM Class a, Room b
WHERE a.Room_Number = b.Number
正確な数値リテラル
SELECT car_num, price FROM cars WHERE car_num = 49042 AND price = 49999.99
IN 述語
これにより、名が Bill と Roosevelt のレコードがテーブル Person から選択されます。
SELECT * FROM Person WHERE First_name IN ('Roosevelt', 'Bill')
セット関数
Zen ではセット関数 AVG、COUNT、COUNT_BIG、LAG、MAX、MIN、STDEV、STDEVP、SUM、VAR、および VARP がサポートされています。それぞれ以下の例で説明します。
LAG は、ウィンドウ関数としてのみ有効です。この詳細と例については、
LAG キーワードを参照してください。
AVG、MAX、MIN、および SUM
集計関数の AVG、MAX、MIN、および SUM は、一般に予想されるとおりに動作します。次の例は、Faculty サンプル テーブルの Salary フィールドを用いてこれらの関数の使い方を示しています。
SELECT AVG(Salary) FROM Faculty
SELECT MAX(Salary) FROM Faculty
SELECT MIN(Salary) FROM Faculty
SELECT SUM(Salary) FROM Faculty
ほとんどの場合、これらの関数は GROUP BY と一緒に使用され、次の例で示すように、共通の列を持つ一連の行に適用されます。
SELECT AVG(Salary) FROM Faculty GROUP BY Dept_Name
次の例では、amount_paid の総額が 100 以上の場合に、student_id と amount_paid の総額が billing テーブルから取り出されます。次に、student_id 別にレコードが分類されます。
SELECT Student_ID, SUM(Amount_Paid)
FROM Billing
GROUP BY Student_ID
HAVING SUM(Amount_Paid) >=100.00
式が正の整数リテラルの場合、そのリテラルが結果セット内の列の番号として解釈され、その列について順序付けが行われます。セット関数またはセット関数を含む式については、順序付けは許可されません。
COUNT および COUNT_BIG
COUNT(式)および COUNT_BIG(式)によって、述部にある式の非ヌル値すべてがカウントされます。COUNT(*) および COUNT_BIG(*) では、ヌル値を含むすべての値がカウントされます。COUNT() は、最大値が 2,147,483,647 である INTEGER データ型を返します。COUNT_BIG() は、最大値が 9,223,372,036,854,775,807 である BIGINT データ型を返します。
次の例は、成績評価点平均が 3.5 以上ある(および、結果がヌルでない)化学専攻の学生の数を返します。
SELECT COUNT(*) FROM student WHERE (CUMULATIVE_GPA > 3.4 and MAJOR='Chemistry')
STDEV および STDEVP
STDEV 関数は、データのサンプルに基づいて、すべてのデータの標準偏差を返します。STDEVP 関数は、指定された式のすべての値の母集団に対する標準偏差を返します。各関数の方程式は以下のとおりです。

次の例は、Student サンプル テーブルから、専攻科目別に成績評価点平均の標準偏差を返します。
SELECT STDEV(Cumulative_GPA), Major FROM Student GROUP BY Major
次の例は、Student サンプル テーブルから、専攻科目別に成績評価点平均の母集団の標準偏差を返します。
SELECT STDEVP(Cumulative_GPA), Major FROM Student GROUP BY Major
VAR および VARP
VAR 関数は、データのサンプルに基づいて、すべての値の統計的分散を返します。VARP 関数は、指定された式のすべての値の母集団に対する統計的分散を返します。各関数の方程式は以下のとおりです。
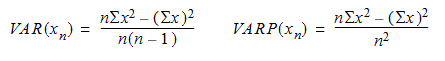
次の例は、Student サンプル テーブルから、専攻科目別に成績評価点平均の統計的分散を返します。
SELECT VAR(Cumulative_GPA), Major FROM Student GROUP BY Major
次の例は、Student サンプル テーブルから、専攻科目別に成績評価点平均の母集団の統計的分散を返します。
SELECT VARP(Cumulative_GPA), Major FROM Student GROUP BY Major
STDEV、STDEVP、VAR、および VARP の場合、式は数値データ型である必要があり、8 バイトの DOUBLE が返されるということに注意してください。式の最小値と最大値の差が範囲外である場合は、浮動小数点のオーバーフロー エラーになります。式に集計関数を含むことはできません。式フィールドに値が入っている行が少なくとも 2 つはある必要があります。そうでないと、結果は計算されず、NULL が返されます。
日付リテラル
時刻リテラル
タイムスタンプ リテラル
文字列リテラル
日付演算
IF
IF システム スカラー関数によって、条件の真の値に基づく条件付き実行が提供されます。
次の式は、列ヘッダー Prime1 を出力し、amount_owed 列の値が 2000 の場合は 2000 を、2000 でない場合は 0 を出力します。
SELECT Student_ID, Amount_Owed,
IF (Amount_Owed = 2000, Amount_Owed, Convert(0, SQL_DECIMAL)) "Prime1"
FROM Billing
次の例では、Class テーブルから、Section 列が 001 の場合はその値を、001 でない場合は "xxx" を、列ヘッダー Prime1 の下に出力します。
さらに、列ヘッダー Prime2 の下に、Section 列の値が 002 の場合はその値を、002 でない場合は "yyy" を出力します。
SELECT ID, Name, Section,
IF (Section = '001', Section, 'xxx') "Prime1",
IF (Section = '002', Section, 'yyy') "Prime2"
FROM Class
ネストした IF 関数を使用して、ヘッダー Prime1 とヘッダー Prime2 を合体させることができます。次のクエリは、列ヘッダー Prime の下に、Section 列の値が 001 か 002 の場合は Section 列の値を出力し、それ以外の場合は "xxx" を出力します。
SELECT ID, Name, Section,
IF (Section = '001', Section, IF(Section = '002', Section, 'xxx')) Prime
FROM Class
複数データベースの結合
必要であれば、データベース名を FROM 句内のエイリアス付きのテーブル名の前に付加して、結合で使用する 2 つ以上の異なるデータベースにあるテーブルを区別することができます。
指定したデータベースはすべて同じデータベース エンジンで処理し、同じデータベース コード ページ設定である必要があります。これらのデータベースは同じ物理ボリューム上になくてもかまいません。現行データベースはセキュリティで保護されていてもいなくてもかまいませんが、結合内のそれ以外のデータベースはセキュリティで保護されていない必要があります。参照整合性に関しては、すべての RI キーが同一のデータベース内に存在している必要があります。(
エンコードも参照してください。)
リテラル データベース名は選択リストまたは WHERE 句内で使用することはできません。選択リストまたは WHERE 句内で特定の列を参照する場合は、指定する各テーブルのエイリアスを使用する必要があります。例を参照してください。
2 つの異なるデータベース accounting と customers が同じサーバー上に存在していると仮定します。次の例のようなテーブル エイリアスと SQL 構文を使って 2 つのデータベースにあるテーブルを結合することができます。
SELECT ord.account, inf.account, ord.balance, inf.address
FROM accounting.orders ord, customers.info inf
WHERE ord.account = inf.account
============
次の例では、2 つのデータベースは acctdb と loandb です。テーブル エイリアスはそれぞれ a と b です。
SELECT a.loan_number_a, b.account_no, a.current_bal, b.balance
FROM acctdb.ds500_acct_master b LEFT OUTER JOIN loandb.ml502_loan_master a ON (a.loan_number_a = b.loan_number)
WHERE a.current_bal <> (b.balance * -1)
ORDER BY a.loan_number_a
左外部結合
次の例は、Demodata データベースの Person テーブルと Student テーブルにアクセスして、学生の姓と、名の頭文字、および GPA を取得する方法を示します。LEFT OUTER JOIN を使用すると、Person テーブル内のすべての行がフェッチされます(LEFT OUTER JOIN の左側にあるテーブル)。すべての人が GPA を持っているわけではないため、列によっては結果にヌル値を持ちます。以下は、外部結合がどのように働き、両方のテーブルから一致しない行を返すかを示します。
SELECT Last_Name, Left(First_Name,1) AS First_Initial, Cumulative_GPA AS GPA FROM "Person"
LEFT OUTER JOIN "Student" ON Person.ID=Student.ID
ORDER BY Cumulative_GPA DESC, Last_Name
完全に整数の GPA を持つ人全員がわかり、彼らをその姓の長さに従って並べたいとします。MOD ステートメントと LENGTH スカラー関数を使用して、クエリに次の文を追加することにより、これを実現できます。
WHERE MOD(Cumulative_GPA,1)=0 ORDER BY LENGTH(Last_Name)
右外部結合
LEFT OUTER JOIN と RIGHT OUTER JOIN との違いは、一致しないすべての行を表示する対象が RIGHT OUTER JOIN の右側に定義されたテーブルである点です。クエリの LEFT OUTER JOIN の部分を RIGHT OUTER JOIN を使用するように変更します。GPA がない場合でも、右テーブル(この場合は Student)から不一致行がすべて表示される点が異なります。ただし、Student テーブル内の行はすべて GPA を持つため、すべての行がフェッチされます。
SELECT Last_Name, Left(First_Name,1) AS First_Initial, Cumulative_GPA AS GPA FROM "Person"
RIGHT OUTER JOIN "Student" ON Person.ID=Student.ID
ORDER BY Cumulative_GPA DESC, Last_Name
カルテシアン結合
カルテシアン結合は、両方のテーブルの行を可能な限りすべて組み合わせた行列です。カルテシアン内の行数は、1 番目のテーブル内の行数に 2 番目のテーブル内の行数を掛けた値に等しくなります。
データベース内に次のようなテーブルがあるとします。
表 35 Addr テーブル
EmpID | Street |
|---|
E1 | 101 Mem Lane |
E2 | 14 Young St. |
表 36 Loc テーブル
LocID | Name |
|---|
L1 | PlanetX |
L2 | PlanetY |
次のステートメントにより、上記のテーブルのカルテシアン結合を実行します。
SELECT * FROM Addr,Loc
これにより、次のデータ セットが生成されます。
表 37 カルテシアン結合を使った SELECT ステートメント
EmpID | Street | LocID | Name |
E1 | 101 Mem Lane | L1 | PlanetX |
E1 | 101 Mem Lane | L2 | PlanetY |
E2 | 14 Young St | L1 | PlanetX |
E2 | 14 Young St | L2 | PlanetY |
Sys$create および Sys$update を使用したクエリ
次の例は、作成時以降に更新されたレコードを検索する簡単な例を示します。
create table sensorData SYSDATA_KEY_2 (location varchar(20), temp real);
insert into sensorData values('Machine1', 77.3);
insert into sensorData values('Machine2', 79.8);
insert into sensorData values('Machine3', 65.4);
insert into sensorData values('Machine4', 90.0);
select "sys$create", "sys$update", sensorData.* from sensorData;
--行を更新します
update sensorData set temp = 90.1 where location = 'Machine1';
--更新された行を検索します
select "sys$create", "sys$update", sensorData.* from sensorData where sys$update > sys$create;
集計関数の DISTINCT
DISTINCT は集計関数で有用です。SUM、AVG、および COUNT と一緒に使用した場合は、重複する値を取り除いてから、総計、平均、件数を求めます。MIN および MAX と一緒に使用することはできますが、返される最大と最小の結果は変わりません。
たとえば、学部ごとの給与の最低額、最高額、平均額を知りたいと仮定します。このとき、同額の給与は除くことにします。次のステートメントは、computer science 学部以外の学部に対してこれを実行します。
SELECT dept_name, MIN(salary), MAX(salary), AVG(DISTINCT salary) FROM faculty WHERE dept_name<>'computer science' GROUP BY dept_name
反対に、同額の給与も含む場合は DISTINCT を省きます。
SELECT dept_name, MIN(salary), MAX(salary), AVG(salary) FROM faculty WHERE dept_name<>'computer science' GROUP BY dept_name
SELECT ステートメントでの DISTINCT の使用方法については、
DISTINCT を参照してください。
TOP または LIMIT
TOP または LIMIT キーワードを使用することにより、SELECT ステートメントで返される行数を制限することができます。数値はリテラルの正の値でなければなりません。32 ビットの符号なし整数として定義します。たとえば、次のように指定します。
SELECT TOP 10 * FROM Person
Demodata の Person テーブルから最初の 10 行が返されます。
LIMIT は、OFFSET キーワードを提供する点を除けば、TOP とまったく同じです。OFFSET により、返されたレコード内で最初の行を選択することで、結果セット内を「スクロール」できるようになります。たとえば、オフセットを 5 にした場合、返される最初の行は行 6 になります。LIMIT には、オフセットを指定する方法が 2 つあります。次の例に示すように、OFFSET キーワードを使用する方法と使用しない方法で、どちらも同じ結果が返されます。
SELECT * FROM Person LIMIT 10 OFFSET 5
SELECT * FROM Person LIMIT 5,10
OFFSET キーワードを使用しない場合は、オフセット値を行数の前に、カンマで区切って置く必要があることに注意してください。
TOP または LIMIT を ORDER BY と一緒に使用することができます。その場合、データベース エンジンはテンポラリ テーブルを生成し、ORDER BY で使用できるインデックスがない場合は、そこにクエリの結果セット全体を置きます。テンポラリ テーブル内の行は、結果セットにおいて、ORDER BY で指定した順序で並べられますが、TOP または LIMIT によって決められた行数のみがクエリで返されます。
TOP または LIMIT を使用するビューは、ほかのテーブルやビューと結合できます。
TOP や LIMIT と
SET ROWCOUNT の主な違いは、SET ROWCOUNT が現在のデータベース セッション中に発行される後続のステートメントすべてに作用するのに対し、TOP や LIMIT は現在のステートメントにのみ作用する点です。
クエリで SET ROWCOUNT と、TOP または LIMIT を使用した場合は、2 つの値のうち小さい方の値に等しい行数を返します。
TOP と LIMIT は、1 つのクエリまたはサブクエリ内でいずれか一方を使用できますが、両方は使用できません。
カーソルのタイプと TOP または LIMIT
TOP 句または LIMIT 句を持ち、動的カーソルを使用する SELECT クエリは、カーソルのタイプを静的カーソルに変換します。前方のみのカーソルと静的カーソルは影響を受けません。
TOP または LIMIT の例
次の例では、TOP と LIMIT の両方の句を使用しています。これらは、キーワードとして互いに代替でき、同じ結果を得られますが、LIMIT の方が返される行に関してより多くの制御を提供します。
SELECT TOP 10 * FROM person; -- 10 行を返します
SELECT * FROM person LIMIT 10; -- 10 行を返します
SELECT * FROM person LIMIT 10 OFFSET 5; -- 行 6 から 10 行を返します
SELECT * FROM person LIMIT 5,10; -- 行 6 から 10 行を返します
SET ROWCOUNT = 5;
SELECT TOP 10 * FROM person; -- 5 行を返します
SELECT * FROM person LIMIT 10; -- 5 行を返します
SET ROWCOUNT = 12;
SELECT TOP 10 * FROM person ORDER BY id; -- id 列で順序付けされた全リストから最初の 10 行を返します
SELECT * FROM person LIMIT 20 ORDER BY id; -- id 列で順序付けされた全リストから最初の 12 行を返します
============
次の例では、TOP または LIMIT が VIEW、UNION、またはサブクエリで使用された場合のさまざまな動作を示します。
CREATE VIEW v1 (c1) AS SELECT TOP 10 id FROM person;
CREATE VIEW v2 (d1) AS SELECT TOP 5 c1 FROM v1;
SELECT * FROM v2 -- 5 行を返します
SELECT TOP 10 * FROM v2 -- 5 行を返します
SELECT TOP 2 * FROM v2 -- 2 行を返します
SELECT * FROM v2 LIMIT 10 -- 5 行を返します
SELECT * FROM v2 LIMIT 10 OFFSET 3 -- 行 4 から 2 行を返します
SELECT * FROM v2 LIMIT 3,10 -- 行 4 から 2 行を返します
SELECT TOP 10 id FROM person UNION SELECT TOP 13 faculty_id FROM class -- 17 行を返します
SELECT TOP 10 id FROM person UNION ALL SELECT TOP 13 faculty_id FROM class -- 23 行を返します
SELECT id FROM person WHERE id IN (SELECT TOP 10 faculty_id from class) -- 5 行を返します
SELECT id FROM person WHERE id >= any (SELECT TOP 10 faculty_id from class) -- 1040 行を返します
============
次の例では、ID が特定の番号より上の学生について、その姓と支払う義務のある金額を返します。
SELECT p_last_name, b_owed FROM
(SELECT TOP 10 id, last_name FROM person ORDER BY id DESC) p (p_id, p_last_name),
(SELECT TOP 10 student_id, SUM (amount_owed) FROM billing GROUP BY student_id ORDER BY student_id DESC) b (b_id, b_owed)
WHERE p.p_id = b.b_id AND p.p_id > 714662900
ORDER BY p_last_name ASC
テーブル ヒントの例
このトピックでは、テーブル ヒントの作業例を提供します。Zen で SQL ステートメントを使用して、それらを作成します。
DROP TABLE t1
CREATE TABLE t1 (c1 INTEGER, c2 INTEGER)
INSERT INTO t1 VALUES (1,10)
INSERT INTO t1 VALUES (1,10)
INSERT INTO t1 VALUES (2,20)
INSERT INTO t1 VALUES (2,20)
INSERT INTO t1 VALUES (3,30)
INSERT INTO t1 VALUES (3,30)
CREATE INDEX it1c1 ON t1 (c1)
CREATE INDEX it1c1c2 ON t1 (c1, c2)
CREATE INDEX it1c2 ON t1 (c2)
CREATE INDEX it1c2c1 ON t1 (c2, c1)
DROP TABLE t2
CREATE TABLE t2 (c1 INTEGER, c2 INTEGER)
INSERT INTO t2 VALUES (1,10)
INSERT INTO t2 VALUES (1,10)
INSERT INTO t2 VALUES (2,20)
INSERT INTO t2 VALUES (2,20)
INSERT INTO t2 VALUES (3,30)
INSERT INTO t2 VALUES (3,30)
テーブル ヒントの使用には、一定の制約が適用されます。
テーブル ヒントの制限事項の例を参照してください。
============
次の例は、インデックス it1c1c2 で最適化します。
SELECT * FROM t1 WITH (INDEX(it1c1c2)) WHERE c1 = 1
これを次の例と対比してみます。制約は c1 = 1 のみから成るため、次の例ではインデックス it1c2 ではなく it1c1 で最適化しています。クエリの最適化に使用できないインデックスがクエリに指定されている場合、ヒントは無視されます。
SELECT * FROM t1 WITH (INDEX(it1c2)) WHERE c1 = 1
============
次の例はテーブル t1 のテーブル スキャンを実行します。
SELECT * FROM t1 WITH (INDEX(0)) WHERE c1 = 1
============
次の例は、インデックス it1c1c2 および it1c2c1 で最適化します。
SELECT * FROM t1 WITH (INDEX(it1c1c2, it1c2c1)) WHERE c1 = 1 OR c2 = 10
============
次の例は、ビューの作成でテーブル ヒントを使用します。すべてのレコードがビューから選択されると、SELECT ステートメントはインデックス it1c1c2 で最適化します。
DROP VIEW v2
CREATE VIEW v2 as SELECT * FROM t1 WITH (INDEX(it1c1c2)) WHERE c1 = 1
SELECT * FROM v2
============
次の例はサブクエリでテーブル ヒントを使用し、インデックス it1c1c2 で最適化します。
SELECT * FROM (SELECT c1, c2 FROM t1 WITH (INDEX(it1c1c2)) WHERE c1 = 1) AS a WHERE a.c2 = 10
============
次の例はサブクエリでテーブル ヒントを使用し、エイリアス名 "a" を使用します。このエイリアス名は必須です。
SELECT * FROM (SELECT Last_Name FROM Person AS P with (Index(Names)) ) a
============
次の例は、c1 = 1 制約に基づいてクエリを最適化し、インデックス it1c1c2 に基づいて GROUP BY 句を最適化します。
SELECT c1, c2, count(*) FROM t1 WHERE c1 = 1 GROUP BY c1, c2
============
次の例はインデックス it1c1 で最適化し、前の例とは異なり、制約のみで最適化して GROUP BY 句では最適化しません。
SELECT c1, c2, count(*) FROM t1 WITH (INDEX(it1c1)) WHERE c1 = 1 GROUP BY c1, c2
GROUP BY 句は指定したインデックス it1c1 を使用して最適化できないため、データベース エンジンは GROUP BY を処理するのにテンポラリ テーブルを使用します。
============
次の例は JOIN 句でテーブル ヒントを使用し、インデックス it1c1c2 で最適化します。
SELECT * FROM t2 INNER JOIN t1 WITH (INDEX(it1c1c2)) ON t1.c1 = t2.c1
これを、テーブル ヒントを使用せずインデックス it1c1 で最適化する次のステートメントと対比してみます。
SELECT * FROM t2 INNER JOIN t1 ON t1.c1 = t2.c1
============
次の例は JOIN 句でテーブル ヒントを使用し、テーブル t1 でテーブル スキャンを実行します。
SELECT * FROM t2 INNER JOIN t1 WITH (INDEX(0)) ON t1.c1 = t2.c1
これを、同じくテーブル t1 のテーブル スキャンを実行する次の例と対比してみます。ただし、JOIN 句が使用されていないため、このステートメントはテンポラリ テーブル結合を使用します。
SELECT * FROM t2, t1 WITH (INDEX(0)) WHERE t1.c1 = t2.c1
関連項目