Query Plan Viewer
クエリの最適化に役立つユーティリティ
おそらく、SQL パフォーマンスの最も複雑な面は、クエリの最適化です。データベース エンジンはクエリの最適化を自動的に実行しますが、クエリ構造自体が全体的な性能やエンジンによる最適化方法に影響する可能性があります。
ほとんどすべてのクエリは、2 とおり以上の書き方をしても、同じ結果セットを返すことができます。たとえば、単純な SELECT * FROM table1 というクエリについて考えてみましょう。table1 には 5 つの列があり、col1、col2、(以下同様)という名前が付けられているとします。クエリを SELECT col1, col2, col3, col4, col5 FROM table1 と記述しても、同様の結果セットをもたらすことができます。
これら 2 つのクエリを視覚的に比較した場合、SELECT * の方が、各列を名前で列挙するよりも単純なように見えます。しかし、クエリ内に各列を名前で列挙することによって、ごくわずかながらパフォーマンスが引き上げられます。これは、SELECT * の場合には、アスタリスク記号を列名に解析しなければならないからです。クエリ自体でそのような解析を前もって実行しておけば、その作業は必要でなくなります。
パフォーマンスを向上させる最良の方法は、データベースに対してクエリを実行するのに必要な時間を最小限にすることです。クエリは非常に複雑にすることも、途方もなく大きい構造にすることもできるため、考え得るすべてのクエリの最適化について、この付録で説明することはできません。しかし、Query Plan Viewer を使用することによって、クエリの最適化方法をよりよく判断できるようになります。
Query Plan Viewer は、データベース エンジンによって選択されたクエリ プランを表示することができるグラフィカル ユーザー インターフェイスです。クエリ プランでは SELECT、INSERT、UPDATE または DELETE ステートメントについて表示できます。Query Plan Viewer はワイド文字データに対応しています。
Query Plan の設定
2 つの SQL ステートメントによって、クエリ プランを作成するかどうか、また、プランにどのような名前を付けるかを制御できます。どちらのステートメントも SQL セッションにのみ適用されます。
ステートメントは、Control Center 内で、または Zen データベース エンジンに SQL ステートメントを送信できるユーティリティから実行できます。
表 179 クエリ プラン用 SQL ステートメントの設定
SQL ステートメント | 説明 |
|---|
SET QRYPLAN=<on | off> | Query Plan Viewer を使用してクエリ プランを作成するかどうかを、データベース エンジンに指示します。 |
SET QRYPLANOUTPUT=<NULL | ファイル名> | クエリ プラン ファイルの場所と名前を設定します。NULL は、クエリ プラン ファイルを作成しないように指示します。1 つのクエリ プラン ファイルに複数のクエリのプラン結果を入れることができます。参考までに、クエリ プラン ファイルには、クエリごとに使用するエンコードのコード ページ識別子が含まれています。クエリでどのデータベース エンコードが使用されているかに関係なく、Query Plan Viewer はワイド文字データを正しく表示します。 デフォルトでは、Query Plan Viewer は拡張子が .qpf のファイル名を探します。ファイル名の拡張子はどんなものでも使用できますし、省略してもかまいません。 たとえば、select_salary という名前のクエリ プランを作成し、そのクエリ プランをドライブ D のルートにあるディレクトリ mydirectory に保存します。 SET QRYPLANOUTPUT='d:\mydirectory\select_salary.qpf' データベース エンジンがクエリ プランの出力ファイルを作成するため、パスは、データベース エンジンが実行されているマシン上の場所にする必要があります。パスがクライアント側の場所やクライアントのドライブ割り当てを参照していてはいけません。 |
グラフィカル ユーザー インターフェイス
Query Plan Viewer には、
Query Viewer と
Plan Viewer の 2 つのウィンドウが含まれています。
Query Viewer
Query Viewer では SQL クエリを表示します。一度に表示できるクエリ プランは 1 つだけですが、複数のプランを同時に開いておくことができます。また Query Viewer には、クエリ プラン ファイルを開く、2 つ以上のプランを同時に開いているときに目的のクエリ プランへ移動する、およびクエリ プランをエクスポートするためのメニュー コマンドが含まれています。
Query Viewer は必要に応じて表示サイズを変更することができます。SQL クエリの表示を容易にする垂直スクロールバーも備えています。
Query Viewer ウィンドウは、ワイド文字データに適したフォントを使用します。Query Plan Viewer は、使用可能なシステム フォントをチェックし、次のうちから使用可能な最初の 1 つを選択します。
•Consolas
•Lucida Console
•Andale Mono
•Courier New
Plan Viewer
Plan Viewer には、クエリ プランのグラフィック表現がノードを持つツリー形式で含まれます。各ノードはクエリのさまざまなコンポーネントを表します。
Plan Viewer は必要に応じて表示サイズを変更することができます。さまざまなサイズでクエリ プラン ツリーを表示できるよう、垂直および水平スクロールバーを備えています。必要に応じてツリーのサイズを変更したり、ツリーを拡大/縮小したりするためのメニュー コマンドやキーボード ショートカットがあります。
クエリに応じて、異なる種類のノードが Query Viewer に現れます。各ノードは、クエリの実行のステップを表します。たとえば、ベース テーブルから選択する、2 つのテーブルの結果を結合して 1 つの結果セットに入れる、集計値を計算する、グループの変わり目を判断する、グループ結果を組み合わせて 1 つの結果セットに入れるなどを表すことができます。
ノード
次の表にノードをまとめて示します。
表 180 Plan Viewer ノード
ノードの記号 | ノードの意味 |
|---|
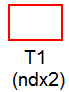
| データベース内のテーブルからデータを得ることを表します。四角形の下に表示される名前は、テーブルの名前です。テーブル名の下に名前が表示されている場合、その名前は、テーブルからデータを取得する際に使用したインデックスを示します。インデックス名の右にあるアスタリスクは、そのインデックスに一意の値が含まれていることを示します。 |
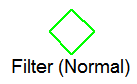
| 行の選択操作を表します。かっこ内の単語は、"Normal" か "Range:" のいずれかになります。 •Normal フィルターは、ダウンストリーム ノードから行が返された後に適用されます。 •Range フィルターはベース テーブルの真上にのみ現れます。Range フィルターによって、テーブルからインデックス値を基に制限されたレコードが取得されます。 |
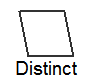
| DISTINCT(重複値の削除)操作を実行します。このノードは通常、プラン ツリーの先頭か先頭付近に現れます。クエリから行を返す前に、結果セットから重複を取り除きます。 |
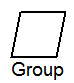
| GROUP BY 句を基に、グループの変わり目を検出します。 |
| SELECT および HAVING 句で集計値を正しく累算するために、Group Break ノードと一緒に働きます。 |
| 2 つのノード間の JOIN を実行します。かっこ内の値は、実行される結合(JOIN)の種類を示します。 •"Outer" は、インデックスを使用しない、左外部結合または右外部結合を示します。 •"OuterRange" は、インデックスを使用する、左外部結合または右外部結合を示します。 •"Normal" は、カルテシアン結合を示します。 •"Range" は、インデックスを使用する内部結合を示します。 |
| 集計値の累算を実行します。このノードは MIN、MAX、AVG、COUNT、SUM、および STDEV に対して、これらの集計関数で DISTINCT 句が使われている場合に使用されます。ノードの中の単語は、累算する集計値の種類を示します。 GROUP BY 句と併用して集計値が累算される場合、集計関数ノードはグループ分け(Group Break)ノードとグループ(Group)ノードの間に現れます。 |
| GROUP BY 句が存在しない場合に、集計値の累算を処理します。 |
| メイン クエリの単一のサブクエリによるデータ取得を処理します。このノードは、root のクエリ プランを表示している場合には現れません。サブクエリを表示している場合にのみ現れます。 |
| テンポラリ テーブルの作成、およびテンポラリ テーブルからのデータ取得を処理します。このノード下のベース テーブルへの参照は、テンポラリ テーブルの列の参照に変更されます。 |
| UNION および UNION ALL 操作を処理します。基になるクエリ実行プランを繰り返し実行し、UNION 結果セットのデータを取得します。Plan Viewer は、最初のクエリをルート クエリ、2 番目のクエリをサブクエリ 1、以下同様として、UNION を表示します。 |
メモ:Plan Viewer のサイズの縦横比を変更すると、それに応じてノードを表す記号の縦横比も変わります。そのため、ノードの表示は上記の表の例と同じように見えるとは限りません。
ノードの詳細
以下のクエリ プラン ノードをダブルクリックすると、ポップアップ ウィンドウが現れ、詳細な情報が表示されます。
•テーブル
•フィルター
•サブクエリ
•順序付きテンポラリ テーブル
上記以外のノードをダブルクリックしても、ノードに関する詳しい情報は提供されません。詳細情報を持つノード上にマウス カーソルが置かれると、カーソルが手の形に変わります。
次の表では、表示される詳細情報の種類について説明します。
ノードの種類 | 詳細情報 |
|---|
テーブル | •テーブルの名前 •テーブル内の合計行数 •読み取る予測行数 •範囲の情報。範囲情報は、ベース テーブルが JOIN の右側にあり、テーブルからのデータの取得をインデックスの使用によって最適化できる場合にのみ使用されます。範囲情報には次のものが含まれます。 •取得された列 •範囲の取得の開始に使用された値(通常は、別のテーブルおよび列の値になります)と取得の終了に使用された値 •実行する最初の演算。たとえば、より大きい(GT)、以上(GE)、より小さい(LT)、など。 •中止する場合の判断に用いる比較方法(GT、GE など) |
フィルター(Normal) | 行の評価に使用される条件のテキスト表現。ワイド文字データが存在する場合、そのデータは正しく表示されます。 |
フィルター(Range) | •使用されるインデックスに関する情報 •フィルターが返される行のセットを絞り込む方法 •テーブルからの最初の読み取りタイプ(GT、GE など) •これ以上のレコードの読み取りを停止するために、TRUE と評価されなければならない条件(GT、GE など) |
サブクエリ | サブクエリの種類と、サブクエリに対して実行される最適化 |
順序付きテンポラリ テーブル | •テンポラリ テーブルに含まれている列の一覧 •その列がテンポラリ テーブルの行の順序付けに使用されている列(キー)かどうか、あるいはツリーに渡す値であるかどうかを示す印 |
Plan Viewer にも、プランをさまざまなズーム レベルで表示したり、サブクエリがある場合にはそれを表示したりするためのメニュー コマンドが含まれています。
Query Plan Viewer のタスク
ここでは、以下の作業について説明します。
►クエリ プランを作成するには
1 SET QRYPLAN = on を実行して、クエリ プランの作成を有効にします。
2 SET QRYPLANOUTPUT ステートメントを実行して、クエリ プラン ファイルの場所と名前を指定します。
3 SQL の SELECT、INSERT、UPDATE、または DELETE ステートメントを実行します(対応するクエリ プランを作成します)。
4 SET QRYPLAN = off を実行して、クエリ プランの作成を無効にします。
►Query Plan Viewer を起動するには
1 以下の操作のいずれかを実行します。
•Zen Control Center で、[ツール]>[Query Plan Viewer]をクリックします。
•Zen\bin ディレクトリにある w3sqlqpv.exe ファイルを実行します。
►クエリ プランを表示するには
1 Query Viewer で、[ファイル]>[開く]メニューをクリックします。
2 目的のクエリ プラン ファイルの場所に移動してそのファイルを選択し、[開く]ボタンをクリックします。
Query Viewer のタイトル バーには、開いているクエリ プランの数と現在表示されているプランの情報が示されます。
3 2 つ以上のクエリ プランが開いている場合は、[表示]メニューから以下のコマンドを使用してウィンドウ間を移動できます。
•[先頭](または Ctrl+F):最初に読み込んだクエリ プランを表示します。
•[末尾](または Ctrl+L):最後に読み込んだクエリ プランを表示します。
•[次](または Ctrl+N):次に新しいクエリ プランを表示します。
•[前](または Ctrl+P):次に古いクエリ プランを表示します。
•[ジャンプ](または Ctrl+G):読み込んだプランの序数を基に、クエリ プランを表示します。
►クエリ プランを XML ファイルへエクスポートするには
1 Query Viewer で、[ファイル]>[XML へエクスポート]をクリックします。
2 目的のクエリ プラン XML ファイルの場所に移動してそのファイルを選択し、[開く]ボタンをクリックします。
メモ:同じダイアログ ボックスで、新しい XML ファイルの名前を指定することもできます。
ヒント: [XML へエクスポート]メニュー項目が有効になるのは、クエリ プランがビューアに読み込まれている場合のみです。
次の表では、SQL クエリから派生した XML ファイルのスキーマについて説明します。
要素および属性 | 説明 | 親要素 | 子要素 |
|---|
<QPF filename=filename> filename:QPF ファイルのパスと名前。 | XML ファイルのエクスポート元となる QPF ファイル。1 つの XML ファイルに 1 つの QPF ファイルが対応します。 | ヘッダー情報 | <Query> |
<Query number=number> number:Query Plan Viewer で表示されるクエリ番号。1 番目は 1、2 番目は 2 というように番号が付けられます。 | <QPF> ファイルのクエリ。1 つの XML ファイルにつき、少なくとも 1 つのクエリが対応します。 | <QPF> | <SQL> <TreeRoot> |
<SQL> | プランの生成に使用する SQL ステートメント。 SQL スクリプトが、大文字 N で始まる Unicode 文字の文字列リテラルを宣言している場合、そのプレフィックスは <SQL> 要素に表示されます。<Filter> の子要素 <Properties> も参照してください。 | <Query> | |
<TreeRoot name=name> name:"Root Query" または "Subquery X"。 | ルート クエリまたはサブクエリのどちらかを示します。 | <Query> | 以下のすべてのノード要素: <Join> <Filter> <Base> <Distinct> <Set> <FCalc> <Group> <GroupBreak> <OrderedTempTable> <Union> <Subquery> |
ノードの要素 | それぞれの要素がクエリ プラン ツリー内の 1 つのノードです(SQL ステートメントの一部)。 | <TreeRoot>、または別のノード要素の <Child>、<LeftChild>、<RightChild> | |
<Join> | | <TreeRoot> | <Text> <Properties> <LeftChild> <RightChild> |
<Filter> | SQL スクリプトが、大文字 N で始まる Unicode 文字の文字列リテラルを宣言している場合、そのプレフィックスは <Properties> 子要素には表示 されません。 <SQL> も参照してください。 | <TreeRoot> | <Text> <Properties> <Child> |
<Base> | ダイアグラム ツリー(樹形図)における葉を表します。 | <TreeRoot> | <Text> <Properties> |
<Distinct> | | <TreeRoot> | <Properties> <Child> |
<Set> | | <TreeRoot> | <Text> <Properties> <SetString> <Child> |
<FCalc> | | <TreeRoot> | <Properties> <LeftChild> <RightChild> |
<Group> | | <TreeRoot> | <Properties> <Child> |
<GroupBreak> | | <TreeRoot> | <Properties> <Child> |
<OrderedTempTable> | | <TreeRoot> | <Properties> <Child> |
<Union> | | <TreeRoot> | <Properties> <Child> |
<Subquery> | | <TreeRoot> | <Properties> <Child> |
ノードの要素の子 | 多様。ノードに関する情報の追加、またはノード タグの子へのリンク。 | 多様 | |
<Text> | | <Join> <Filter> <Set> <Base>(オプション) | |
<Properties> | | すべてのノード要素 | |
<SetString> | | <Set> | |
<Child> | | <Filter> <Distinct> <Set> <Group> <GroupBreak> <OrderedTempTable> <Union> <Subquery> | |
<LeftChild> | | <Join> <FCalc> | |
<RightChild> | | <Join> <FCalc>(オプション) | |
►Plan Viewer でクエリ プランの表示サイズを調整するには
[表示]をクリックしてから、変更したいサイズ変更コマンドをクリックします。
•[自動調整]:クエリ プランのサイズを変更して、Plan Viewer でプラン全体が表示できるようにします。ウィンドウのサイズを変更するとビューのサイズも変更されます。クエリ プランを表示するときのデフォルトは[自動調整]です。
•[100%]、[50%]、または[25%]:クエリ プランのサイズを指定したパーセンテージに変更します。
•[拡大率]:クエリ プランのサイズを、指定したパーセンテージに変更します。
•[拡大(-)]または[縮小(+)]:クエリ プランのサイズを大きくする(拡大)か、または、小さく(縮小)します。拡大率は 5% から 500% の間で指定できます。
►Plan Viewer でクエリ プランをスクロールするには
[表示]をクリックしてから、希望するスクロール コマンドをクリックします。
•[右へスクロール](または右矢印):ウィンドウの右側へ向かってスクロールします。
•[左へスクロール](または左矢印):ウィンドウの左側へ向かってスクロールします。
•[上へスクロール](または上矢印):ウィンドウの上側へ向かってスクロールします。
•[下へスクロール](または下矢印):ウィンドウの下側へ向かってスクロールします。
►変更されたクエリ プランを再読み込みするには
Query Viewer で、[ファイル]>[更新]をクリックします。
これは、現在読み込まれているクエリ プラン ファイルの再読み取りを行います。
►クエリ プラン ノードの詳細を表示するには
Plan Viewer で、次のノードのいずれかをダブルクリックします。
•テーブル
•フィルター
•サブクエリ
•順序付きテンポラリ テーブル
►クエリ プランのサブクエリを表示するには
Plan Viewer で、[サブクエリ]をクリックしてからサブクエリの番号をクリックします(メイン クエリ内の最初のサブクエリは「サブクエリ 1」に対応し、2 番目のクエリは「サブクエリ 2」、以下同様に対応します)。クエリ プランには、いくつものサブクエリが含まれることもあれば、サブクエリなしの場合もあります。クエリ プランに対するすべてのサブクエリが[サブクエリ]メニューに現れます。サブクエリを選択すると、その名前が Plan Viewer のタイトル バーのかっこ内に表示されます。
クエリ プランの検査およびクエリ パフォーマンスの評価
Query Plan Viewer は特に、作成したクエリをテストして、そのクエリをデータベース エンジンがどのように実行するかを調べる、プロジェクトの開発段階で役に立ちます。それぞれのクエリを作成し、クエリ プラン ファイルを 1 つ生成してから、各プランを検査することができます。各クエリの情報を基に、インデックスを追加したり削除したりして、その変更による影響を調べることができます。また、クエリを変更して、ステートメントの構文に加えた変更がパフォーマンスに影響を及ぼすかどうかを調べることもできます。
比較するクエリ プランの例を作成する
例として、以下の手順に従って、Zen で提供されるサンプル データベース Demodata のいくつかのテーブルを使用することにより、Query Plan Viewer の使い方を実演できます。
比較のために、Enrolls テーブルからインデックスを 1 つ削除し、クエリを実行してクエリ プラン ファイルを作成した後、Enrolls にインデックスを追加し直し、クエリをもう一度実行して比較クエリ プラン ファイルを作成します。
1 Zen Control Center(ZenCC)で、クエリ プランの作成を有効にする SQL ステートメントと、クエリ プラン ファイルの名前を
example1.qpf と指定する SQL ステートメントを実行します。
Query Plan の設定を参照してください。
2 ZenCC で、Demodata データベースに対して次のクエリを実行します。
DROP INDEX Enrolls.ClassID
Demodata はインストールするときに最適化されるため、Enrolls テーブルの Class_ID 列からインデックスを削除する必要があります。
3 ZenCC で、Demodata データベースに対して次のクエリを実行します。
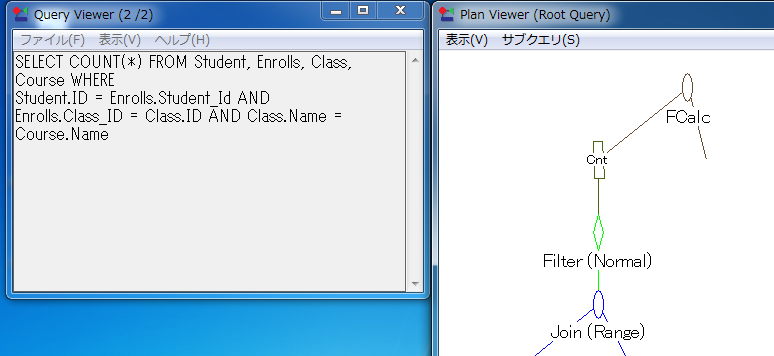
SELECT Student.ID, Class.Name, Course.Credit_Hours FROM Student, Enrolls, Class, Course WHERE Student.ID = Enrolls.Student_Id AND Enrolls.Class_ID = Class.ID AND Class.Name = Course.Name
このクエリは、在籍するすべての学生と、学生が登録している講座、および各コースの履修単位時間を取得します。
4 ZenCC で、クエリ プラン ファイルの名前を
example2.qpf と指定します。
Query Plan の設定を参照してください。
5 ZenCC で、Demodata データベースに対して次のクエリを実行します。
CREATE INDEX ClassID ON Enrolls(Class_ID)
6 ZenCC で、Demodata データベースに対して次のクエリを実行します。
SELECT Student.ID, Class.Name, Course.Credit_Hours FROM Student, Enrolls, Class, Course WHERE Student.ID = Enrolls.Student_Id AND Enrolls.Class_ID = Class.ID AND Class.Name = Course.Name
クエリの実行が速くなったことに気付いてください。
クエリ プランの例を表示する
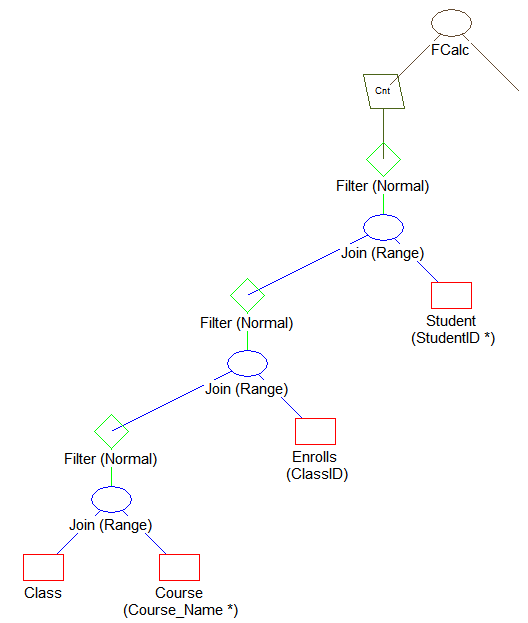
Query Plan Viewer で、[ファイル]>[開く]を使用して example1.qpf() を開きます。次のようなものが表示されます。
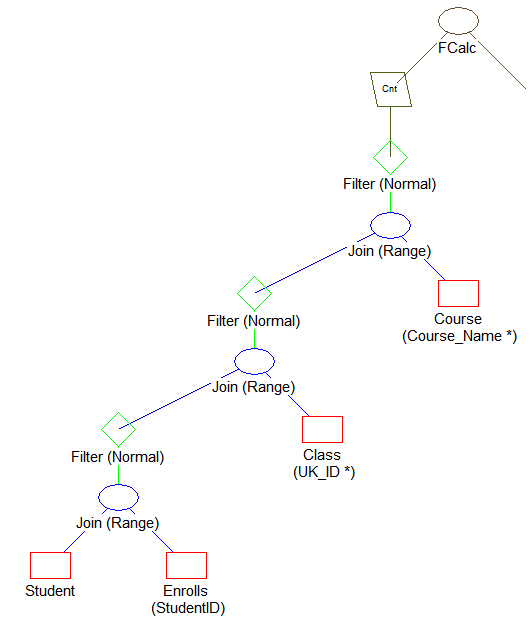
比較のために、Query Plan Viewer で example2.qpf を開きます。次のようなものが表示されます。
このプランについて、次の点に注目してください。
•Class テーブルからレコードがスキャンされます。
•Course.Course_Name インデックスを使用する Class.Name 値に基づいて、Course テーブルからレコードが取得されます。
•Class.ID 値を基に Enrolls テーブルをスキャンして、Enrolls テーブルからレコードが取得されます。
•Student.ID インデックスを使用して、Enrolls.Student_Id 値を基に Student テーブルからレコードが取得されます。
•Enrolls からのデータの選択には、新しく作成されたインデックス ClassID を使用します。
この例と同じように自分で作成したクエリを比較すれば、どのような構文および構造が自分の要求に適合しているかを判断することができます。